Robust Query Planning for Federated Queries

In our previous blog post, we discussed some of the challenges when it comes to querying heterogeneous federations. In this blog post, we want to focus specifically on the challenge of estimating the number of (intermediate) results in federated settings and present our new robust query planning feature to address this challenge.
In federations with Virtual Graphs, SPARQL endpoints, or other remote sources, it is difficult to estimate the number of results (i.e., the cardinality) of patterns evaluated at remote sources as well as estimate the number of results of joins between remote and remote or local patterns. This is because Stardog has to rely on the metadata exposed by the remote sources and it is difficult to assess how the remote data joins with other remote or local data. Not only does the granularity of the metadata differ based on the data source type, but also updates to the data in remote sources can lead to the statistics kept by Stardog becoming stale. To this end, the query planner relies on a set of heuristics to estimate cardinalities and derives the cost of the query plan based on these estimates. Still, inaccurate estimations are unavoidable as those heuristics rely on certain assumptions about the data distribution. Especially when querying remote data sources, estimation errors can lead to very inefficient query plans.
Robust Query Optimization is a concept to minimize the impact of inaccurate cardinality estimations. The topic has been broadly studied in the literature [1]. The methods in this area of research range from approaches that try to learn better estimates from previous query executions over methods that re-trigger the query optimization if estimation errors are detected during runtime to methods that aim to select a robust query plan before execution. In this blog post, we will focus on the latter and present the new Robust Query Planning feature which is introduced in Stardog 10.
Robust Query Planning in Stardog 10
With Stardog 10, we introduce a robust query optimization strategy that takes the uncertainty in the presence of remote data sources, such as Virtual Graphs (VGs), during the query planning process into account. Instead of trying to find the optimal query plan, the new robust query planning approach aims at determining a query plan that is also robust. In this context, robustness can be understood as the degree to which the query performance degrades in the presence of adversity. In particular, our robust query planning approach tries to determine query plans that are robust with respect to cardinality estimation errors. The approach is inspired by previous research in this area [2,3] and has been refined to meet the requirements and constraints in Stardog.
What Makes a Query Plan Robust?
In traditional cost-based query optimization, the expected execution time of a query plan is estimated using a cost model. The cost model takes a (physical) query plan with the cardinality estimations as an input and returns a single cost value. The cheapest plan is expected to be the fastest assuming the cardinality estimations are accurate.
In our robust query planning approach, we do not compute the single, cheapest query plan but compute a set of candidate query plans and assign multiple alternative cost values to each candidate[4]. To mimic cardinality estimation errors, we compute these cost values by varying the cardinality estimations for a given query plan within reasonable ranges.
Specifically, we vary the cardinality estimations of patterns against remote data sources as well as the estimates for joins with at least one pattern against a remote data source. Changing the cardinality estimations results in different cost values for the same query plan. The impact of varying the estimations on the cost depends on the shape of the query plan as well as its physical operators.
Simply speaking, a query plan is considered to be more robust if the impact on the cost when varying the cardinalities is lower than for another plan (for the same query). That is, the expected performance degradation caused by cardinality estimation errors is lower than for the other query plans. We can therefore use the alternative cost values as a proxy for the robustness of a query plan.
Finally, we use this measure of robustness as an additional decision criterion for deciding which plan should be executed. The chosen query plan is not necessarily the cheapest according to the cost model assuming no cardinality errors but is also sufficiently robust. In practice, there often is a trade-off between the cheapest and the most robust plan. The cheapest plans are typically less robust and vice versa.
Hence, the question arises: how to balance cost and robustness when deciding which query plan should be selected?
Selecting a Robust Query Plan
We borrow ideas from multi-objective optimization and use the concept of scalarized preferences to select the final query plan. By introducing additional cost values, the join order optimization problem turns into a multi-objective optimization problem. As a consequence, this typically means that there is not only a single optimal query plan but a set of Pareto-optimal query plans. Each of those query plans is optimal in the sense that there is no other query plan that is better for all objectives. Since we still need to select a single final query plan to be executed, we need an additional criterion to select one of the Pareto-optimal solutions. For this task, we use a scalarization function that reflects the preferences over the objectives and assigns a single preference value to each query plan. We can then select the query plan that maximizes our preferences as the final query plan. As shown in the figure below, the approach can be separated into three main steps which we outline in the following.
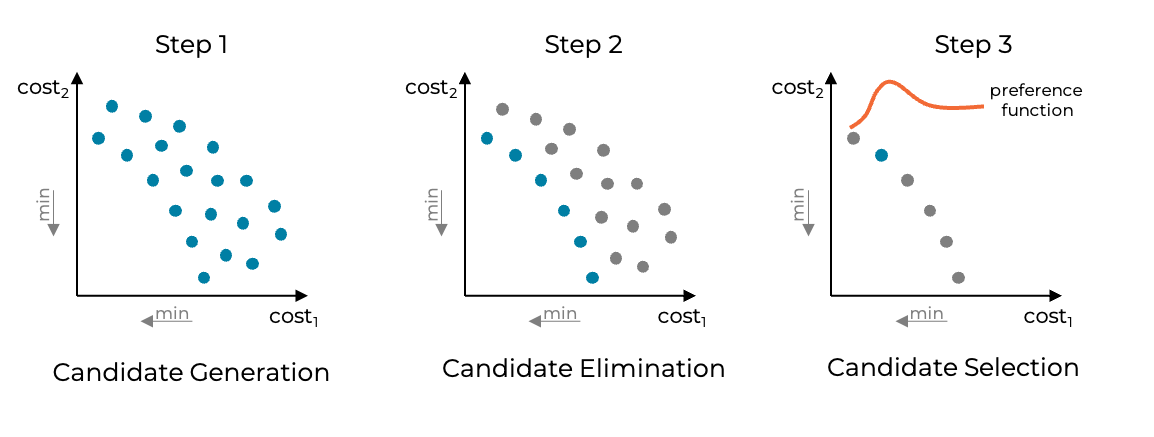
Step 1: Candidate generation
In the first step, we generate a set of k alternative query plans. The goal when generating these plans is two-fold: We want to generate query plans that are not too far off the cheapest query plan but at the same time exhibit a certain degree of variety. In terms of variety, the plans should differ in both the join order as well as in the physical join operators. To achieve this goal, we extended the Stardog join order optimizer to explore additional parts of search space that it would not have considered before. For each plan, we compute both the cost according to our cost model (cost1) as well as an aggregated alternative cost value (cost2). This aggregated cost value combines the alternative costs for different possible cardinality estimation errors into a single value [5]. In the figure, each candidate query plan is plotted according to these two objective function values. The goal is to find a query plan that minimizes both objectives.
Step 2: Candidate elimination
Once the candidate query plans are generated, we determine all non-dominated query plans and eliminate all query plans that are dominated [6]. A query plan is called non-dominated if there exists no other query plan that is better in one objective without being worse in any of the other objectives. In our case, that means we keep a query plan if there does not exist another candidate query plan that is both cheaper and more robust.
Step 3: Candidate selection
In the last step, we select the final query plan to be executed. We use a preference function to assign to each non-dominated query plan a preference value and choose the query plan that maximizes the preference function value. The main requirement for choosing the preference function is that it should exhibit the non-extremeness property. That is, in the presence of a concave Pareto-front, it should not always choose either the cheapest or the most robust query plan (i.e., the extrema of the Pareto-front). Finally, the most preferred query plan is executed.
Configuring Robust Query Planning
The robust query planning feature is enabled by default and can be disabled using the optimizer.join.order.robustness server property. In addition, with the query hint optimizer.join.order.topk, the number of candidate query plans from which the robustness model chooses the plan can be specified. That means, with a value of k = 1, the robust query planning feature can be disabled on a per-query basis. By default, we set k = 20. Note that increasing the number can increase the query optimization time (pre-execution time). Moreover, increasing the number may not always lead to more candidate query plans. This may be the case when the exploration quota is reached before finding k plans or when there are less than k possible query plans.
Performance Evaluation
We saw that a robust query planning approach can be beneficial in various situations and needed a benchmark to evaluate our approach in a structured manner. We therefore developed a new benchmark that is based on the Berlin SPARQL Benchmark (BSBM). In contrast to our previous benchmarks, in this new benchmark, all data is stored in Virtual Graphs, i.e., there is no local data. To additionally challenge the query planner, we split the BSBM dataset into eight subsets, each of which is available as a dedicated VG. The following figure shows the VGs and how the data is connected across VGs.
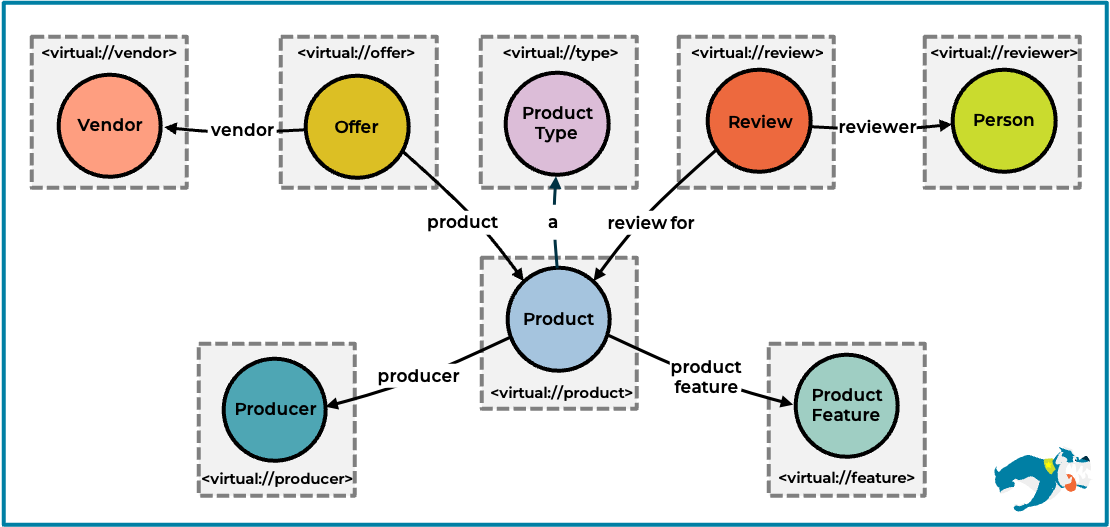
For our evaluation, we used a scale of 100M (virtual) triples and created a set of seven custom federated query templates. These templates are derived from the original BSBM queries and adjusted to fit our setting. The number of VGs for answering those queries varies from two to five VGs with an average of about four VGs per query.
For example, consider query template 3 that retrieves the names of all products of type T with feature F for which there is an offer within the price range P1 and P2 and includes the vendor’s country.
SELECT ?name ?country
{
GRAPH <virtual://product> {
?product rdfs:label ?name .
}
GRAPH <virtual://type> {
?product a %T% .
}
GRAPH <virtual://feature> {
?product bsbm:productFeature %F% .
}
GRAPH <virtual://offer> {
?offer bsbm:product ?product ;
bsbm:vendor ?vendor ;
bsbm:price ?price .
FILTER (?price > %P1% && ?price < %P2% )
}
GRAPH <virtual://vendor> {
?vendor bsbm:country ?country .
}
}
In this example query template, there are five VG patterns for which the cardinality needs to be estimated as well as the the cardinalities of joins between those patterns. Cardinality estimation errors for such queries can lead to inefficient join orders that produce large numbers of intermediate results as well as selecting sub-optimal join algorithms which can lead to a larger number of requests to the remote data sources (see also our previous blog post).
For the sake of simplicity, we set up the benchmark environment on a single machine and ran both Stardog and the relational data source on this machine. We used a MySQL database to load the BSBM data. In Stardog, we created eight Virtual Graphs for the following subsets of data: product, product feature, product type, producer, offer, vendor, review, and person. The majority of subsets correspond to a single table in the database. Only the product type and product feature VGs correspond to two tables.
Evaluation Results
Next, we want to discuss the results of evaluating the robust query planning feature using the new benchmark. The figure below shows the average execution times per query template with and without robust query planning enabled. Note the log scale for the execution times.
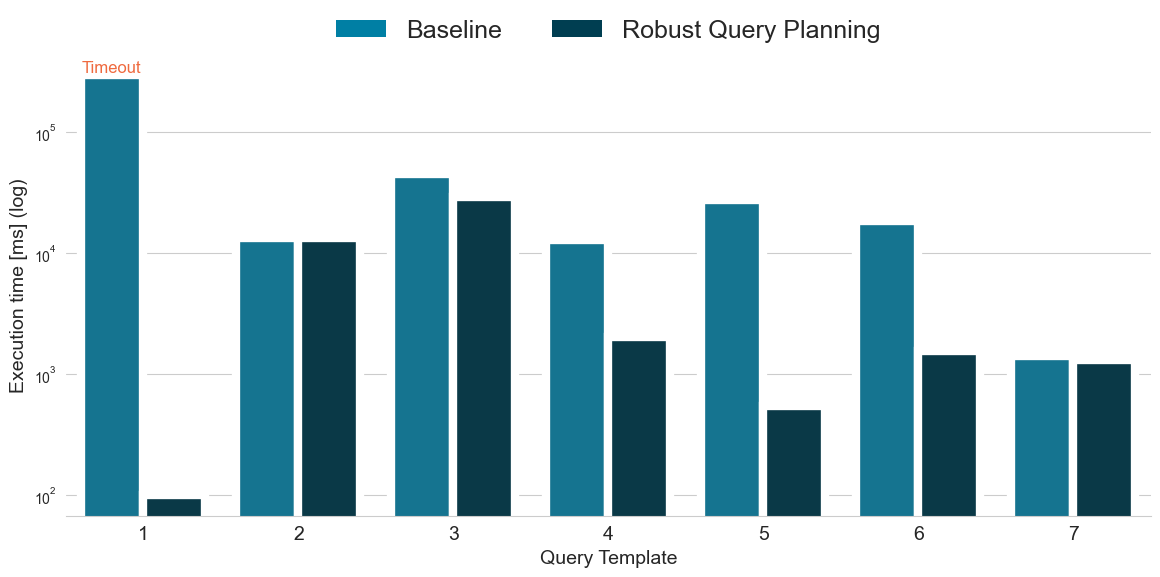
The results show a reduced query execution time for six out of the seven query templates. For query template 2, the query execution times are on par, and for query template 7 there is only a slight benefit of the robust query plans. For the remaining five queries, there is a substantial reduction in query execution time when the feature is enabled. The largest improvement is achieved for query template 1, where the queries reached the timeout of 5 minutes for the baseline. With robust query planning enabled, the queries are executed within 100 ms. On average, the robust query plans are more than 8 times faster than the baseline query plans.
While the evaluation shows an improvement in the query execution times for the majority of the queries, it is important to understand the possible risk of performance degradation with robust query planning. We therefore also evaluate the performance on our other federated benchmark which we introduced previously. The following figure shows for each query template from all benchmarks both the average execution without robust query planning enabled (x-axis) and with it enabled (y-axis). The plot includes the identity line such that the dark blue dots above the line indicate a performance degradation while the light blue dots below the line indicate performance improvements.
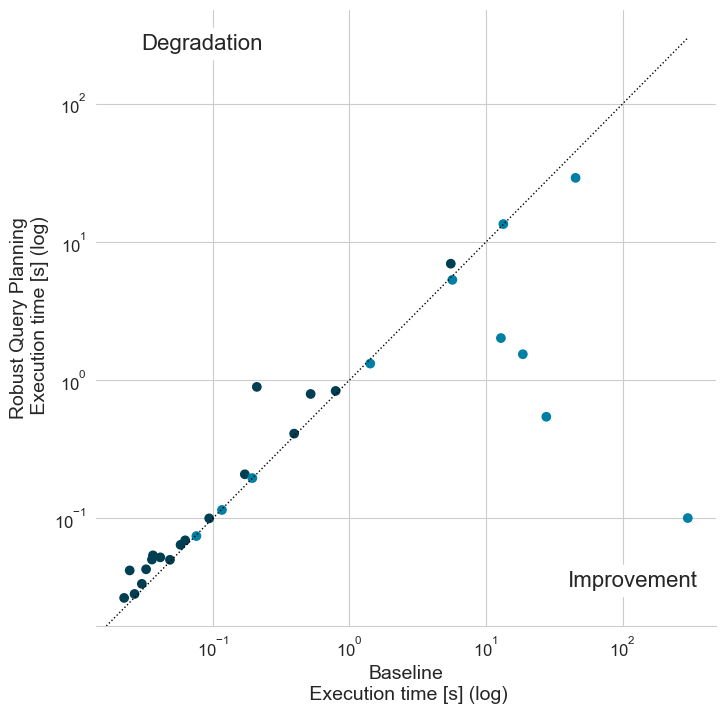
The results show a slight decrease in performance for the majority fast running queries with an execution time below 1 second. At the same time, for longer-running queries, with robust query planning, the performance improves for all but one query. The results show that there is a certain risk associated with choosing a robust query plan over the cheapest plan. Especially, when cardinality estimations are more accurate, the cheapest query plans outperform the robust alternatives. In contrast, the robust query planning approach is more cautious which is rewarded in the presence of less accurate estimation where it can substantially improve query execution times.
Conclusion
In query optimization, we have to accept the fact that cardinality estimation errors are unavoidable. Especially in federations with multiple VGs backed by different data sources, it is challenging to accurately estimate cardinalities. Therefore, it is essential to have guardrails in place to avoid inefficient query plans in such environments.
In this blog post, we presented a new robust query planning feature that acts as a guardrail. By taking possible cardinality estimation errors into account, this new feature aims at finding query plans that are not only cheap but also robust.
The evaluation of our approach revealed substantial performance improvements for the queries in our new benchmark. These queries include up to five Virtual Graph patterns. While the approach can also hurt performance for some queries, the benefits of the robust query planning approach outweigh this potential performance degradation.
In the future, we will further improve our robust query planning approach to reduce performance degradation as well as focus on adaptive query processing strategies to better cope with sub-optimal query plans during query execution. Our goal is to further improve the performance and robustness of the query engine when facing challenging environments with a large degree of uncertainty.
Try Stardog 10.0 today and give us feedback on the Stardog Community!
Footnotes
[1] Yin, Hameurlain, and Morvan, “Robust Query Optimization Methods With Respect to Estimation Errors: A Survey.”
[2] Heling, Acosta, “Cost- and Robustness-Based Query Optimization for Linked Data Fragments.”
[3] Heling, Acosta, “Robust query processing for linked data fragments.”
[4] For the sake of readability, we use the generic term query plan in the following. Technically, we apply the robust query planning approach on each group graph pattern in the query which contains a graph/service pattern to a remote source (VG, cached VG, SPARQL endpoint, or another DB).
[5] In principle, each alternative cost value could be considered an objective. We opted for aggregating them first since it facilitates the definition and interpretability of the preference function.
[6] Note that since the query plan search space is not explored exhaustively, we might not find truly Pareto-optimal solutions.
Keep Reading:
Try Stardog Free
Stardog is available for free for your academic and research projects! Get started today.
Download now