Unified Process Monitoring

Did you ever have a slow query, export or any other operation and wondered “Is this ever going to finish?!”. Many operations such as SPARQL queries, db backups etc have performance characteristics which may be hard to predict. Canceling rogue queries was always possible, but there was not yet a way to do so for other potentially expensive operations.
If this ever affected you then the new unified process monitoring feature we added in Stardog 8.1 is meant for you! Monitoring a complex database system is important for any production system at any scale. With the new unified process monitoring feature it is now possible to get a clear picture of all ongoing operations in a Stardog database. A process here refers to a long running, usually user initiated operation within the Stardog server not a Unix system process or thread. Many types of Stardog processes exist: such as backup, restore, logical exports or database creation. These also may report their progress, which can be checked via a CLI command or the API. Progress monitoring works on a single server as well as in the Stardog Cluster.
Process management includes support for:
- listing running processes;
- terminating running processes;
- reading the status of a running process;
To see all running processes from the command line, one may use the ps list command:
$ stardog-admin ps list
The results are formatted tabularly, adding the -a option will even show you internal storage engine processes. Internal processes are created automatically by the components such as the storage engine. They may not be cancelled.
+---------------------------------------------+-------------+-------+-------------------+--------------+-------------+----------------------+
| Process ID | Database | User | Type | Elapsed time | Status | Progress |
+---------------------------------------------+-------------+-------+-------------------+--------------+-------------+----------------------+
| 8cc95209-a649-4e36-aa6c-a5a9a72832e7 | myDatabase | admin | Transaction | 00:03:15.672 | Terminating | N/A |
| internal-DatabaseCreation-admin-myDatabase2 | myDatabase2 | admin | Database Creation | 00:00:12.074 | Running | Parsing data (65.8%) |
+---------------------------------------------+-------------+-------+-------------------+--------------+-------------+----------------------+
Internals: Aborting Processes Cleanly
Aborting a running process can have many different motivations. Usually one misjudged the runtime or operational load of the process. Classic examples is poorly optimized query as well as a larger database import. Another reason might just be that the server will be taken down for maintenance.
Any process which is aborted must leave the system in a clean state. Aborting the process must either lead to a system where the process finished completely, or the process aborted cleanly without leaving a trace. This is fairly easy to accomplish for processes which do not modify any state like read-only transactions, queries or a data export.
For a process like stardog-admin db create -n mydb -- largefile.ttl which mutates the database state, it is much trickier. A database creation operation will spawn many threads, create temporary files and RocksDB column families. All of this needs to be cleaned up if something goes wrong or if the user asynchronously cancels the process.
Stardog Server implements a system of cancellation signals. Each process will create a Cancellation Point (CP) containing an atomic flag which indicates a process should stop. The reason for the cancellation may also be stored. A process performing a resource intensive operation over an extended period of time needs to periodically check the cancellation point. It can then stop the computation and generate an exception or other error message which reflects what happened.
Each Cancellation Point is registered globally in a registry class, organized per logical database. Each process is responsible for terminating itsef and is responsible for closing and unregistering the CP it is using at the end of its lifecycle. Killing a process will merely set the cancellation flag. The CLI will show the TERMINATING status message until the process removes the CP. Stopping the server will cause all CPs to be cancelled. The manager will then wait until all CPs are closed.
Overall this results in a cooperative system which does not forcibly stop or destroy any process or threads. Meaning any process should have the opportunity to clean-up itself. Of course that means that Stardog’s engineers need to be quite careful to not introduce any non-interruptible loops or blocking IO calls.
We faced some engineering challenges at the edge of our systems, namely:
- When interacting with the storage system by
- Spilling data to disk
- Writing larger amounts of data into Rocksdb SST files
- Running manual compaction operations on stored data
- When using networked IO to interact with remote systems
- Running queries against remote endpoints which would block on network IO
- Fetching data from cache nodes
Testing
Properly implementing cancellation is similar to handling unexpected errors, so adding tests for cancellation improved our test coverage of these operations. Cancelling a process involves always at least two independent threads where the cancellation signal is always received asynchronously by the main process thread. Some type of processes may also spawn several worker threads to process data in parallel. Getting the handling of the cancellation signal right is therefore not trivial in many cases.
There are types of processes where we can easily control the duration of the process vs those where we cannot. Queries for example can be made to pause indefinitely by employing a special service for that purpose. Another testing method we employ is to supply infinite data-source inputs to some operations. This can be used for data imports as well as transactions. Then we can just eventually cancel the process after a random amount of time, allowing us to catch any errors.
Some processes are very short-lived. E.g. a db export may finish in milliseconds given a small dataset. Reliably testing the cancellation logic can be tricky because tests may easily become flaky if we do not account for this. “Catching” these processes to kill them is tricky, so we usually execute these sort of operations in a loop and attempt to kill the process. These sorts of tests are successful if the operation was cancelled cleanly and the Stardog server is still consistent & operational.
Testing in the Stardog High-Availability Cluster has some unique challenges. Some types of process operations are replicated to other cluster nodes, those include:
- Transactions
- Database Creation + Import
- Database Drop
- Restoring a database (From cloud based backups)
Processes need to be cancelled on all nodes at the same time. The node which receives the kill command will replicate it to all other participating nodes int the cluster. Testing for these operations faces the same challenge as in the single node. For transactions we also need to forward the kill request to the Cluster coordinator node. Only the transaction coordinator may decide whether a transaction is still cancelable or not. Otherwise the consistency of the cluster could be compromised.
Conclusion
The Unified Process Monitoring can be a helpful tool for many Stardog server power users and administrators. It will provide better insights about the performance of the Stardog server. Monitoring may help you to identify troublesome queries and by extensions allows you to identify the application which started them.
We are continually working on improving this API so that in the future more live information can be added to processes.
Image Attribution: Arrows icons created by Pixel perfect - Flaticon, Anti virus software icons created by Freepik - Flaticon
Keep Reading:

Chaos Testing Stardog Cluster for Fun and Profit
At Stardog we work hard to build software that’s not only performant but also extremely robust. Stardog Cluster is a highly available, key component to ensuring Stardog remains up and running for our customers. However, every distributed system is susceptible to faults and bugs wreaking havoc on it. Most software testing checks the “happy path” through the code to verify it behaves as designed. Moving a step further, tests can check some obvious failure cases; for example, if one service in a deployment is terminated.
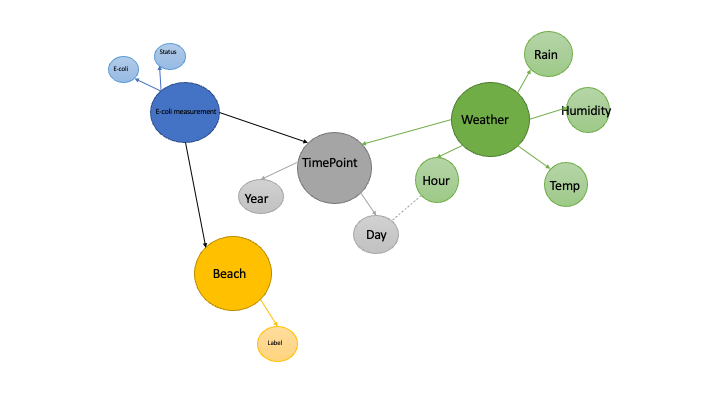
Knowledge Graphs for Data Science - Part 1
A database, equipped with an optimized query language, is a powerful tool in the data science toolkit. We’ve all written our share of SQL queries to create data summaries, perform exploratory analyses, check for null values and other basic tasks. When data weigh in at over 1GB, the best approach is often pairing a good database, for basic data munging, with an analytic platform like R or Python for more nuanced calculations.
Try Stardog Free
Stardog is available for free for your academic and research projects! Get started today.
Download now