NLP Pipeline
Our NLP pipeline, BITES, allows full-text documents to be combined alongside traditional data sources, enriching the body of data
Unify clinical data, scientific research, real world data, and more to accelerate drug discovery.
Start for FreeIn pharmaceutical companies, data definitions and schemas can vary significantly from lab to lab, even if those labs are working on related experiments. This can leave researchers operating with incomplete information, which can lead to duplicative efforts and wasted budgets. Stardog provides the highly flexible data layer organizations need to make data findable, accessible, interoperable, and reusable (FAIR) and repeatably identify promising drug targets.
Stardog connects all R&D data to let researchers explore the relationships between data in studies, trials, populations, expressions, diseases, and more. Thanks to virtualization, all of this can be done without moving any data between labs. With data unified, researchers can more easily find compounds which create similar effects, see which assays have already been tested, and understand if gene expression could be used as a biomarker.
Scoping new experiments typically requires manual data preparation to gather relevant previous studies and experiments. As a result, researchers are slow to form hypotheses for the basis of experiments, wasting time and resources on inefficient or ill-formed experiments. With Stardog, the full breadth of relevant research, internal and external, is readily available. Stardog’s traceability allows researchers to follow their intuition and explore related datasets to help form their hypotheses.
Help mitigate your costs by repositioning existing drugs. Using similarity search, researchers can find related drug areas in the Knowledge Graph and predict relationships and pathways with ML models trained on the full breadth of available research. Stardog also supports virtualizing large volumes of external research and extracting details via our NLP pipeline, BITES.
Our NLP pipeline, BITES, allows full-text documents to be combined alongside traditional data sources, enriching the body of data
Stardog’s Data Quality Constraints find inconsistencies across your data silos and flags conflicts
Stardog’s query results include full data lineage for easy interpretation and flexible discovery by research scientists
Stardog easily incorporates new biomedical data and ontologies into a common data model and language, allowing for easy iterative development across any R&D team
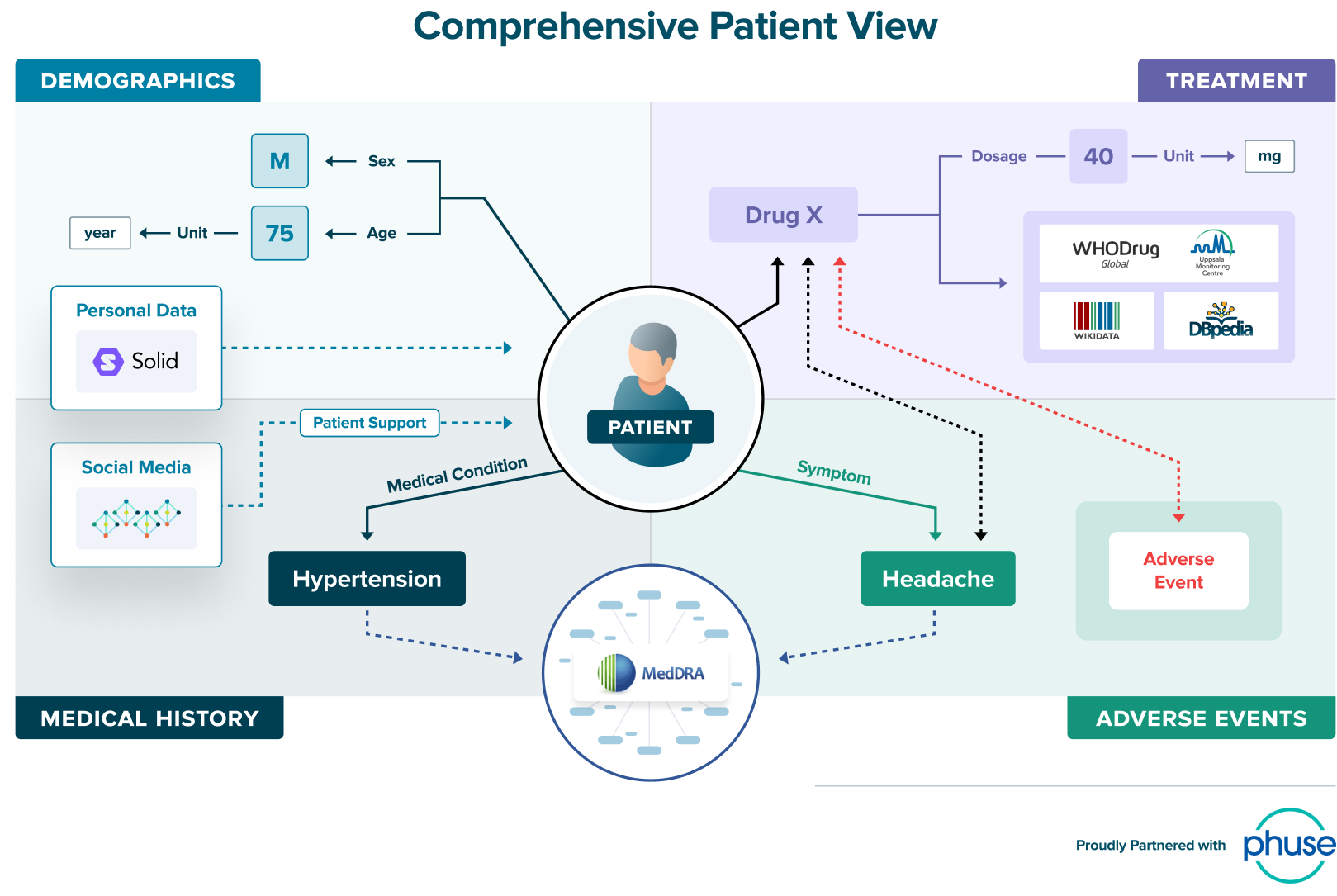
In this joint PHUSE & Stardog webinar, learn how knowledge graphs achieve FAIR in addition to delivering a patient-centric approach.
READRead more

Read on to learn how knowledge graphs make data FAIR, how knowledge graphs compare to other data management technologies, and how one leading global pharma succeeded in their FAIR transformation.
READRead more

Read on to learn how Boehringer Ingelheim is using Stardog to transform their data lake into a FAIR data enabling data foundation, all thanks to knowledge graph.
READRead more
See how Stardog builds shared meaning and trusted context across your existing stack, connecting data from MDM, data integration, data catalogs, warehouses, and graph databases for analytics and AI enablement.
