Introducing Stardog Labs

I’m delighted to welcome you to Stardog Labs, a new hub of insight, news, and buzz about knowledge graph technology. The site will advance knowledge graph R&D by featuring technical blogs, showcasing job opportunities focused on knowledge graph development, and curating research papers and open source projects.
While Stardog Labs will serve as our Engineering blog, it’s also designed for participation from our community of Stardog users, academic researchers, and knowledge graph enthusiasts.
A place for knowledge graph research
Of course as Stardog’s CEO, I’m eager to see adoption of knowledge graph technology — from using graph embeddings for a computer vision scene library to creating control systems in IoT environments. As this space continues to advance, we wanted to create a space to push knowledge graph development even further, not least given where we came from.
I met Mike and Evren, my two cofounders-to-be in 2003, at the first semantic technology research lab in the US, at the University of Maryland. CTO Evren Sirin was a PhD student at the lab, doing fundamental research into description logics, automated reasoning systems, and large-scale data integration. SVP Engineering & Product Mike Grove was a staff programmer, hacking systems and prototypes in graph data management, autonomous computing, and location-aware service integration. I was a staff researcher, kibbitzing on research papers, and helping build a family of interoperable web standards. I chaired the working group that created SPARQL, back in 2006, and edited the SPARQL Protocol spec, too.
For some years, we ran a knowledge graph services firm, helping companies and organizations like NASA make better decisions with their data by overcoming the challenges imposed by their internal data silos. Working with W3C standards, we developed Stardog, initially around a bespoke graph database. By 2015, we realized the potential to bring a fully featured Enterprise Knowledge Graph platform to market and founded Stardog Union, the company, with the mission to connect data to improve decision making and transform businesses.
Today, we are fully engaged in creating a better future where the largest organizations on the planet consistently make data-driven decisions because they’ve come to terms with their diverse, hybrid, and rapidly changing data. Our goal is a world where data actually is the strategic asset that we all want want it to be, at acceptable levels of investment, since we believe that will tend toward social betterment. In other words, a world where big orgs make data-driven decisions because they can because they can afford to.
To accomplish this goal we engage in a wide variety of tasks, not least of which is research and development in graph-based data management, knowledge representation, and other parts of AI. Which is just to say that in some real sense proper science is part of the Stardog story — always has been, always will be.
What will Stardog Labs be?
As I said at the outset, the Stardog Labs site will be one of the places where Stardog Engineering puts its mark on the flow of public discourse about knowledge graphs. That mark will include, initially, the following areas:
- blogs about relevant R&D topics from Stardog Engineering
- job listings in knowledge graph development
- curated R&D papers from the academic research community
- open-source projects and experimental Stardog development
Get involved
While we are an interested party in the connected data future, we’re only part of the story. The great work being done by the global academic research community — including many friends, partners, and former colleagues — is the inspiration behind Stardog Labs. We invite you to tell the story of your work, its impact, and what is coming next. We’ve already jumpstarted that with a guest blog post by Bram Steenwinckel of the University of Ghent about stream reasoning and we hope there will be many more contributions coming soon.
If you’re a researcher in any of the areas I’ve talked about, please get in touch and let’s figure out the best way for us to highlight your work on Stardog Labs. If you’re looking to hire knowledge graph talent, please ping us so we can feature your job listing on Stardog Labs. And if you’d like to use Stardog for your research, I’d be remiss not to remind you of our 1-year full-featured Academic Trial.
The momentum for knowledge graph technology that we see everywhere is based, in part, on lots of R&D and we’re happy to coalesce the community around applying that work to data-driven decision making in the world’s largest organizations. Come join us!
Keep Reading:
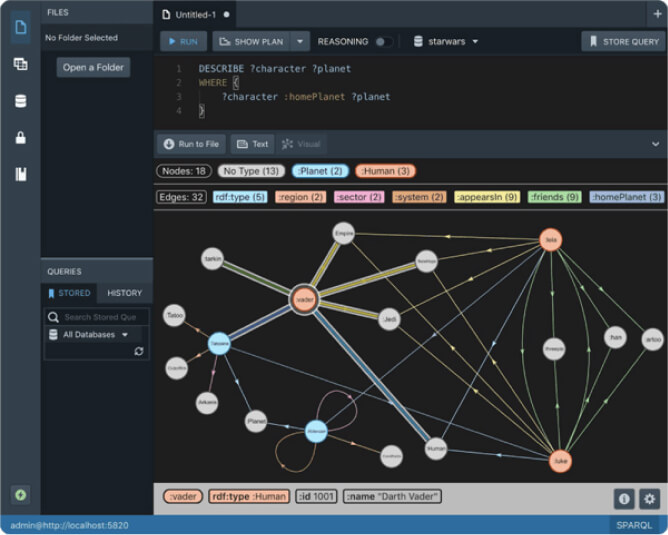
Introducing Plan Endpoint
When it comes to languages for querying databases, they tend to look more human-readable than a typical programming language. SPARQL, as well as SQL, employs declarative approach, allowing to describe what data needs to be retrieved without burdening the user with minutiae of how to do it. Besides being easier on the eyes, this leaves a DBMS free to choose the way it executes queries. And as is typical for database management systems, Stardog has its own internal representation for SPARQL queries: the query plan.
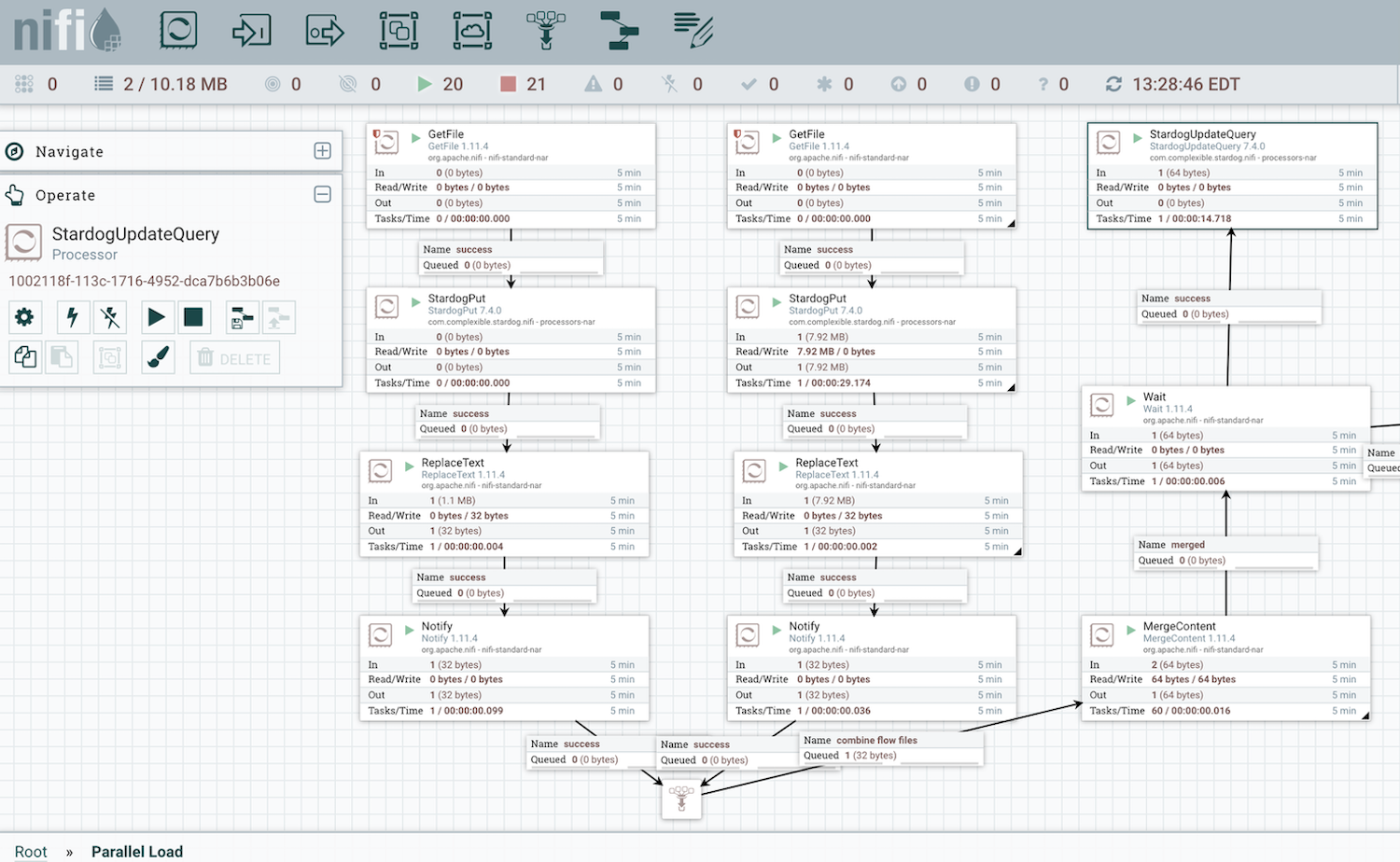
Stardog Data Flow Automation with NiFi
We are happy to announce a new feature that enhances your ability to load data into Stardog’s graph database with the release of Nifi support in v7.4.
Try Stardog Free
Stardog is available for free for your academic and research projects! Get started today.
Download now