Querying Heterogeneous Federations with Stardog 9 Up to 30x Faster

In many companies data is spread over a variety of sources in different departments and many business cases require accessing and analyzing this data in an integrated manner. Federated queries in SPARQL allow users to query multiple data sources as a unified Knowledge Graph. In Stardog, federated query processing is not limited to SPARQL endpoints as data sources but provides means to access data from a variety of services including Virtual Graphs (VGs) backed by a variety of data sources including SQL or NoSQL databases or other stardog servers. There are also cached VGs, Stored Query Service, and Sampling Service. Therefore, the federated querying capability in the Stardog Platform is a powerful tool to unleash insight from data integrated over multiple, heterogeneous data sources. In this blog post, we provide a brief introduction to federated query processing and provide details on how we improved the performance of querying federations of local databases and (cached) Virtual Graphs in Stardog 9.
Motivating example
Consider for example the following setting based on the Berlin SPARQL Benchmark (BSBM) which simulates an e-commerce usecase. This setting consists of data about products, reviews, and offers. In contrast to the original benchmark, let us assume the data is accessible through a federation of three data sources: a local Stardog database for products and two virtual graphs for offers and reviews whose data is potentially stored in different SQL databases. Answering common business questions requires combining data from these data sources. For example, let’s assume we want to retrieve the names of all vendors that sell products of a specific type using the following SPARQL query:
SELECT ?productName ?vendorName
WHERE {
?product a bsbm-inst:ProductType279 .
?product rdfs:label ?productName .
?offer bsbm:product ?product .
?offer bsbm:vendor ?vendor .
?vendor rdfs:label ?vendorName .
}
If all the relevant data was located in a single local Stardog database, we could directly execute this query over the database to retrieve the desired results. However, since multiple data sources contribute to the results of the query, additional steps are necessary to retrieve the results: (i) source selection, (ii) query decomposition, and (iii) join-ordering and operator selection.
Source selection and query decomposition
Source selection refers to identifying the sources which provide solutions to a pattern in the query. In Stardog we can use GRAPH keyword to manually indicate which patterns should be evaluated over which local or Virtual Graph. In our example query, we can indicate that the vendor-related data (i.e., the last three triple patterns) is located in the offers VG for each pattern:
SELECT ?productName ?vendorName
WHERE {
?product a bsbm-inst:ProductType279 .
?product rdfs:label ?productName .
GRAPH <virtual://offers> {
?offer bsbm:product ?product .
}
GRAPH <virtual://offers> {
?offer bsbm:vendor ?vendor .
}
GRAPH <virtual://offers> {
?vendor rdfs:label ?vendorName .
}
}
The provided query retrieves the expected results but it is also quite verbose. This is where the concept of federated query decomposition comes into play. The goal of a query decomposition is grouping patterns of a query such that they can be jointly evaluated at a remote source without compromising on answer completeness. In our example, we can group the vendor-related triple patterns since they only need to be evaluated at a single VG. Thus, we can simplify and rewrite the query as follows
SELECT ?productName ?verndorName
WHERE {
?product a bsbm-inst:ProductType279 .
?product rdfs:label ?productName .
GRAPH <virtual://offers> {
?offer bsbm:product ?product .
?offer bsbm:vendor ?vendor .
?vendor rdfs:label ?vendorName .
}
}
In Stardog 9, we improved the query decompositions approach to automatically determine more efficient query decompositions which reduce the number of requests to remote services including VGs, cached VGs, and other SPARQL services. In addition to combining patterns to the same logical sources, such as a VG, the improved approach also tries to push the query evaluation to physical sources as much as possible. For example, when multiple VGs are cached on the same cache target, we can push the evaluation of queries over multiple VGs completely to the cache target. This improves the performance by reducing the amount of data to be transferred from the cache target. As a result, caching VG not only provides the benefit of full SPARQL expressivity (including Stardog extensions, such as path queries or full-text search) but can also improve the query performance in a federation of VGs.
As an alternative to explicitly indicating relevant sources with the GRAPH keyword, we can also use the Virtual Transparency feature in Stardog. Virtual Transparency allows us to query the local and virtualized data as if it were a single database. That is, we do not need to add explicit GRAPH keywords. Instead, the optimizer in Stardog will automatically perform source selection and query decomposition based on the VG mappings and additional metadata.
We can either enable the Virtual Transparency database option or simply specify in the FROM statement that we want to query all local and virtual graphs:
SELECT ?productName ?vendorName
FROM <tag:stardog:api:context:all>
WHERE {
?product a bsbm-inst:ProductType279 .
?product rdfs:label ?productName .
?offer bsbm:product ?product .
?offer bsbm:vendor ?vendor .
?vendor rdfs:label ?vendorName .
}
With Virtual Transparency enabled, the optimizer in Stardog first determines the relevant sources for each triple pattern in the query based on the mappings for Virtual Graphs and the metadata of the local database.
Thereafter, it tries to prune non-contributing sources. A non-contributing source is a relevant source (i.e., provides solutions to a pattern) but those solutions are not part of the final results of the query.
In our example query, the offers VG is a relevant source for the triple pattern ?product rdfs:label ?productName . since the rdfs:label predicate is used in one of its mappings.
However, the offers VG is a non-contributing source for this pattern because none of the solutions from this source are compatible (i.e., join) with solutions the pattern ?product a bsbm-inst:ProductType279 ..
While this was explicitly defined in the query with manually selected sources, Virtual Transparency requires the optimizer to identify non-contributing sources to determine efficient query decompositions.
In Stardog 9, we improved the optimizer to produce more efficient decompositions with Virtual Transparency enabled. Especially for cached VGs, we improved the pruning of non-contributing sources based on the VG mappings and the way patterns are jointly evaluated at the remote sources. Let’s assume we enable Virtual Transparency for our example query and execute it over a federation with cached VGs. The corresponding query plan in Stardog 8 looks as follows:
Projection(?productName, ?vendorName) [#1.9M]
`─ HashJoin(?product) [#1.9M]
+─ HashJoin(?offer) [#360K]
│ +─ HashJoin(?vendor) [#60K]
│ │ +─ Union [#360K]
│ │ │ +─ Union [#350K]
│ │ │ │ +─ Scan[PSOC](?vendor, rdfs:label, ?vendorName) [#340K]
│ │ │ │ `─ Service <http://.../stardog-cache/query> {
│ │ │ │ +─ Scan[SPO](?vendor, rdfs:label, ?vendorName){<cache://offers>, Named}
│ │ │ │ } [#10K]
│ │ │ `─ Service <http://.../stardog-cache/query> {
│ │ │ +─ Scan[SPO](?vendor, rdfs:label, ?vendorName){<cache://reviews>, Named}
│ │ │ } [#10K]
│ │ `─ Union [#20K]
│ │ +─ Service <http://.../stardog-cache/query> {
│ │ │ +─ Scan[SPO](?offer, <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/vocabulary/vendor>, ?vendor){<cache://offers>, Named}
│ │ │ } [#10K]
│ │ `─ Service <http://.../stardog-cache/query> {
│ │ +─ Scan[SPO](?offer, <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/vocabulary/vendor>, ?vendor){<cache://reviews>, Named}
│ │ } [#10K]
│ `─ HashJoin(?product) [#60K]
│ +─ Union [#360K]
│ │ +─ Union [#350K]
│ │ │ +─ Scan[POSC](?product, rdfs:label, ?productName) [#340K]
│ │ │ `─ Service <http://.../stardog-cache/query> {
│ │ │ +─ Scan[SPO](?product, rdfs:label, ?productName){<cache://offers>, Named}
│ │ │ } [#10K]
│ │ `─ Service <http://.../stardog-cache/query> {
│ │ +─ Scan[SPO](?product, rdfs:label, ?productName){<cache://reviews>, Named}
│ │ } [#10K]
│ `─ Union [#20K]
│ +─ Service <http://.../stardog-cache/query> {
│ │ +─ Scan[SPO](?offer, <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/vocabulary/product>, ?product){<cache://offers>, Named}
│ │ } [#10K]
│ `─ Service <http://.../stardog-cache/query> {
│ +─ Scan[SPO](?offer, <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/vocabulary/product>, ?product){<cache://reviews>, Named}
│ } [#10K]
`─ Union [#21K]
+─ Union [#11K]
│ +─ Scan[POSC](?product, <http://www.w3.org/1999/02/22-rdf-syntax-ns#type>, bsbm-inst:ProductType279) [#870]
│ `─ Service <http://.../stardog-cache/query> {
│ +─ Scan[SPO](?product, rdf:type, <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/instances/ProductType279>){<cache://offers>, Named}
│ } [#10K]
`─ Service <http://.../stardog-cache/query> {
+─ Scan[SPO](?product, rdf:type, <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/instances/ProductType279>){<cache://reviews>, Named}
} [#10K]
While the plan for the same query in Stardog 9 is
Projection(?productName, ?vendorName) [#620]
`─ ServiceJoin [#620]
+─ Service <http://.../stardog-cache/query> {
│ +─ {
│ +─ `─ Scan[SPO](?offer, <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/vocabulary/product>, ?product){<cache://offers>, Named}
│ +─ `─ Scan[SPO](?offer, <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/vocabulary/vendor>, ?vendor){<cache://offers>, Named}
│ +─ `─ Scan[SPO](?vendor, rdfs:label, ?vendorName){<cache://offers>, Named}
│ +─ }
│ } [#5.6M]
`─ MergeJoin(?product) [#620]
+─ Scan[POSC](?product, <http://www.w3.org/1999/02/22-rdf-syntax-ns#type>, bsbm-inst:ProductType279) [#620]
`─ Scan[PSOC](?product, rdfs:label, ?productName) [#340K]
As the query plans show, the improved query decomposition approach identifies non-contributing sources more accurately and groups patterns into larger sub-expressions that are jointly evaluated at the cached VG. As a result, fewer remote data sources need to be contacted and fewer data need to be transferred. Source selection and query decomposition determine where parts of a federated query should be evaluated. As a next step, the optimizer also needs to determine how to compute the results efficiently.
Join-ordering and operator selection
The key tasks to finding an efficient query plan are join-ordering and selecting the appropriate physical operators. Both tasks rely on accurate cardinality estimations. For local databases, the optimizer can access pre-computed statistics and data summaries to accurately estimate the (join) cardinalities of the patterns in a query. However, for remote data sources, the optimizer cannot rely on such fine-grained statistics. In Stardog 9, we focussed on improving the (join) cardinality estimation approach for VGs and cached VGs. For cached VGs (or any other Stardog-backed SPARQL service), we leverage Stardog’s explain endpoint to obtain the cardinality estimations from the remote source. For VGs on top of SQL databases (such as MySQL or even Databricks clusters) we obtain row counts for relevant tables and use Foreign Key constraints to get some idea about join cardinality.
With the improved estimations, we also refined our cost model. Typically, in a federated setting the main cost factor is the number of requests to remote sources, the cost of processing a request at the source, and the amount of data to be transferred per request. Therefore, we refined our cost model to better reflect this cost based on the cardinality estimation. This leads to a better selection of physical join operators. Let’s revisit our motivating example and see how this impacts the query plans over the federation with cached VGs. We disable Virtual Transparency and query the federation with cached VGs. The query plan in Stardog 8 looks as follows.
`─ MergeJoin(?product) [#140K]
+─ MergeJoin(?product) [#2.3K]
│ +─ Scan[POSC](?product, <http://www.w3.org/1999/02/22-rdf-syntax-ns#type>, bsbm-inst:ProductType279) [#870]
│ `─ Scan[PSOC](?product, rdfs:label, ?productName) [#340K]
`─ Sort(?product) [#10K]
`─ Service <http://.../stardog-cache/query> {
+─ {
+─ `─ Scan[SPO](?offer, <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/vocabulary/vendor>, ?_anon_1){<cache://offers>, Named}
+─ `─ Scan[SPO](?offer, <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/vocabulary/product>, ?product){<cache://offers>, Named}
+─ `─ Scan[SPO](?_anon_1, rdfs:label, ?verndorName){<cache://offers>, Named}
+─ }
} [#10K]
There are two main issues to highlight in this query plan. First, the cardinality estimation [#10K] for the pattern evaluated over the cached VG is a very rough, inaccurate estimate. In reality, the pattern produces almost 5.7M results. Second, due to this misestimation, the optimizer opts for a suboptimal join order and selects a MergeJoin as the physical join operator.
This is very inefficient as it requires transferring all 5.7M solutions from the cached VG to the local database, sorting all solutions, and then joining the solutions with the local solutions (which are only a couple of thousands).
In contrast, in Stardog 9, the optimizer benefits from more accurate cardinality estimations for the cached VG and therefore can select the ServiceJoin operator as a more appropriate physical operator. Instead of retrieving all solutions from the cached VG, the ServiceJoin operator probes solutions from the more selective local pattern at the cached VG and therefore, only retrieves solutions that are compatible with the local solutions. The corresponding query plan looks as follows and retrieves the ~12K solutions within a few seconds:
Projection(?productName, ?verndorName) [#620]
`─ ServiceJoin [#620]
+─ Service <http://.../stardog-cache/query> {
│ +─ {
│ +─ `─ Scan[SPO](?offer, <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/vocabulary/product>, ?product){<cache://offers>, Named}
│ +─ `─ Scan[SPO](?offer, <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/vocabulary/vendor>, ?_anon_1){<cache://offers>, Named}
│ +─ `─ Scan[SPO](?_anon_1, rdfs:label, ?verndorName){<cache://offers>, Named}
│ +─ }
│ } [#5.6M]
`─ MergeJoin(?product) [#620]
+─ Scan[POSC](?product, <http://www.w3.org/1999/02/22-rdf-syntax-ns#type>, bsbm-inst:ProductType279) [#620]
`─ Scan[PSOC](?product, rdfs:label, ?productName) [#340K]
Benchmarking
After providing a brief introduction to federated query processing and highlighting some major improvements in Stardog 9, we now want to present and discuss how we evaluate these changes using our new federated benchmark.
Dataset and setup
As previously mentioned, we used the BSBM dataset and split it into three different partitions (products, reviews, and offers) and distribute the data at different sources. In our current evaluation, we focus on two main setups shown in the figure below.
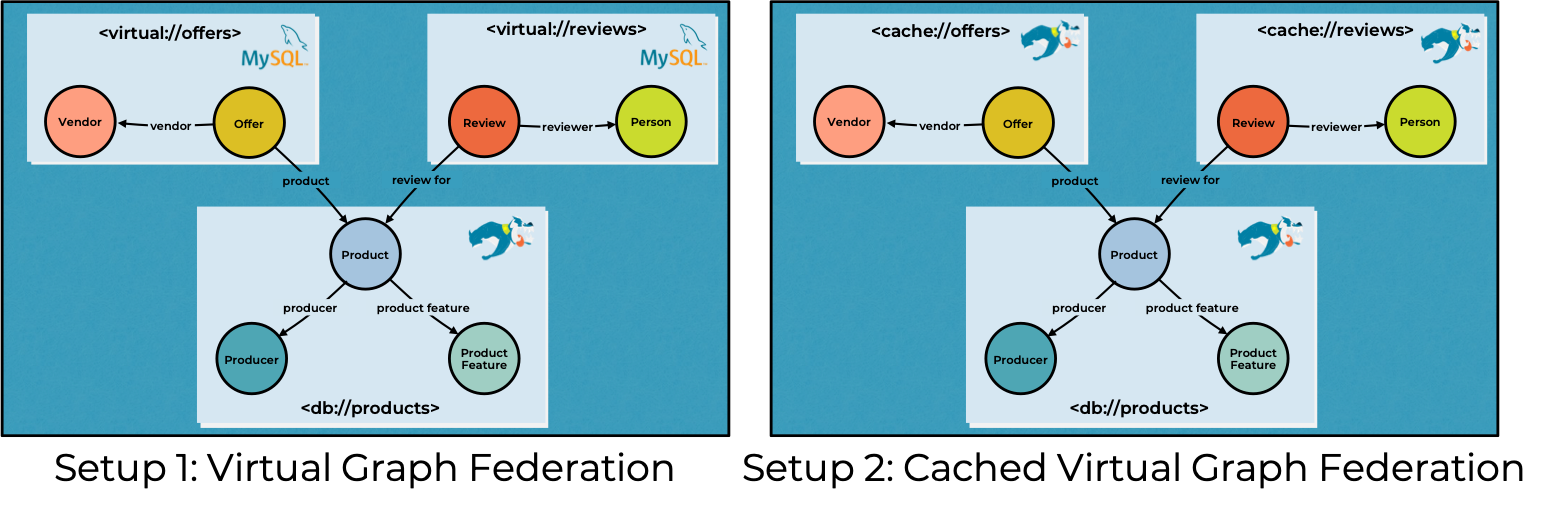
For the first setup, we use Virtual Graphs with relational data sources (MySQL) for the offer and review partitions. The product data is loaded in a local Product Stardog database. The VGs are accessible from the Product database over which we execute the queries. In the second setup, we create caches for the review and offer VGs.
Queries
For our evaluation, we created a set of custom federated query templates which are based on the twelve original BSBM queries. In contrast to the original queries, our federated queries are all SELECT queries which include less selective sub-queries and combine data from at least two of the three data partitions. The rationale for these adaptations is to reflect possible use cases in federated settings and to make the queries more challenging for our optimizer. For example, the following query (query 10) retrieves the top-10 cheapest offers for products produced and sold in the US that fulfill certain criteria (regarding review ratings, offer data, and delivery time).
# Query 10
SELECT DISTINCT ?offer ?price
WHERE {
?product bsbm:producer [ bsbm:country ctr:US ] .
GRAPH <virtual://reviews> {
?review bsbm:reviewFor ?product ;
bsbm:rating4 ?rating4 ;
bsbm:rating3 ?rating3 .
FILTER (?rating3 < 3 && ?rating4 < 3)
}
GRAPH <virtual://offers> {
?offer bsbm:product ?product ;
bsbm:vendor [ bsbm:country ctr:US ] ;
bsbm:price ?price ;
bsbm:validTo ?date ;
bsbm:deliveryDays ?deliveryDays .
FILTER (?deliveryDays <= 3 && ?date > "2008-06-20T00:00:00"^^xsd:dateTime )
}
}
ORDER BY ?price
LIMIT 10
In addition to queries with explicit source selection, we also tested the same queries without the GRAPH statements using Virtual Transparency. Next, we discuss some of our findings from benchmarking Stardog 8 and Stardog 9 using this benchmark.
Results
A key observation from our evaluation is the substantial performance gains in both setups with and without Virtual Transparency. In Stardog 8, multiple queries exceeded the specified timeout of 5 minutes, especially with Virtual Transparency enabled. In contrast, in Stardog 9 all queries in both setups with and without Virtual Transparency produced the complete results in less than 30 seconds on average. To highlight some improvements, we pick two queries from our benchmark (10 and 12) and discuss their performance in more detail. First, let’s take a closer look at the performance results for the previously shown query 10.

The barplot on the left shows the query execution times without Virtual Transparency. The results show that in Stardog 9 the query is executed over the VG federation (Setup 1) almost 3.5 times faster than in Stardog 8. While the execution of the query over the cached VG federation (Setup 2) is slightly slower in Stardog 9 (~ 2s on average), it is still more than 2 times faster than in Stardog 8. Next, we focus on the results with Virtual Transparency enabled on the right. We can observe that while these queries reach the timeout in both setups in Stardog 8, the query execution times in Stardog 9 are on par with those without Virtual Transparency.
Note: in this particular experimental setup, VG caches are hosted on the same server as the corresponding MySQL databases. Also the MySQL server is not under any load other than SQL queries which correspond to offer and review SPARQL patterns. In realistic deployment scenarios VG caches bring most benefits when they reduce load on the upstream system (which is typically also used by legacy applications) and allow moving data closer to Stardog server nodes with faster network access.
Next, we take a closer look at the results for query 12. The query combines data from the product database and the offers VG: find offers valid until a given date for a specific type of product:
SELECT *
WHERE {
?product a bsbm-inst:ProductType17 ;
rdfs:label ?productlabel .
GRAPH <virtual://offers> {
?Offer bsbm:product ?product ;
bsbm:vendor [ rdfs:label ?vendorname ;
foaf:homepage ?homepage ];
bsbm:offerWebpage ?offerURL ;
bsbm:price ?price ;
bsbm:deliveryDays ?deliveryDays ;
bsbm:validTo ?validTo .
FILTER (?validTo < "2008-06-20T00:00:00"^^xsd:dateTime)
}
}
The following figure shows the performance results for query 12.

Comparing the results without Virtual Transparency on the left, we again find substantial improvements in Stardog 9. The query is executed about 30 % faster over the VG federation (Setup 1) and almost 30 times faster with cached VGs (note the log-scale for the execution time). The results with Virtual Transparency show a similar picture as with query 10. In both setups, the queries in Stardog 8 reach the timeout. In contrast, the queries are executed within a similar time in Stardog 9.
Limitations and next steps
The evaluation with our new federated benchmark shows that we made significant improvements for query processing over heterogeneous federations. Still, there are further improvements in this area on our roadmap. For instance, one challenge is the fact that the query plans will only be as good as the cardinality estimations from remote sources. Especially for Virtual Graphs, it can be challenging to get accurate estimations and we rely on the statistics provided by the data source. Therefore, we are working on new adaptive operators which can adapt to sub-optimal query plans during query execution to avoid degrading performance for such queries. Moreover, in Stardog 9, we introduce a new optional feature that will prefetch solutions from VGs during query planning to avoid substantial under-estimations. Lastly, we extended the support of cardinality hints to SERVICE patterns in queries such that query plans can be manually fine-tuned for best performance. For more details, check out our documentation.
Conclusion
The federation extension in SPARQL and Virtual Graph capability in Stardog are useful features to query and integrate data residing in multiple heterogenous sources. Processing federated queries efficiently over local and remote data sources is a challenging task that requires refinements in the multiple areas of the Stardog query optimizer.
With Stardog 9, we improved our optimizer to query federations of local databases and remote data sources including Virtual Graphs (VGs), cached VGs, and other SPARQL-Endpoints more efficiently. This includes (i) improved source selection and query decomposition, (ii) obtaining cardinality estimations from Stardog-backed SPARQL services, (iii) and refining our cost model and physical operator selection. The results of our new federated benchmark showed substantial improvements in Stardog 9 over the previous versions. At the same time, the analysis of the results helped us to identify limitations and shortcomings which we will address in future releases.
Try Stardog 9.0 today and give us feedback on Stardog Community!
Keep Reading:
Try Stardog Free
Stardog is available for free for your academic and research projects! Get started today.
Download now