Stardog is excited to announce our partnership with Databricks. Starting Aug 24th, Stardog is available on Databricks Partner Connect!
Stardog users have accessed data from Databricks for quite some time using the Databricks SQL end-point. This integration makes it faster and easier for Databricks users to get started on a path toward building a semantic data layer on top of the Databricks Lakehouse Platform. Now, as an existing Databricks user, you can launch a new instance of Stardog Cloud using your Databricks credentials.
Databricks Partner Connect makes it easy for you to discover validated data, analytics, and AI tools directly from within the Databricks platform — and quickly integrate the tools you already use today. With Partner Connect, you can simplify tool integration to just a few clicks and rapidly expand the capabilities of your lakehouse.
Together with Databricks and Stardog, you can:
- Harmonize your data by turning columns into concepts across domains as part of a semantic data model that sits as an abstraction layer between the storage and consuming applications inside the enterprise.
- Enable data sharing and re-use through a common, standards-based vocabulary.
- Ask and answer questions across a diverse set of connected domains inside and outside the lakehouse to fuel business insights without requiring IT skills.
- Discover new patterns and data relationships based on rules defined by business users.
- And quite a lot more!
Here’s a quick overview of how easy it is to start building your semantic layer from the data already in your lakehouse from within the Databricks Partner Connect portal.
How to Launch Stardog from Databricks Partner Connect
Within Databricks, slide open the left tray and select Partner Connect.


Once you find and select the Stardog Tile, you will see the connection options per the screenshot below. You can select the SQL warehouse and schemas to add along with the relevant privileges that will be granted to the Stardog Instance.

Clicking the “Connect to Stardog” button will take you to the Stardog Cloud Portal. Complete the sign-up process to instantiate and select your new Stardog instance in the Cloud. All the details about your Databricks workspace and SQL EndPoint are enabled during the sign-up process. This allows you to start using the workspace by creating a new datasource.

Getting Started with Databricks and Knowledge Kits
Databricks workspaces come with sample datasets, as described in their documentation and tutorials — NYC Taxi and TPCH (Retail) datasets specifically. These are also included as sample dashboards.
As a first-time user, when you instantiate Stardog via Partner Connect, we install two semantic models out of the box as part of our pre-fabricated knowledge kits for these sample datasets. What’s a knowledge kit, you ask? Essentially, our way of pre-packaging semantic data models, synthetic data, pre-built queries, and mappings that can be deployed and used with a push of a button!
It’s easy to start exploring your newly created sample knowledge kit with our Stardog Explorer web application. Setting up Explorer for the Databricks knowledge kit requires a few settings after you open up Explorer**.**

Don’t know where to go first? Just hit “visualize” and see the definition of the semantic layer, i.e., the data model.

The beauty of the semantic layer is that you can dive directly into the data by double clicking or using the right click to see specific instances or relationships. Every search behind the scenes pushes queries down to Databricks where the data lives. Using our Data Virtualization engine, we translate the graph queries into Databricks optimized push-down queries via the Databricks SQL endpoint. You may see some lag as the demos are not optimized for production style use, but meant to demonstrate the value of creating a semantic data layer to enable search and exploration for broader data democratization and sharing of knowledge for citizen data users.

Our starter kit is actually incomplete. As a user, you would like to visualize data in the context of a region, a concept that, while currently exists in our model, has no data associated with it. There’s a table region in the source (in this case, your Databricks workspace) that has not been mapped. We can quickly and easily extend our knowledge graph to add this new information.
To go through this exercise, you will open up Stardog Designer, a visual, no-code/low-code web application to help define and extend your semantic data model and map to your rows and columns across your data silos. Let’s start by creating a new project. In the canvas, we will begin by adding the existing Model Resource to the project. Select your existing server, database, and tpch model. This will import that data model we looked at earlier for us to reuse**.** It looks exactly like it did in Explorer, except more like a whiteboard.
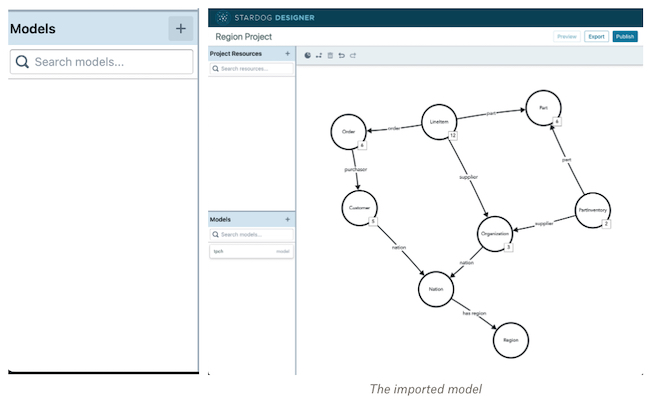
Now we want to connect to an existing data source. We do this by:
- creating a project resource
- and selecting Databricks as your source type
You should see two Databricks sources for NYC Taxi (the other dashboard example) and TPCH. Select TPCH. This will drill into the TPCH database and show you the list of tables that can be mapped. If you are SQL-savvy, you can DIY with a SQL query and map that, but it’s easiest to map table by selecting the table from the drop-down list. You select the region table and add it to our project.

From there we can create a new mapping for this table, and associate it with the existing Region concept. We need to set the primary key, and the labels for our regions. and we’ll add a single attribute, the region name and map that to the name column in the table.
Region is mapped, but it’s not connected. Regions are connected to nations, so let’s add another project resource, same as last time, except we’re going to map something from the nation table.
Once we have nation in our project, we can create another mapping to the has region attribute. we select nation’s primary key in the table, and the foreign key for region to complete the mapping.

We can publish this back to the same database we were using using the “Publish” button on the canvas.

Now, when we go back to Explorer, we can see our new, larger knowledge graph!

For those interested in looking a bit more under the hood, we have our Stardog Studio IDE where you can see the same queries in Databricks against the sample TPCH data source and Dashboard.
Databricks Dashboard is a collection of SQL queries. We ported them into our semantic graph queries that you can run and see the same results. You can also see the plans and see the SQL execution statistics.

You now have your first Semantic Layer built with an Enterprise Knowledge Graph foundation. To learn more, check out our tutorials, videos and other knowledge kits. Happy Exploration!
