Loading a million triples per second on commodity hardware

At Stardog we are continuously pushing the boundaries of performance and scalability. Last month’s 7.5.0 release brought 500% improvement to transactional write performance. This month’s 7.6.0 release improves writing data at database creation time by almost 100%, yielding a million triples per second loading speed using a commodity server. In this post we’ll talk about the details of loading performance.
Let’s do the numbers
The fastest way to load large amounts of data into Stardog is to do at database creation time. Multiple files can be specified at database creation time to be loaded into the newly created database. Since database is just being created it cannot be used for reads or writes at this point. This allows Stardog to use a more optimized process that is not possible for transactional writes we discussed last time.
First let’s look at the performance numbers. In this post we will use three different datasets from commonly used, relevant benchmarks: Berlin SPARQL Benchmark (BSBM), Lehigh University Benchmark (LUBM) and Linked Data Benchmark Council (LDBC) Social Network Benchmark (SNB). We generated these datasets in different scales: from 100 million to 10 billion triples. BSBM and LDBC datasets are stored as gzipped Turtle files, whereas LUBM dataset is stored as gzipped RDF/XML files. The datasets were generated such that we have multiple files of roughly equal size that results in optimal loading speed.
In our tests, we used ‘db create’ command with ‘index.statistics.chains.enabled=false’ database setting and ‘memory.mode=bulk_load’ server setting. We ran the experiments on AWS using the c5d.9xlarge (36 CPUs, 72 GiB RAM) instance type for smaller datasets and c5d.12xlarge (48 CPUs, 96 GiB RAM) instance type for larger datasets as shown in the table below. We used local instance storage (NVMe SSD disk) for the Stardog home directory. The input data files were stored in a gp2 EBS volume with 3K IOPS. The following chart shows the results: both total time spent (smaller is better) and loading speed computed as triples per second (higher is better):
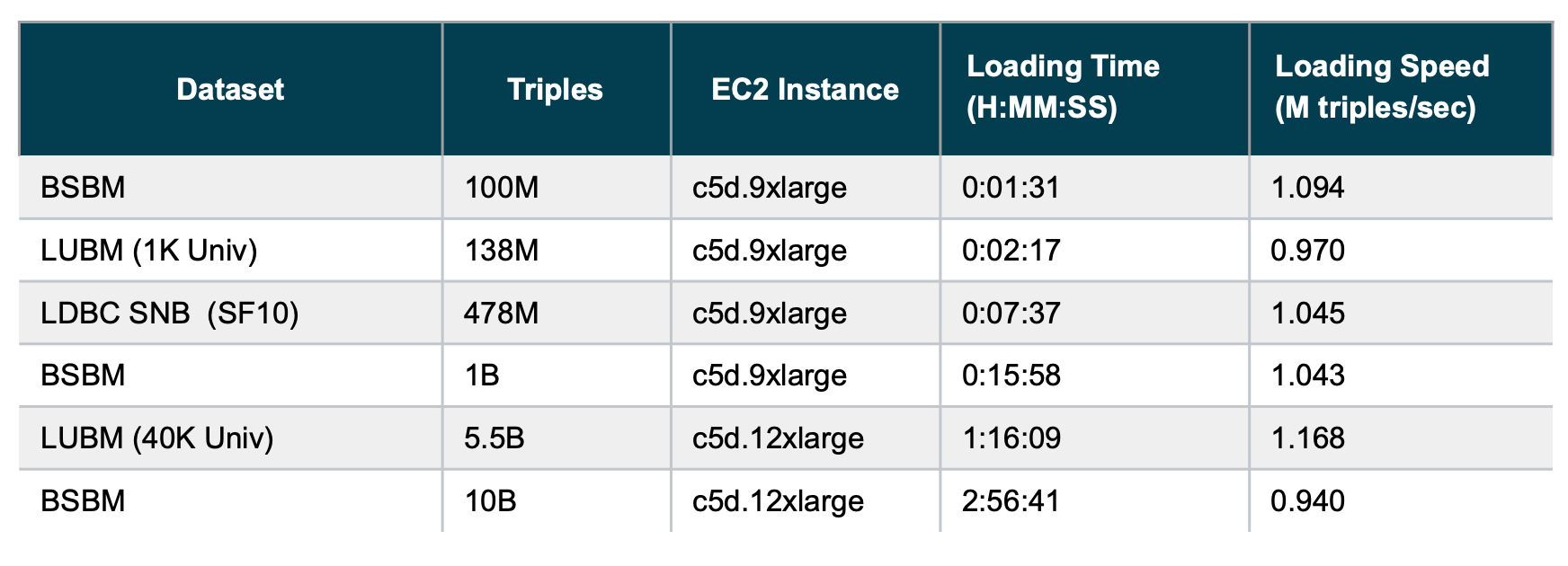
As the results show, loading speed is consistently around 1 million triples per second across these three different datasets at three different orders of magnitude size. One result that might be unintuitive: loading larger datasets might result in higher throughput compared to smaller datasets. We see this in LUBM case above. For shorter runs, the JIT optimizations in the JVM may not have time to kick in.
Look under the hood
There are two primary changes in the most recent Stardog release that contribute to these performance improvements.
The first improvement is related to the data loading stage where Stardog performs dictionary encoding, before the indexing stage. Each node in the graph is assigned a unique 64-bit integer ID that is used in the index in place of IRI strings. This dictionary encoding stage both reads from the dictionary—looking up a node to see if it’s already been processed—and also writes to the dictionary—writing the ID for nodes that haven’t been processed. We have been using RocksDb for the dictionary, but we have reached its limits in this role. We are now using a custom-built dictionary implementation that uses memory more aggressively to do the dictionary encoding; later the encoded values are loaded into RocksDb using its highly optimized SST writers (see the previous post for discussion about SST writers).
The new dictionary encoding process uses memory very aggressively, so we enable this optimization only when ‘memory.mode’ server option is set to ‘bulk_load’. Setting this option means the server is going to be used only for database creation and not for production use.
The second improvement is related to the way Stardog computes detailed statistics from the graph structure to optimize query answering, which involves iterating over the graph. In previous versions statistics computation was done as a separate stage after indexing. Statistics computation is done in multiple threads for large databases this can still be time-consuming. Now we are computing statistics in a stream while the indexes are being written, so no separate stage is needed after indexing.
Try it our yourself
As always it is best to run benchmark on your own dataset as the graph characteristics such as the ratio of the number of nodes to the number of edges in the graph would affect loading performance. Let us know if you have any questions about performance tuning or benchmarking tips.
Keep Reading:
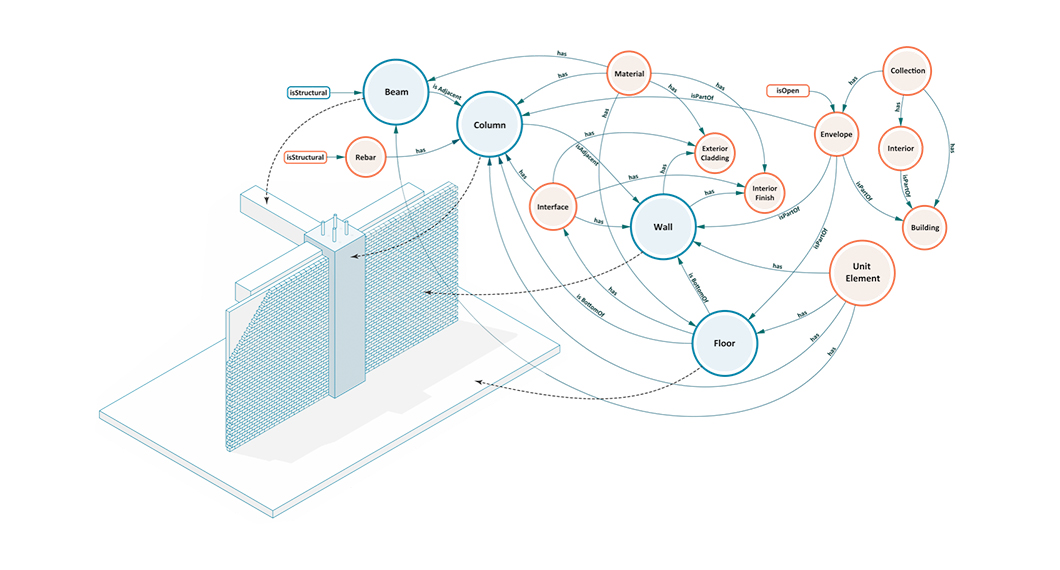
Buildings, Systems and Data
Designing a building or a city block is a process that involves many different players representing different professions working in concert to produce a design that is ultimately realized. This coalition of professions, widely referred to as AECO (Architecture, Engineering, Construction and Operation) or AEC industry, is a diverse industry with each element of the process representing a different means of approaching, understanding, and addressing the problem of building design.

Graph analytics with Spark
Stardog Spark connector, coming out of beta with 7.8.0 release of Stardog, exposes data stored in Stardog as a Spark Dataframe and provides means to run standard graph algorithms from GraphFrames library. The beta version was sufficient for POC examples, but when confronted with real world datasets, its performance turned out not quite up to our standards for a GA release. It quickly became obvious that the connector was not fully utilizing the distributed nature of Spark.
Try Stardog Free
Stardog is available for free for your academic and research projects! Get started today.
Download now