Performance Improvements in Stardog 7.9.0

We recently released Stardog 7.9.0 with many exciting features and improvements. Performance is an area we pay close attention to and improve with each release and 7.9 is no exception. You’ll see faster performance for SQL queries with left joins and SPARQL queries that contain joins involving optionals, faster loading of large RDF or CSV files, and a new sampling feature that lets you get answers in just a fraction of a second. In this post, we’ll summarize each of these improvements.
BI/SQL Queries
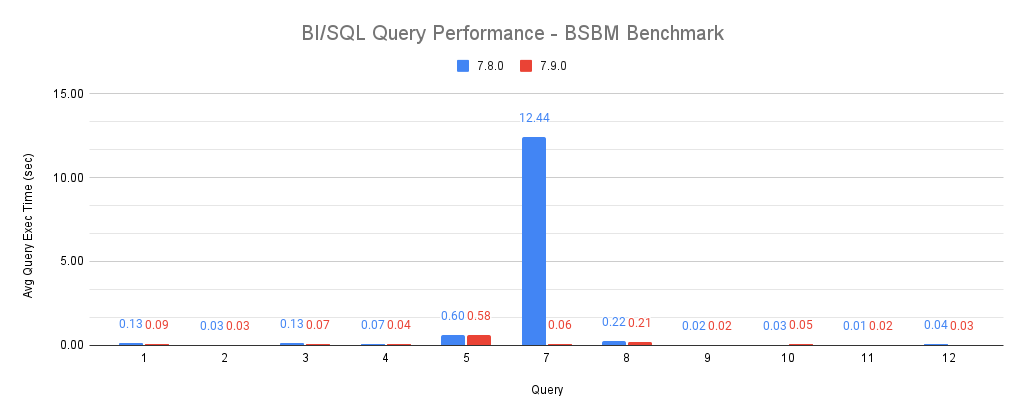
Stardog provides a SQL endpoint for BI tools like Tableau so that users not familiar with graph data or queries can interact with the data in a tabular format and build charts and dashboards. This requires Stardog to answer complex SQL queries by translating them into SPARQL. One of the areas where we have seen performance degrade was the use of LEFT JOINs in SPARQL, which were not being translated into efficient SPARQL queries with OPTIONALs. We have used the SQL queries from the BSBM (Berlin SPARQL Benchmark) to measure the performance of such queries and by improving the translation we have seen the execution time of query 7 in BSBM go from more than 12 seconds down to 60 milliseconds! As the following chart shows the other SQL queries for BSBM were already performing quite well.
Bulk Loading
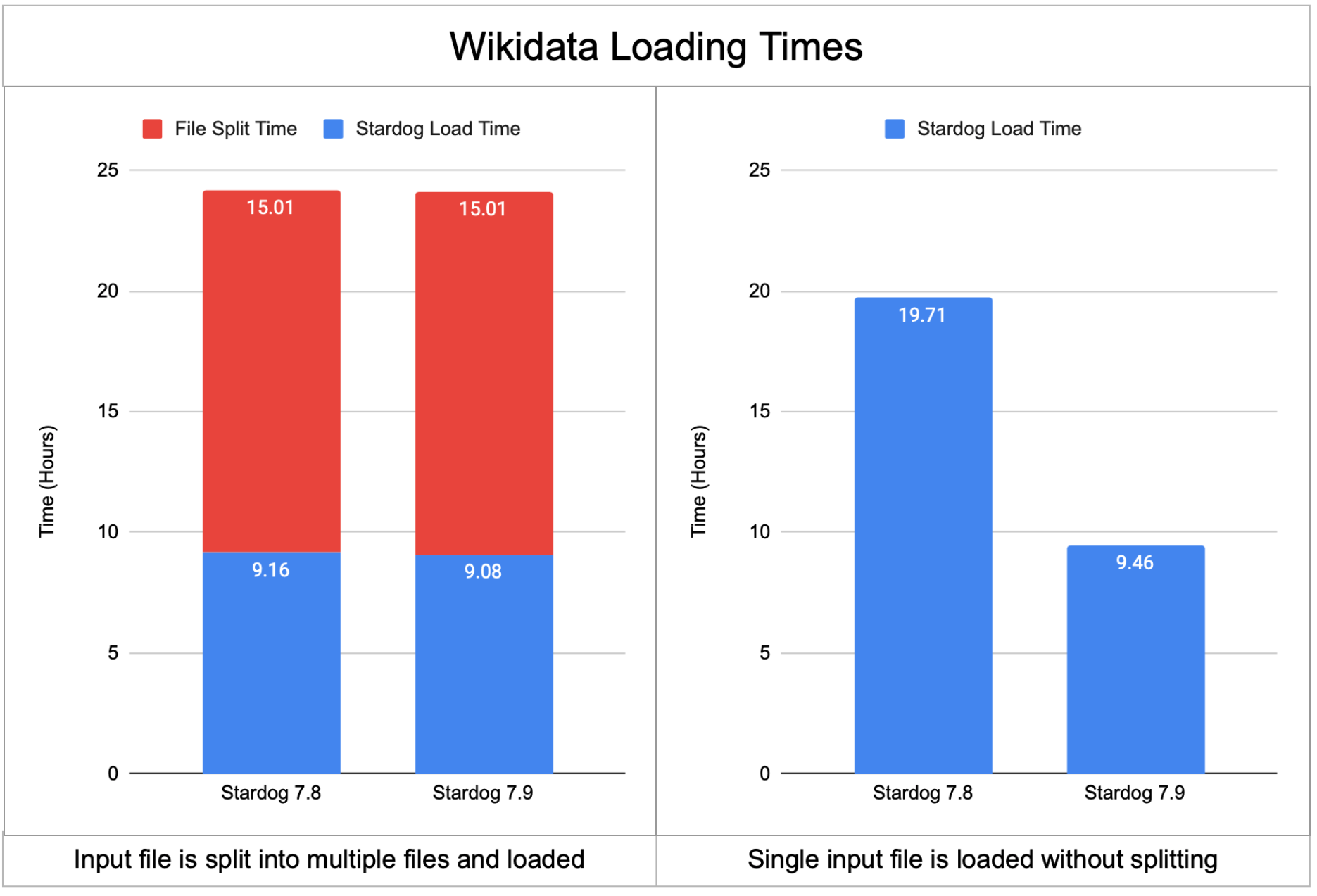
We have described in detail in a recent blog post about our experiments involving Wikidata. One issue with loading very large datasets like Wikidata into Stardog has been the requirement to split the single input file into multiple smaller files so loading can be done in multiple threads. However, the Wikidata RDF file is 178GB in compressed form and splitting the file takes 15 hours itself negating any improvements you get from multi-threaded loading.
In the 7.9 version we introduced a new optimization that can parse a single NTriples or NQuads file in multiple threads. The following chart shows that with 7.8 loading Wikidata would either take 20 hours (if the single file is loaded directly) to 24 hours (if the input file is split first). In contrast, 7.9 can load the single input file under 10 hours resulting in a 2x speed improvement. If your input is already available as multiple files then loading time is slightly better and closer to 9 hours.
CSV Import
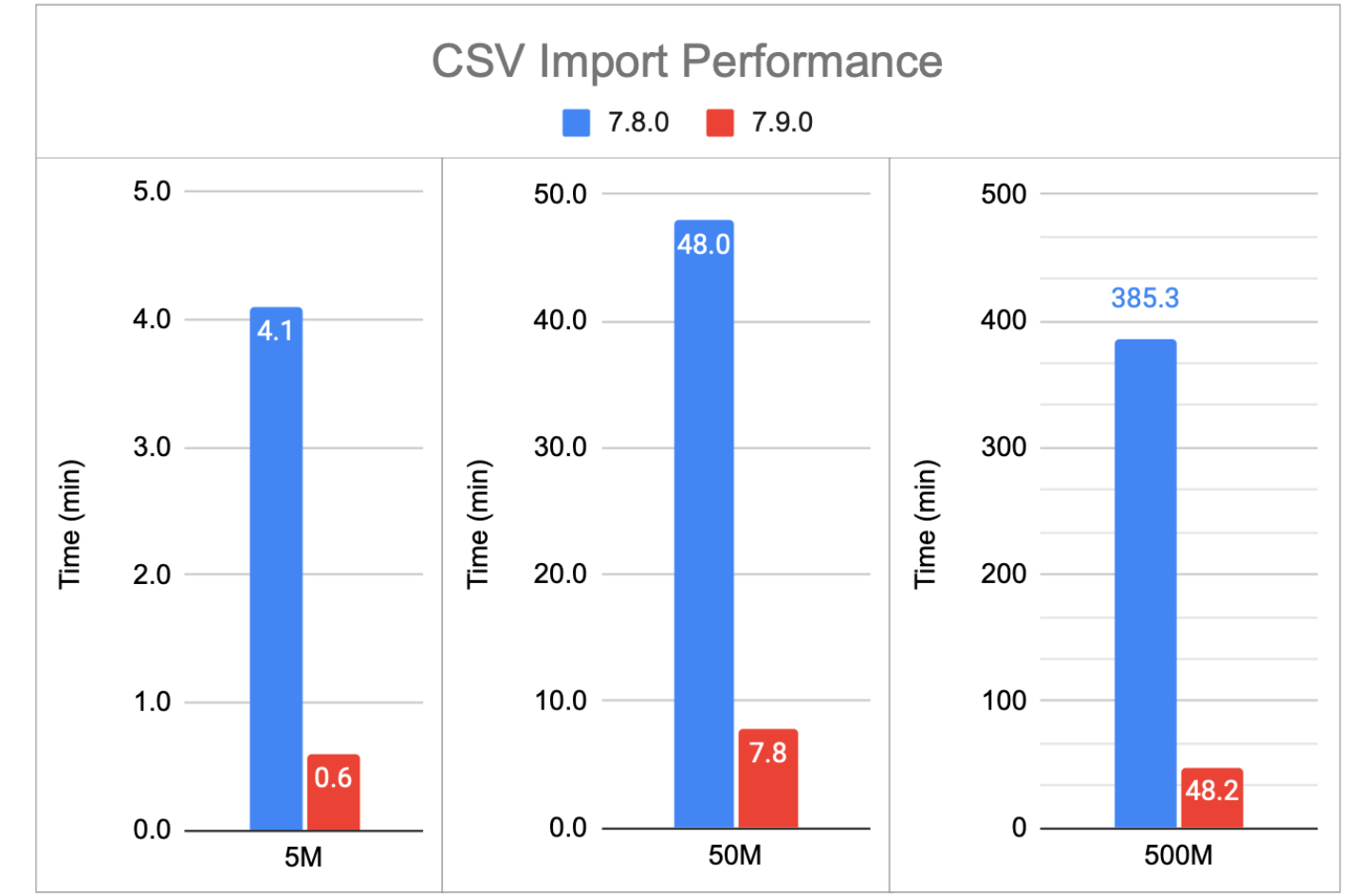
Stardog allows importing CSV files into Stardog directly using the same mappings for relational databases. However, CSV import performance was lacking compared to importing data from relational databases or loading RDF files into Stardog directly. Stardog 7.9 addresses this issue and brings CSV import times in line with the other loading methods. The following chart shows that 7.9 is 6 to 8 times faster importing CSV files regardless of the file size.
Joins involving OPTIONALs
As explained in a recent blog post join keys bound in OPTIONAL patterns can cause serious performance problems. For example, consider the following example that is querying for people and optionally the company they work at:
SELECT * {
?person1 a :Person
OPTIONAL { ?person2 :worksAt ?company }
FILTER(?person1 = ?person2)
}
This query before 7.9 caused loop joins in the plan and was too slow. It would be of course more natural to write this query using a single ?person variable instead of using a equality filter but when queries are auto-generated, for example, by our BI/SQL endpoint this might not be possible. In these cases, we want the query optimizer to understand that OPTIONAL can be dropped and the query can be evaluated efficiently with an inner join.
Thanks to this optimization added in 7.9, the SPARQL or SQL queries with similar patterns are now finishing in under a second whereas same queries were timing out with 7.8.
Sampling Queries
The last thing we will cover in this blog post is not about making a specific operation faster but a new sampling feature we have introduced that provides a complete new way for querying the graph. Sampling allows the user to query a small subset of the graph to get answers very quickly.
Consider the case where you are trying to discover the implied graph schema by inspecting the relationships in the graph. A query to find all the properties used with a certain class, say Product, would look like this:
SELECT DISTINCT ?predicate {
?resource a :Product .
?resource ?predicate []
}
But this query needs to inspect every product in the graph and even for a modest graph with 10 million products this query takes several seconds to complete. However, it would be enough for us to look at a random sample of products and see what properties are attached to those products. So instead of using all the products we can use a sample in our query using this newly introduced service:
SELECT DISTINCT ?predicate {
SERVICE stardog:sample {
?resource a :Product.
}
?resource ?predicate []
}
This version of the query takes less than 100 milliseconds to complete and returns the same results. By default, the sampling service returns 1000 elements which might not be the right size for every task. If the sample size is too small to be representative for the complete dataset, the results with sampling would be incomplete compared to the results without sampling. There are several parameters that can be used with the sampling service to tune how the sample is created for your use case.
And More…
There are many other optimizations in 7.9 such as optimizations for FILTER EXISTS and non-selective full-text queries that we are not going into details in this post. We have also improved the cardinality estimations used by the query optimizer especially for the case where queries might be using rarely occurring entities. The list of all improvements can be found in the release notes. Give the Stardog 7.9 release a try and let us know in the Stardog Community the performance results you see.
Keep Reading:

Unified Process Monitoring
Did you ever have a slow query, export or any other operation and wondered “Is this ever going to finish?!”. Many operations such as SPARQL queries, db backups etc have performance characteristics which may be hard to predict. Canceling rogue queries was always possible, but there was not yet a way to do so for other potentially expensive operations. If this ever affected you then the new unified process monitoring feature we added in Stardog 8.

Chaos Testing Stardog Cluster for Fun and Profit
At Stardog we work hard to build software that’s not only performant but also extremely robust. Stardog Cluster is a highly available, key component to ensuring Stardog remains up and running for our customers. However, every distributed system is susceptible to faults and bugs wreaking havoc on it. Most software testing checks the “happy path” through the code to verify it behaves as designed. Moving a step further, tests can check some obvious failure cases; for example, if one service in a deployment is terminated.
Try Stardog Free
Stardog is available for free for your academic and research projects! Get started today.
Download now