Chaos Testing Stardog Cluster for Fun and Profit

At Stardog we work hard to build software that’s not only performant but also extremely robust. Stardog Cluster is a highly available, key component to ensuring Stardog remains up and running for our customers. However, every distributed system is susceptible to faults and bugs wreaking havoc on it.
Most software testing checks the “happy path” through the code to verify it behaves as designed. Moving a step further, tests can check some obvious failure cases; for example, if one service in a deployment is terminated. It can be exceptionally difficult to test more pathological cases where bugs manifest differently due to any number of failures or subtle timing differences in a distributed system. We have a suite of “controlled chaos” tests that we explained in a previous post to test various operations against Stardog Cluster for such bugs.
Over the past few years we’ve been collaborating with the team at Antithesis to dive even deeper into chaos testing Stardog Cluster in order to track down and squash these kinds of insidious bugs. In this post we discuss our work with Antithesis and how we chaos test Stardog Cluster using their platform. We also provide an in-depth analysis of one of the bugs we discovered using their platform, why it matters, and why such bugs are almost impossible to detect and fix with traditional test frameworks.
A Brief Overview of Stardog Cluster
Before diving into the details of our chaos testing, let’s first review the Stardog HA architecture as well as the Antithesis testing platform. Stardog Cluster consists of Stardog nodes, a coordinator and one or more participants, and 3 or more ZooKeeper nodes. A load balancer distributes client requests to any Stardog node in the cluster.
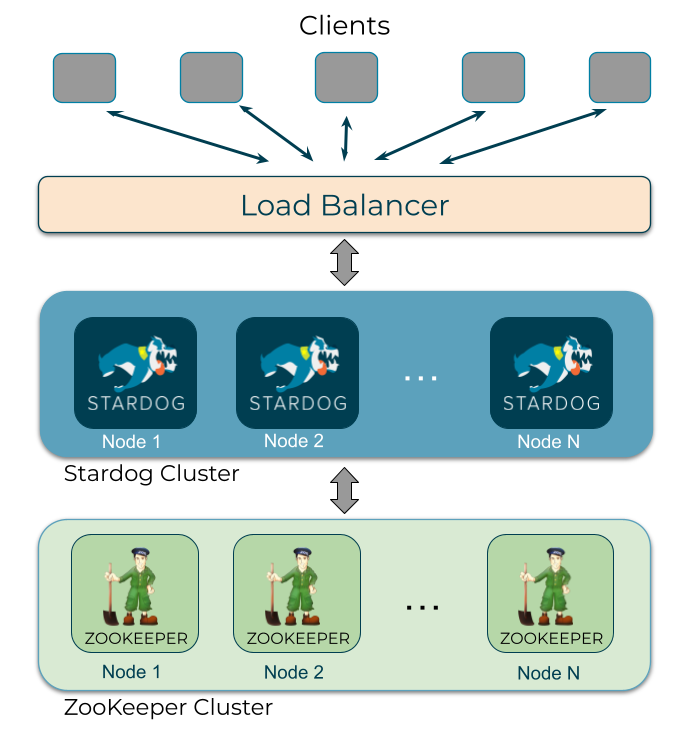
The cluster is strongly consistent and supports ACID transactions. The cluster guarantees that all nodes in the cluster contain the same data and return the same results for a query. Any node that fails an operation that would compromise the consistency of the cluster is expelled. The failed node must synchronize from another node before it can rejoin the cluster. Datasets are not sharded across the cluster; instead, each node contains an entire copy of the data.
A coordinator orchestrates operations across the cluster. Any node in the cluster can handle a request from a client. However, certain operations, such as beginning a transaction, are forwarded to the coordinator, which then replicates the operation out to the other nodes. If the coordinator fails mid-transaction, the transaction is automatically rolled back and the Stardog nodes query ZooKeeper to identify which node is the new coordinator. In addition to leader election, ZooKeeper stores a variety of metadata for the cluster such as the latest transaction ID committed, cluster-wide locks, and cluster membership information about which nodes are currently cluster members and which node is the coordinator.
Antithesis Test Platform
Antithesis is still operating in a pretty stealthy way, but here’s what I can reveal: the Antithesis test environment includes a mechanism for injecting faults, instrumenting the code being tested to gather logs, metrics, and other statistics, as well as an intelligent fuzzer that searches for interesting runtime behavior. Antithesis has a way to force all the software to execute deterministically, even though it’s distributed and concurrent. This means that all Stardog Cluster nodes, the ZooKeeper nodes, and the workload are guaranteed to execute in the exact same order and produce the exact same results from run to run, provided the same starting conditions, usually determined by a random seed. The workload is executed and processed in a way that can be rerun to certain states and allows the fuzzer to test rare branches of code which may be more prone to certain kinds of failures.
The faults injected by Antithesis include both background faults and event-based faults. Background faults include varying the latency on the network connections and dropping packets between the components in the system. Event-based faults include partitioning one or more nodes, pausing components in the system, as well as stopping or killing containers.
The intelligent fuzzer determines which faults to trigger and at what points and for how long. It attempts to learn which states in the distributed system lead to unexplored branches in the code or areas that may experience notable issues, such as throwing particular exceptions that we’re trying to trigger. Despite the deterministic nature of the environment, the randomness generated by the fuzzer and the faults that are injected as it searches different states in the software provides extensive chaos testing.
Antithesis test runs are not a single execution of the test workload. Instead the test run consists of many rollouts, or individual test runs, of the workload. Sometimes this can be as many as tens of thousands or hundreds of thousands of executions of the test workload. For each rollout the intelligent fuzzer provides different inputs to the fault generator, allowing it to search through many possible states looking for issues.
At the end of the test run the Antithesis environment provides a single log file for each rollout that contains the output from all services and the test workload, ordered by time. If one (or more) of the rollouts failed, the logs from that rollout are analyzed to find the root cause of the problem.
Deterministic Chaos Testing with Antithesis
One specific bug we found recently resulted in an inconsistent cluster when the coordinator failed during writes to the cluster. The bug described below is identified as PLAT-4309 and we shipped a fix for it in Stardog 8.0.
Test Design
The tests we developed for this work are similar to a basic integration test. These tests exercise basic functionality for a period of time and then the results are asserted across the cluster to ensure all nodes remain consistent even in the presence of faults. For example, our “set” test, inspired by a similar Jepsen test, inserts unique integers into Stardog for the duration of the test and then asserts that all nodes contain the same values and that there are no duplicates. A client simply inserts 1 integer at a time starting with 0 using a simple query:
INSERT DATA { :Value0 :value 0 }
The test increments the integer after each successful insertion. If the client fails to insert the value, it retries until it is successful or the test times out. The test runs for a few minutes while the client inserts data and Antithesis injects faults into the environment. Once the test finishes, both the client inserting data and the faults are stopped and the cluster is checked for consistency after it stabilizes.
Test Setup
This particular test used the set workload. The setup consisted of a 3 node Stardog cluster (we’ll refer to the individual nodes as stardog1, stardog2, and stardog3) with 3 ZooKeeper servers. Once all servers booted, the cluster registered as ready, and a database was created. Then the fault injector started and the workload began inserting values at approximately 146 seconds into the run. The fault injector was configured to impose network latency of 1ms with spikes to 100ms and to partition nodes for 1-3s every 30s. Packet dropping was disabled.
The first 20 values were inserted when the workload issued a restart to the cluster at 206 seconds into the run. At that point, the client began to receive exceptions that the cluster was unresponsive and it began retrying to insert Value21 every 1s. At 276 seconds all nodes rejoin the cluster and at 283 seconds the load balancer detects that the Stardog nodes are ready. Value21 is finally able to be inserted and the workload proceeds inserting data while faults continue to be generated in the environment.
After approximately 8 minutes the test completes. The client reports that it was able to insert 149 values successfully during that time. We expect that, at the end of the test run, all nodes in the cluster would have the same results with no duplicates.
Consistency Issues
At the end of the test stardog1 contained 107 values, stardog2 contained 63 values, and stardog3 had 21 values! To determine where the cluster became inconsistent we enabled DEBUG logging across Stardog Cluster. In the logs we observed an unexpected sequence of messages that pointed to the root cause. In particular, we observed that originally stardog1 was the coordinator, but after the cluster restart, stardog1 and stardog2 join close together. The test environment provides a single true ordering of events. Despite the system being distributed, the output from each node is shown with precise timing so that events on one node can be definitively said to have occurred before or after events on other nodes.
First we see at second 274 that stardog2 identifies as the coordinator as stardog1 is joining:
[1000000137404] [ 274.742820] [stardog1.log][I] INFO 2022-04-13 18:04:18,500 [main] com.complexible.stardog.pack.replication.ReplicatedKernelImpl:joinCluster(730): Node stardog1:5820 joined the cluster:
[1000000137404] [ 274.742884] [stardog1.log][I] INFO 2022-04-13 18:04:18,500 [main] com.complexible.stardog.pack.replication.ReplicatedKernelImpl:joinCluster(731): Coordinator: stardog2:5820
Shortly after, at second 275, we observe stardog2’s official join message, which claims stardog1 is the coordinator:
[1000000137426] [ 275.510581] [stardog2.log][I] INFO 2022-04-13 18:04:19,268 [main] com.complexible.stardog.pack.replication.ReplicatedKernelImpl:joinCluster(730): Node stardog2:5820 joined the cluster:
[1000000137426] [ 275.510598] [stardog2.log][I] INFO 2022-04-13 18:04:19,268 [main] com.complexible.stardog.pack.replication.ReplicatedKernelImpl:joinCluster(731): Coordinator: stardog1:5820
Finally, when the last node, stardog3, joins at second 276 stardog1 is still marked as the coordinator:
[1000000137426] [ 276.224934] [stardog3.log][I] INFO 2022-04-13 18:04:19,982 [main] com.complexible.stardog.pack.replication.ReplicatedKernelImpl:joinCluster(730): Node stardog3:5820 joined the cluster:
[1000000137426] [ 276.224999] [stardog3.log][I] INFO 2022-04-13 18:04:19,983 [main] com.complexible.stardog.pack.replication.ReplicatedKernelImpl:joinCluster(731): Coordinator: stardog1:5820
[1000000137426] [ 276.225042] [stardog3.log][I] INFO 2022-04-13 18:04:19,983 [main] com.complexible.stardog.pack.replication.ReplicatedKernelImpl:joinCluster(732): Cluster nodes: [stardog2:5820, stardog3:5820, stardog1:5820]
At that point, stardog3 forwards the commit for Value21 to stardog1 (the latest node to be elected coordinator). When stardog1 receives the message to commit it only commits the data locally and it doesn’t replicate the commit to the other nodes since it still thinks that stardog2 is the coordinator.
Internally, Stardog Cluster maintains a cached view of its members from ZooKeeper. The cached view identifies which cluster member is the coordinator and which are participants, minimizing the number of lookups required from ZooKeeper. The log messages suggest that stardog1 is the latest node to become the coordinator, but the fact that stardog1 thinks stardog2 is still the coordinator led us to suspect that stardog1’s cached view of the cluster is stale.
The cached view of cluster members was originally added as an optimization to reduce lookups to ZooKeeper. When we disabled the cached view, the error resolved. Additional test runs of the workload verified that the cluster maintained consistency when all cluster member operations queried ZooKeeper directly. After disabling the cache we also ran performance and stress tests to verify that the cluster functioned appropriately and performed the same. Stardog 8.0 disables the cached view by default and it can be reenabled through a configuration option. Future versions may re-enable a fixed version of the cache when the optimization is needed.
Limitations of Traditional Software Testing
In addition to this bug, we’ve found other bugs in Stardog Cluster through our testing with Antithesis. Some of the bugs we’ve found and fixed also caused inconsistencies due to failures at certain points in the replication process for transactions, such as when connections are being initiated between cluster members (PLAT-2404 fixed in Stardog 7.7.0) or if unknown transaction exceptions are thrown during replication (PLAT-4019 fixed in Stardog 8.0).
Using traditional unit or integration tests to find and fix these kinds of issues is virtually impossible because they don’t provide mechanisms for fault injection. The deterministic runtime and intelligent fuzzer take this form of fault testing a step further allowing it to search areas of the code or certain states of the distributed system where these bugs may be hiding. Other approaches to chaos testing, such as long running tests that use tools like Netflix’s Chaos Monkey can only provide minimal amounts of chaos and require long running tests on relatively expensive instances in the cloud to find similar bugs in a distributed system.
Executing hundreds of thousands of rollouts in a deterministic runtime that randomly injects faults as the distributed system moves from one state to another allows extensive chaos to be inflicted on Stardog Cluster in a relatively short amount of time. This has helped us find and fix numerous of these subtle, but possibly catastrophic, bugs in Stardog Cluster over the past few years.
Conclusion
Our customers depend on Stardog Cluster to live up to its guarantees that all nodes contain the same data and will respond to their queries in an expected and predictable manner. Therefore, it’s crucial that we find any bugs, no matter how rare they may be in practice, that could lead to inconsistencies in the cluster or undermine these guarantees in any way. Testing and improving complex distributed systems is a never-ending task, however, at Stardog, engineering won’t stop our work to improve the robustness and stability of our product.
Try Stardog 8.0 today and give us feedback on Stardog Community!
Keep Reading:

Unified Process Monitoring
Did you ever have a slow query, export or any other operation and wondered “Is this ever going to finish?!”. Many operations such as SPARQL queries, db backups etc have performance characteristics which may be hard to predict. Canceling rogue queries was always possible, but there was not yet a way to do so for other potentially expensive operations. If this ever affected you then the new unified process monitoring feature we added in Stardog 8.
Knowledge Graphs for Data Science - Part 1
A database, equipped with an optimized query language, is a powerful tool in the data science toolkit. We’ve all written our share of SQL queries to create data summaries, perform exploratory analyses, check for null values and other basic tasks. When data weigh in at over 1GB, the best approach is often pairing a good database, for basic data munging, with an analytic platform like R or Python for more nuanced calculations.
Try Stardog Free
Stardog is available for free for your academic and research projects! Get started today.
Download now