Write Performance Improves up to 500%

Stardog 7.5.0 improves write performance up to 500% in some cases. In this post I describe the details of this improvement and share detailed benchmarking results for update performance.
Large Updates
A common usage pattern for Stardog involves connecting to external data sources through virtual graphs that are queried on-demand without storing any data in Stardog. However, in some cases you might enable virtual graph caching to pull data into Stardog for indexing and in some other cases it is preferable or even necessary to materialize the data in Stardog completely. In either case Stardog not only has to store large amounts of data but it also has to update this data periodically based on both some business requirement and on the update frequency of external data sources.
All of this means that the write performance of large updates in Stardog is quite critical.
As I explained recently we use many different datasets for benchmarking performance. In this post I will describe the results obtained using the BSBM dataset which allows us to repeat our benchmarks at different scales. The update benchmark in BSBM covers only small updates; to benchmark large updates we created our own use cases.
The simplest test we performed is to load the BSBM dataset into an empty Stardog database using the transactional update mechanism (data add command). Normally if the database is being freshly created we would use the db create command, which provides better throughput. But here we first needed to establish a baseline for transactional update performance. We created BSBM as gzipped Turtle files at three sizes: 10 million (10 files), 100 million (10 files), and 1 billion (100 files) triples. Writing data via multiple files is important to allow multiple threads to be used.
We ran our experiments on EC2 r4.2xlarge machines (8 vCPUs, 60GB memory) with general-purpose gp2 disks. The following chart shows how the performance changes from Stardog version 7.4 to 7.5 for three different data scales; here larger throughput values are better.
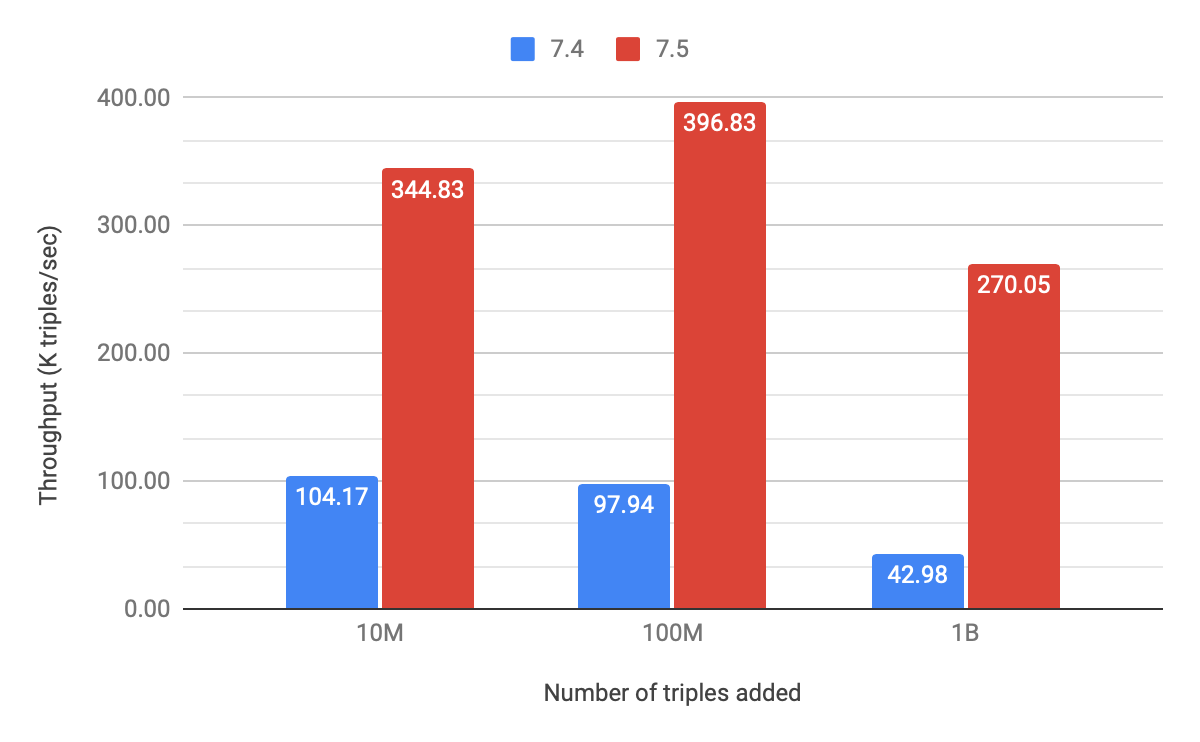
Stardog version 7.5 is 230% faster than version 7.4 while adding 10 million triples; 300% while adding 100 million triples; and more than 500% faster when adding 1 billion triples.
Deeper Dive
Let’s examine in more detail what changed in version 7.5 and what we mean by “large updates”. There are several smaller changes our storage team–that is, Simon Grätzer and Matthew Von-Maszewski–did to reduce the overhead of updates. These smaller changes added up to good but modoest performance improvement, especially as the number of triples increases. But to get really significant speedups, we had to rework the update mechanism more deeply.
Stardog uses RocksDb as the low-level storage engine. Updates are first written to a write-ahead log (WAL) for persistence and recovery and then to an in-memory structure (memtable). Once memtables fill up, the contents get flushed to disk into SST files. The LSM index in RocksDb organizes SST files in levels of different file sizes. Once a given level is full, the compaction process merges the files in that level into larger files in the next level. Compaction typically happens in the background, but, as you are adding more and more data, it’s more likely to be triggered while the update is going on. That can lead to significant overhead. To improve large updates we have taken the approach that we use for database creation. We create SST files in a separate, multi-threaded process before sending these files to RocksDb, bypassing the process explained above. This also ensures that a transaction is committed and acknowledged before compaction kicks off.
Using this mechanism pays off only when the amount of data being added is larger than some threshold. Our experiments showed that the threshold is around 5M triples. The challenge is figuring out how many triples a transaction is going to change before processing the data. Stardog inspects the amount of bytes sent by the client and uses several heuristics to estimate the number of triples. For example, in Turtle serialization a triple is estimated to take 80 bytes, and gzip compression is estimated to reduce the file size by a factor of 10. These estimates might not be very accurate, but they are good enough to enable this optimization.
More Benchmarks
The simple test described above gives us a general idea, but it is uncommon to add data to an empty database. A given database probably already contains data and that affects performance. These are the kind of scenarios we test in Starbench continuously.
So next let’s look into different ways of adding 10M triples into a Stardog database. These experiments use smaller r4.xlarge machines (4 vCPUs, 30GB memory) and the input is given in only one big file, limiting the amount of multi-threading used on the server. As a result overall throughput numbers are lower, but the comparison between different Stardog versions is still valid. In the first case, we will test when all the data is available upfront and we can add all 10M triples in one transaction similar to the previous case but this time using a single file. The following chart shows the performance of Stardog 7 releases on this experiment based on three different starting database sizes:
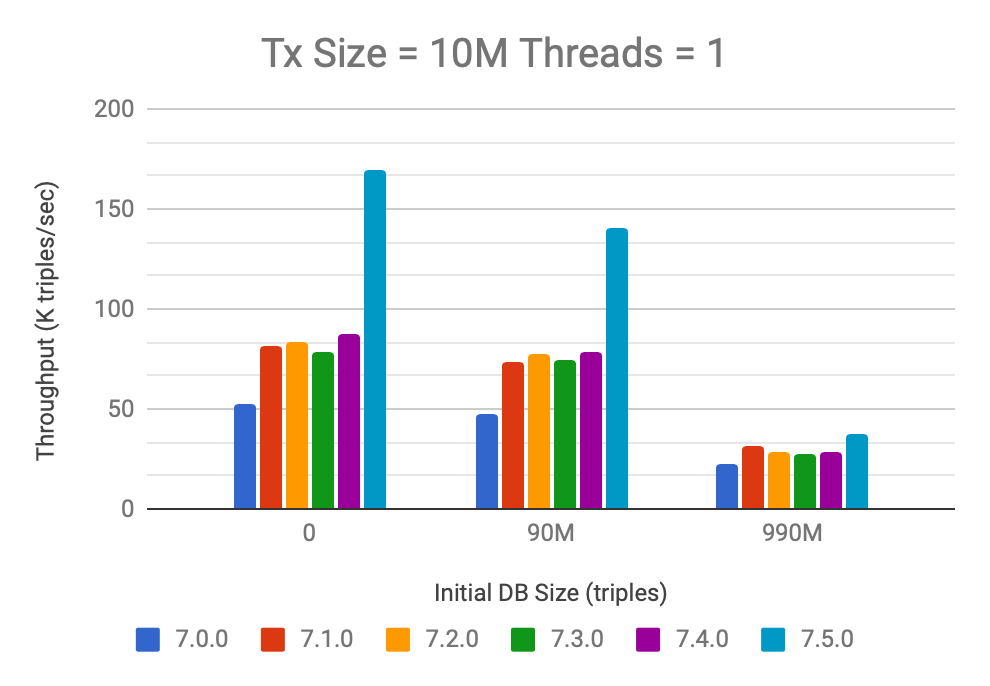
When we look at the case of writing to an empty database, we see a big jump in performance from 7.0 to 7.1, then no statistically significant change until 7.5 where we see twofold improvement. This is the same test as before but using less powerful machines results in quite different throughput numbers. The trend for update performance is similar when the starting database has 90M triples.
When the initial database size is 990M triples the performance improvement between 7.4 and 7.5 is smaller (32%). The smaller improvement we see here, as well as the very low (less than 50K) throughput, is due to the two factors I already mentioned: using a less powerful machine and providing input in a single large file.
When we repeat this same test of adding 10M triples to a database that already has 990M triples on a r4.2xlarge machine, the throughput for version 7.5 increases to 55K triples/sec. When we split the input into 10 files, then the 7.5 throughput reaches 270K triples/sec, whereas 7.4 throughput does not go beyond 80K triples/sec, which is again 3.5 times difference.
This kind of huge increase shows that Stardog 7.5 takes much better advantage of multiple cores and increased memory.
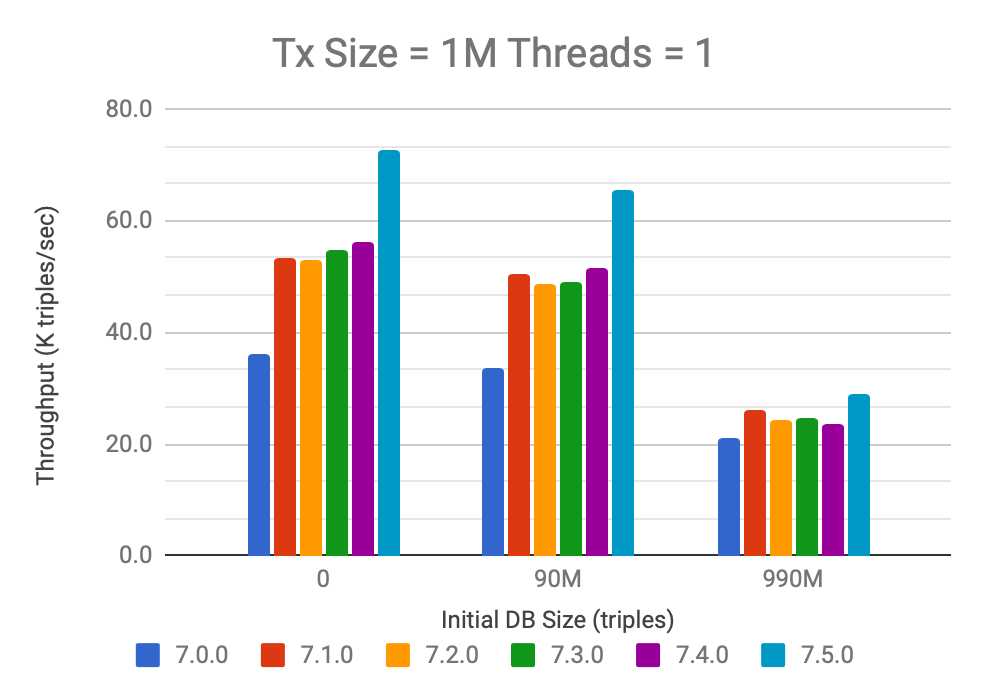
Next, let’s look at the case where data on the client-side becomes available in batches of 1M triples, so that it needs to be added in 10 separate transactions. In this case, the SST optimization described above is not enabled because Stardog thinks, somewhat mistakenly, that only 1M triples are being added. As a result we see only 20-30% increase in performance for 7.5 and overall throughput decreases a lot compared to the case where all 10M triples are added at once:
Finally, let’s look at the case where we are writing the triples in very small batches of 1K triples per transaction. But this time we will use 10 concurrent transactions and the performance trend looks like this:
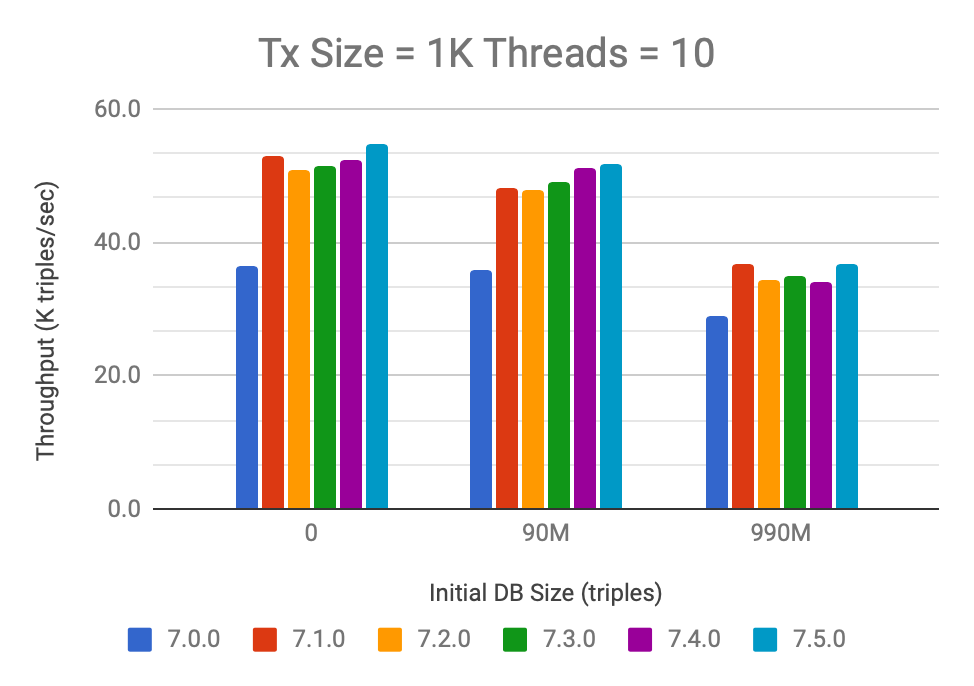
For these small transactions, none of the optimizations in 7.5 are applicable and performance remains unchanged for 7.5. The overall throughput is smaller but the drop is not as significant thanks to increased concurrency.
Conclusions
There are some important takeaways about write performance:
- Stardog 7.5 is several times faster than Stardog 7.4 while adding large amounts of data (more than a million triples). The amount of improvement increases as the amount of data added increases.
- Grouping data into bigger transactions improves the throughput (triples added per second).
- Using multiple files within a single transaction improves performance significantly (5-6 times).
- When using smaller transactions, increasing the number of concurrent transactions improves performance.
- Not surprisingly, the choice of hardware makes a big difference as the throughput numbers on more powerful r4.2xlarge machines are much better than the results on r4.xlarge machines.
There are many other factors that could affect performance: the serialization format used for files, data characteristics, and so on.
We always recommend that users measure performance on their dataset using their workload to get the most realistic results. You can get started with Stardog today to run your own benchmarks. Let us know if you have any questions about performance tuning or benchmarking tips.
Keep Reading:
Buildings, Systems and Data
Designing a building or a city block is a process that involves many different players representing different professions working in concert to produce a design that is ultimately realized. This coalition of professions, widely referred to as AECO (Architecture, Engineering, Construction and Operation) or AEC industry, is a diverse industry with each element of the process representing a different means of approaching, understanding, and addressing the problem of building design.

Graph analytics with Spark
Stardog Spark connector, coming out of beta with 7.8.0 release of Stardog, exposes data stored in Stardog as a Spark Dataframe and provides means to run standard graph algorithms from GraphFrames library. The beta version was sufficient for POC examples, but when confronted with real world datasets, its performance turned out not quite up to our standards for a GA release. It quickly became obvious that the connector was not fully utilizing the distributed nature of Spark.
Try Stardog Free
Stardog is available for free for your academic and research projects! Get started today.
Download now