Stored Query Service

Stardog is a very extensible platform and the SERVICE keyword in SPARQL is one of its main extension points. It was originally introduced for SPARQL Federation, i.e. querying remote SPARQL endpoints on the Web, but at Stardog we recognised a long time ago that SERVICE could be used far beyond that. For us and our customers, it is a general mechanism for incorporating all sorts of computation within SPARQL queries, for example, we have been using it for full-text search and Machine Learning. Most recently we employed it to invoke stored queries from inside other SPARQL queries, i.e. like (parameterised) views. As we see shortly, this feature boosts modularity, compositionality, and opens a range of exciting possibilities for the future.
Stored queries as reusable building blocks
Stored queries have been supported by Stardog and extensively used for quite some time. Many queries tend to be executed often and it’s handy to call them by name rather than compose the query string each time. Also, once a query is added, the Stardog server takes care of it, e.g. it’s durably stored in the system catalogue, replicated in the cluster, etc., all that is left is to call it by name. That is pretty great by itself i.e. queries have become sharable building blocks for users to build applications.
However, one critical feature of building blocks in any context is reusability. Prior to Stardog 7.3.2 reusability of stored queries has been limited. They could be reused as independent queries but not within a larger query. Many customer queries we have seen over the years share common parts which would be ideal candidates for storing. Consider the following query from the BSBM Business Intelligence benchmark:
Select ?product (xsd:float(?monthCount)/?monthBeforeCount As ?ratio)
{
{ Select ?product (count(?review) As ?monthCount)
{
?review bsbm:reviewFor ?product .
?review dc:date ?date .
Filter(?date >= "2008-04-16"^^xsd:date && ?date < "2008-05-14"^^xsd:date)
}
Group By ?product
} {
Select ?product (count(?review) As ?monthBeforeCount)
{
?review bsbm:reviewFor ?product .
?review dc:date ?date .
Filter(?date >= "2008-03-19"^^xsd:date && ?date < "2008-04-16"^^xsd:date)
}
Group By ?product
Having (count(?review) > 0)
}
}
Order By desc(xsd:float(?monthCount) / ?monthBeforeCount) ?product
Limit 10
Looks pretty complex, doesn’t it? But if you zoom in, you will see that it’s basically just one subquery repeated twice, with different date constants. This query simply retrieves products with the largest increase of interest (ratio of review counts) from one month to the next. The repeated part returns the number of reviews per product for a range of dates. It would be great to store that query once but invoke twice with different date ranges!
That’s the basic idea of parameterised views in databases.
This is precisely what the new Stored Query Service (SQS) in 7.3.2 enables Stardog users to do. Here is the subquery that should be stored e.g. under the name of reviewCounts:
select ?product (count(?review) As ?monthCount)
{
?review bsbm:reviewFor ?product .
?review dc:date ?date .
Filter(?date >= ?startDate && ?date < ?endDate)
}
group By ?product
Note that the range constants have been replaced by variables ?startDate and ?endDate. They will need to be bound to specific dates when the query is invoked (otherwise it will return no results).
Now the big query is reduced to the following form:
prefix sqs: <tag:stardog:api:sqs:>
select ?product (xsd:float(?monthCount)/?monthBeforeCount As ?ratio)
{
SERVICE <query://review-counts> {
[] sqs:vars ?product ; sqs:var:reviews ?monthCount ;
sqs:var:startDate "2008-04-16"^^xsd:date ;
sqs:var:endDate "2008-05-14"^^xsd:date ;
}
SERVICE <query://review-counts> {
[] sqs:vars ?product ; sqs:var:reviews ?monthBeforeCount ;
sqs:var:startDate "2008-03-19"^^xsd:date ;
sqs:var:endDate "2008-04-16"^^xsd:date ;
}
FILTER(?monthBeforeCount > 0)
}
Order By desc(xsd:float(?monthCount) / ?monthBeforeCount) ?product
It’s much easier to see what’s going on: there’re two SERVICE blocks with different constants. Note how SQS allows assigning new names to variables in the stored query to avoid clashes: ?reviews is mapped to ?monthCount in the first invocation and to ?monthBeforeCount in the second. At the same time ?product sticks to the original name, and it’s important since it’s the join variable between the blocks.
In real-life a subquery like the above could appear in dozens of queries and copy/pasting it around creates a substantial maintenance burden (the DRY principle should hold in SPARQL too after all!). With SQS the subquery would be maintained in one place and can be adjusted — or even wholly replaced by a different one — without any changes to other queries or the application code.
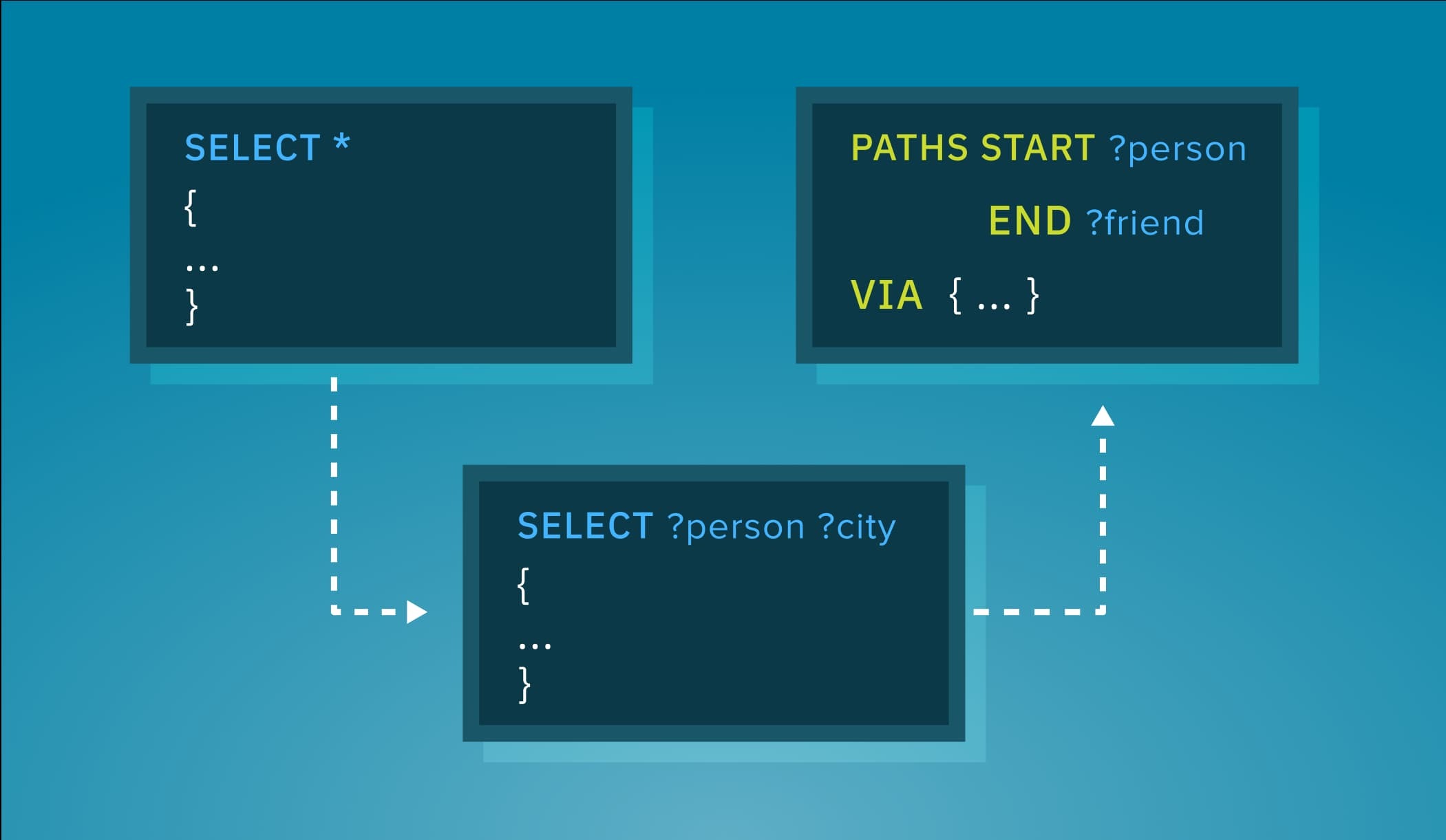
Path queries as subqueries
Reusability isn’t the only goodie that SQS brings around though. While SELECT subqueries can be composed, this is not true for other kinds of queries in SPARQL (which is rightfully criticised for its limited compositionality). For example, Stardog supports paths as a new top-level query form to retrieve paths (as sequences of edges) between nodes in the knowledge graph. Once our customers got a taste of its power, they immediately started asking about using path queries within other queries, e.g. to join paths with other data or post-process (like aggregate) paths. That hasn’t been supported for a while because path queries return paths and not tuples (aka solutions or binding sets in SPARQL) so integrating them into the SPARQL evaluation model is not straightforward.
Now, SQS provides the needed translation layer between paths and binding sets thus enabling path subqueries in SPARQL. Consider the following path queries against the Movies dataset, it returns all shortest paths from some actor to Kevin Bacon, through all intermediate actors who starred in the same movie released on or after 2010:
PATHS START ?x END ?y = "Kevin Bacon"
VIA {
?movie :hasTitle ?title ; :hasYear ?year .
?x ^:hasName/:actedIn ?movie .
?y ^:hasName/:actedIn ?movie .
FILTER (?year >= 2010)
}
LIMIT 1000
(it’s always a good idea to use LIMIT or MAX LENGTH in path queries since the number of paths grows quicker than one can ever expect!)
Now, how about checking which actors are connected to Kevin Bacon over most paths? That seems natural but not at all straightforward because it requires aggregating paths after finding them. One cannot simply put a PATHS query as a subquery (in addition to the paths vs tuples mismatch it’d require another syntax extension for SPARQL). SQS, however, makes it easy without any new syntax:
select ?name (count(?path) as ?paths) {
service <query://pathsToKevinBacon> {
[] sqs:vars ?path ; sqs:var:x ?name
}
FILTER(?name != "Kevin Bacon")
}
group by ?name
order by desc(?paths)
The path query is first stored under the name of pathsToKevinBacon after which it’s called as a service which projects the ?x variable as ?name and the implicit ?path variable as-is. SQS translates paths to solutions which can then be aggregated and sorted in the standard SPARQL solution modifiers group by and order by.

This is just one example of what’s possible with SQS and path queries. One can also now check conditions on paths via FILTERs or compute functions over paths using BIND. That will require new SPARQL functions which take paths but the good news is that Stardog makes it very easy to write user-defined functions (UDFs). We added one obvious function — length — which simply returns the length of a path. One can use it to get the average path length or even return paths longer than a threshold (that would not be possible with path queries alone).
Next steps
The Stored Query Service is in beta as of 7.3.4 release and we’re looking for feedback. We merely just started scratching the surface of what is possible with it! The list of future possibilities is already pretty long with some of them being particularly exciting.
Dataset overriding
SPARQL does not allow specifying the query dataset for subqueries i.e. one cannot use FROM or FROM NAMED keywords in a subquery. However we can support that via SQS without a syntax extension. Stored queries can be treated as queries executed over the SPARQL Protocol where the dataset (as lists of default and named graphs) can be specified externally. That’d enable users run the same stored query against different graphs — possibly some virtualised ones — within different outer queries.
Syntax shortcuts
While the SERVICE form has the advantage of being a perfectly valid SPARQL, one can imagine a more concise syntax for invoking stored queries. For example, it could look like regular subqueries with the query name following the new keyword EXECUTING:
select ?product (xsd:float(?monthCount)/?monthBeforeCount As ?ratio)
{
{ SELECT ?product
?reviews as ?monthCount
"2008-04-16"^^xsd:date as ?startDate
"2008-05-14"^^xsd:date as ?endDate EXECUTING query:review-counts }
{ SELECT ?product
?reviews as ?monthBeforeCount
"2008-03-19"^^xsd:date as ?startDate
"2008-04-16"^^xsd:date as ?endDate EXECUTING query:review-counts }
FILTER(?monthBeforeCount > 0)
}
That would allow us to reuse the familiar FROM/FROM NAMED keywords for specifying datasets.
Correlated subqueries
SPARQL does not support correlated subqueries like in SQL and that could be a pretty painful limitation in some cases (some of which are discussed in the following open ticket in the SPARQL 1.2 Community Group). For example, it is impossible to specify that a subquery must be evaluated for every value of a variable bound in the outer query since every subquery is evaluated independently, in the bottom-up fashion. Adding this functionality to SPARQL would again require a syntax extension, something akin to LATERAL keyword in latest versions of Postgres.
However it does not look like an obstacle for SQS. In fact, some services in Stardog already require input arguments so they are not evaluated independently. For example, the full-text search service can have a variable in the search query position so it must be bound before it can be evaluated against the full-text index. Stardog enables services to indicate required inputs and performs evaluation in the right order. Stored queries which should be run as correlated subqueries can take advantage of the same capability in a future version of Stardog.
Query plan pinning and stability
We mentioned improved query reusability as a key benefit of SQS. A closely related and also highly sought after characteristic is stability, especially with respect to performance. Intuitively, a SPARQL query is stable when its runtime either does not change or changes predictably as the database evolves. For example, if the query scans all products, its runtime is expected to grow linearly as the number of products increases and is not expected to change when the number of products doesn’t.
That property, however, is easier to stipulate than to ensure. Complex queries require a sophisticated query optimisation process which is not guaranteed to find the best query plan in all cases (after all, just the part which computes the optimal join order is by itself an NP-hard problem in conjunctive query languages like SPARQL or SQL). Sometimes the query optimiser makes mistakes and the user has to intervene and give it a nudge either by reformulating the query or adding an optimiser hint. We did a webinar on that topic.
An unstable query is an annoyance at best and in the worst case can compromise behaviour of the entire application running on top of the database. It can complicate data imports and increase maintenance burden. Nobody likes that. Everyone wants their queries be stable like a rock.
Stored queries can be an effective tool to deal with this issue if we can guarantee that they’d be evaluated according to a fixed query plan regardless of the context. Several major SQL database vendors ensure that by pinning plans to queries. SQS makes this future Stardog feature even more relevant because better reusability of stored queries means increased performance stability over a wider range of queries. It’s not just that stored queries would become stable, they would also increase stability of all the queries which invoke them. That’s because using a fixed plan for a part of a query means smaller search space for the optimal plan of the larger query.
Stay tuned and you will definitely see Stored Query Service related improvements in release notes for future versions of Stardog. Meanwhile give it a try, we would love to hear what you think.
Keep Reading:
Introducing Plan Endpoint
When it comes to languages for querying databases, they tend to look more human-readable than a typical programming language. SPARQL, as well as SQL, employs declarative approach, allowing to describe what data needs to be retrieved without burdening the user with minutiae of how to do it. Besides being easier on the eyes, this leaves a DBMS free to choose the way it executes queries. And as is typical for database management systems, Stardog has its own internal representation for SPARQL queries: the query plan.
Stardog Data Flow Automation with NiFi
We are happy to announce a new feature that enhances your ability to load data into Stardog’s graph database with the release of Nifi support in v7.4.
Try Stardog Free
Stardog is available for free for your academic and research projects! Get started today.
Download now