The point of a knowledge graph, which is to integrate and analyze enterprise data better by using machine-understandable semantics, is also an impediment to adoption. Most people just don’t know semantic graph data modeling, graph query, inference rules, and data quality languages well enough to implement an enterprise knowledge graph (EKG). But typically they do know the meaning of their enterprise data; not perfectly, of course, but good enough. While knowledge graphs provide powerful abstraction, it’s still a family of languages to learn.
But we’re also at the beginning of a revolution in machine-understandable semantics powered by Large Language Model breakthroughs. I’m excited to share how Stardog Voicebox, powered by LLMs, will fundamentally flatten the EKG implementation cost curve.
Introducing Stardog Voicebox: LLM-powered Knowledge Graph
LLMs present a whole new way for us to think about the challenge of offering a powerful, flexible natural language interface to Stardog. Here’s a session with Stardog Voicebox in Stardog Cloud’s R&D environment, which we call Doghouse:
$ python3 svbx.py query -t doghouse -d training_c360 "what is the name of the most expensive product?"
Based on the query result, the name of the most expensive product is "Digital Song".
$ python3 svbx.py query -t doghouse -d training_c360 "what is the distinct label of the department whose products have had the most total sales by price"
The department with the highest total sales by price is the Electronics department.
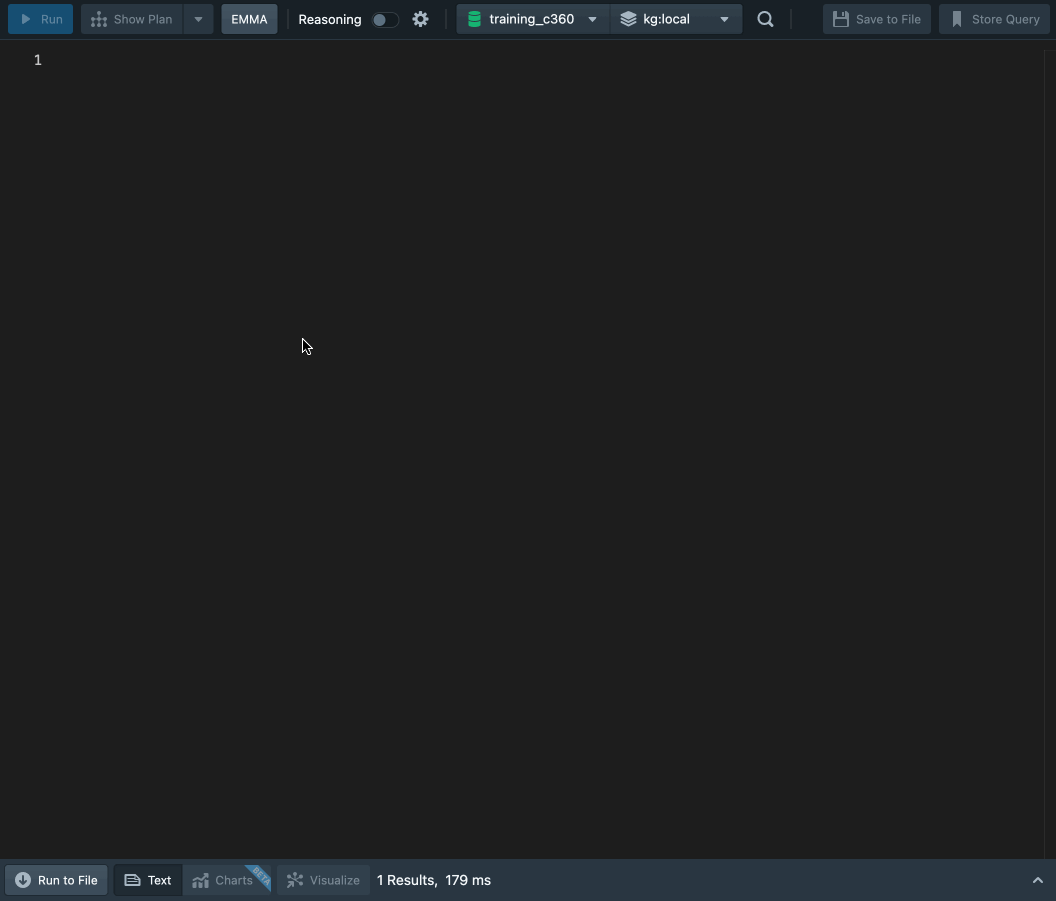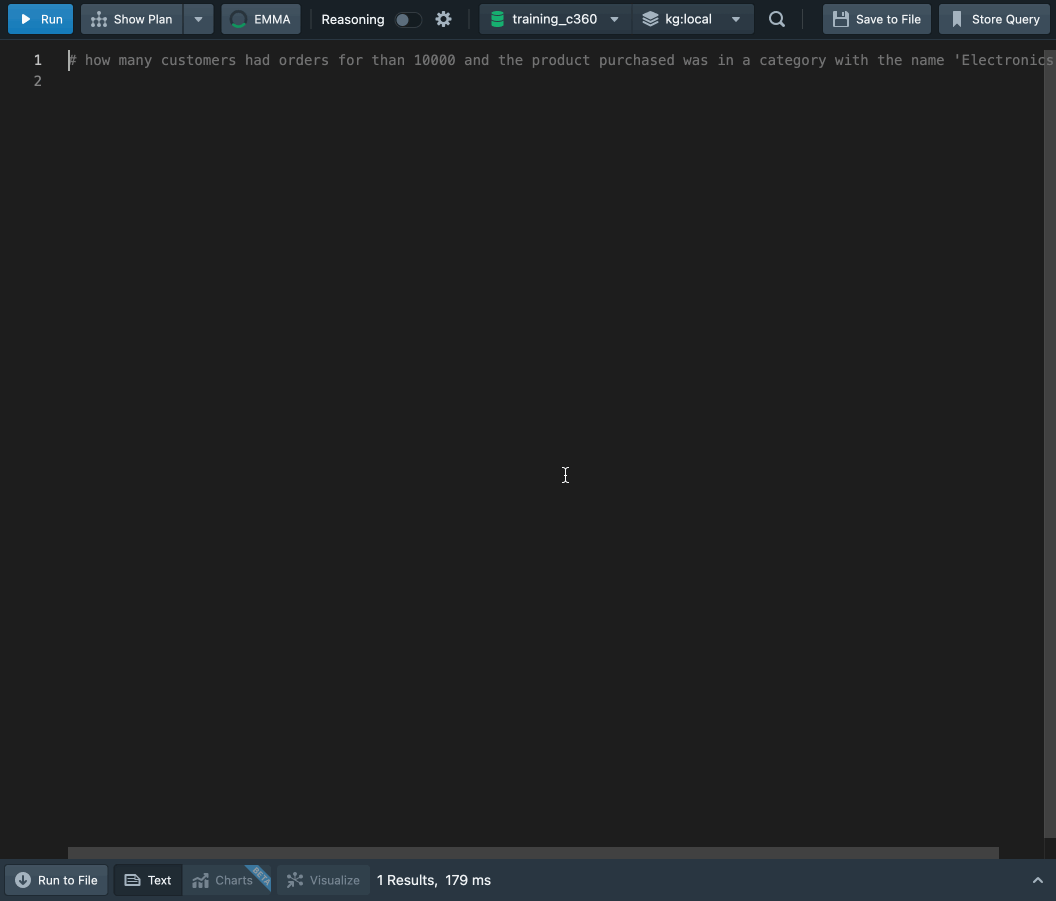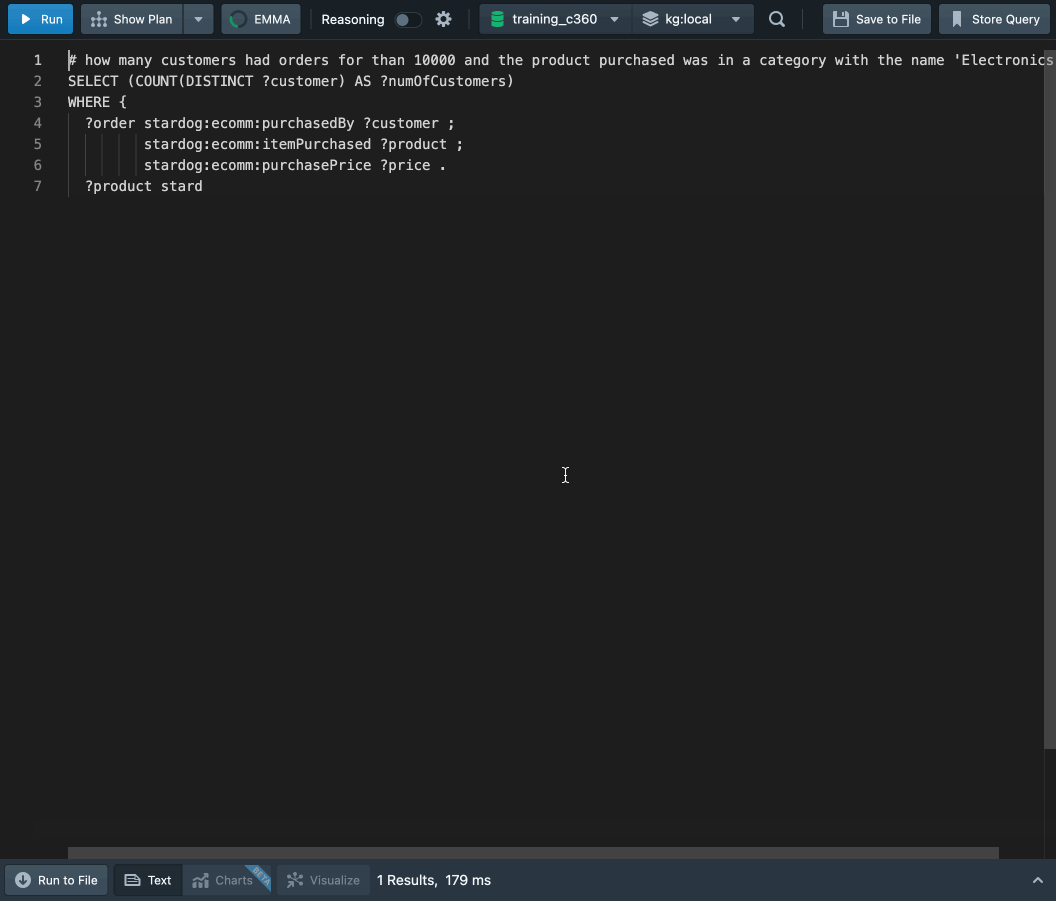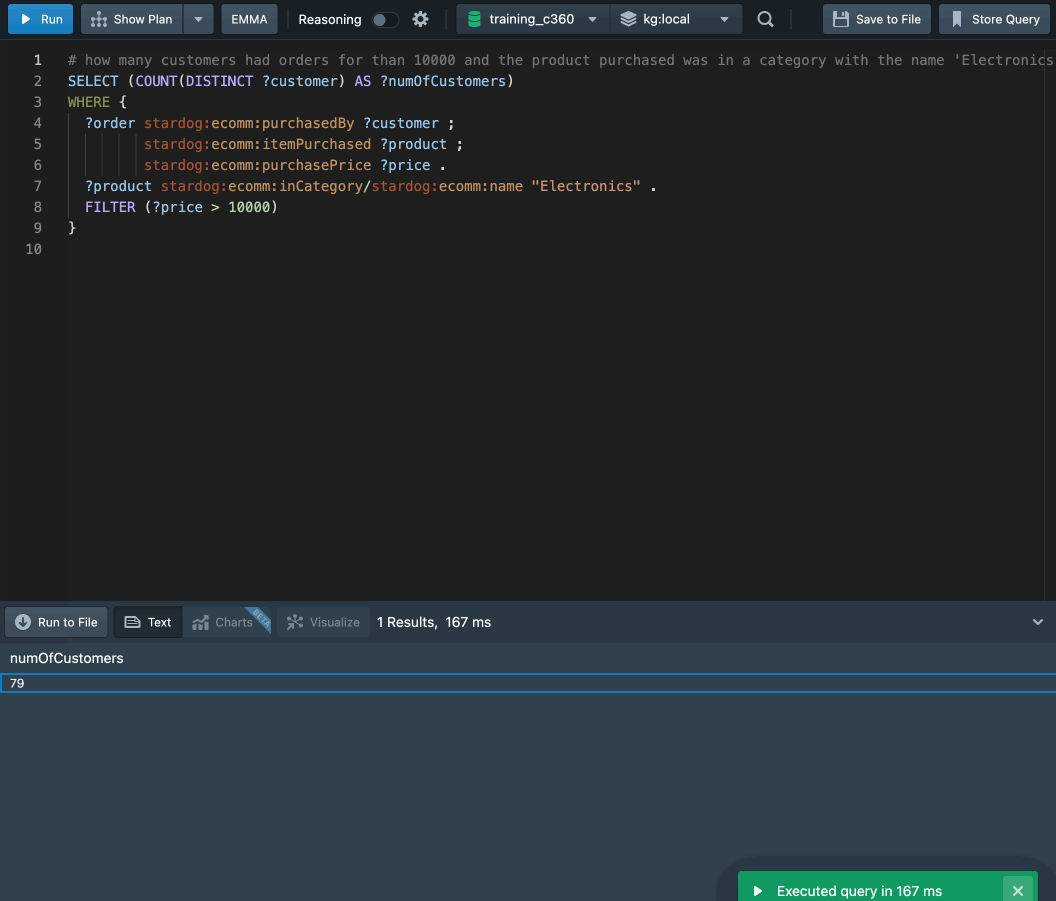
$ svbx.py query -t doghouse -d training_c360 "how many customers purchased orders for more than 10000 and the product purchased was in a category with the name 'Electronics'"
Based on the query result, there were 79 customers who purchased orders for more than 10000 and the product purchased was in a category with the name 'Electronics'.
This one is my favorite because it requires Voicebox to generate a pretty tricky 50-line SPARQL query that I had a bit of trouble with myself:
$ python3 dev/svbx.py query -t doghouse -d training_c360 "for the separate total sales December 2020 and for December 2021?, which sales was higher"
Based on the query result, the total sales for December 2020 were higher than the total sales for December 2021.
+------+------------+
| year | totalSales |
+------+------------+
| 2020 | 2815406.0 |
| 2021 | 2796838.8 |
+------+------------+
And here’s an example session inside Stardog Studio:
LLM generates SPARQL from Natural Language Inputs
What’s happening under the hood is we are generating a prompt context that encodes the data model of a Stardog knowledge graph in such a way that the LLM is able to understand how it is put together. We then combine that with template-driven prompt engineering that includes relevant additional context, and we’re able to get sophisticated queries generated and then evaluated in the ordinary way.
Here’s an example of what’s generated for a different input:
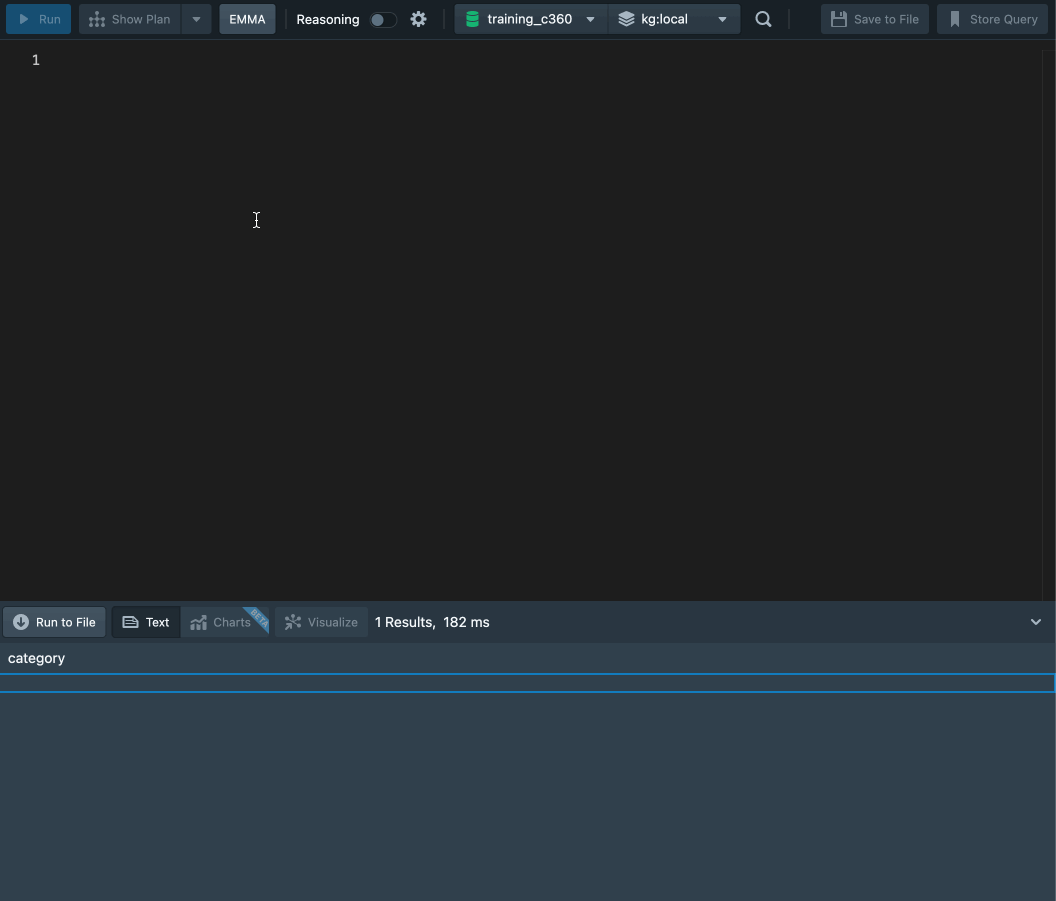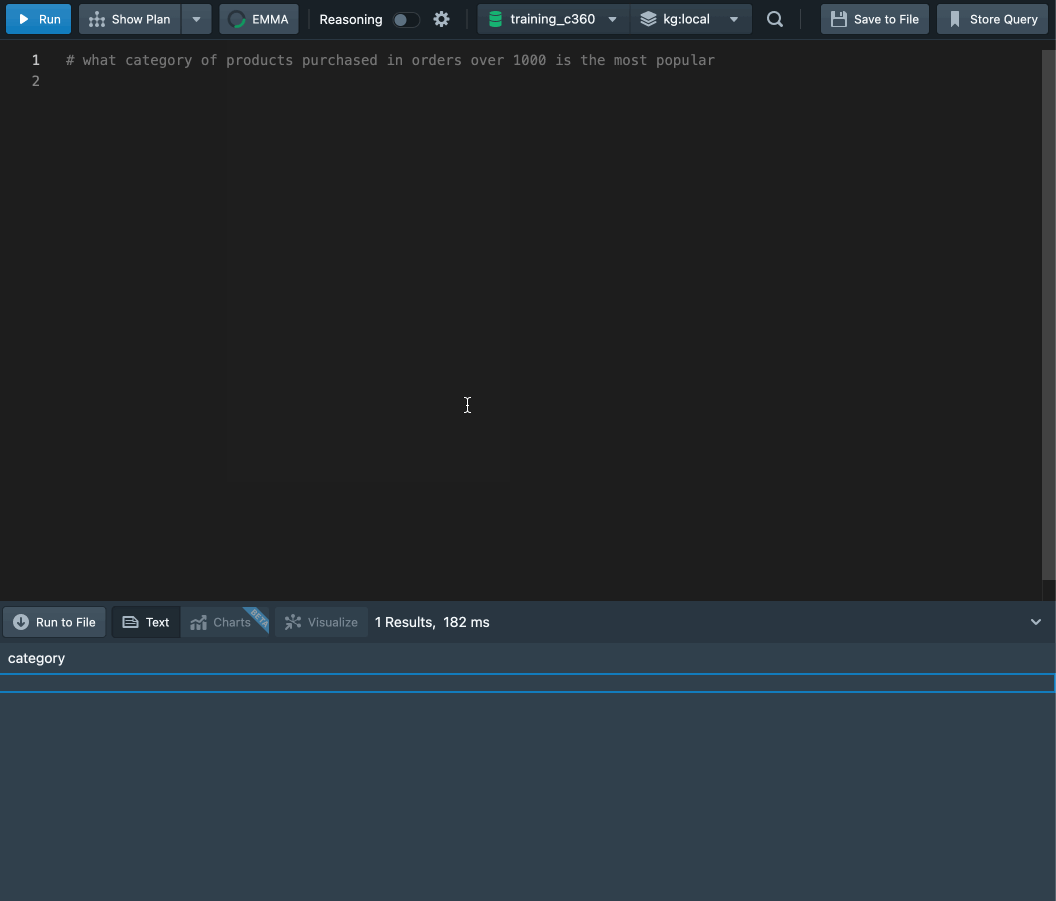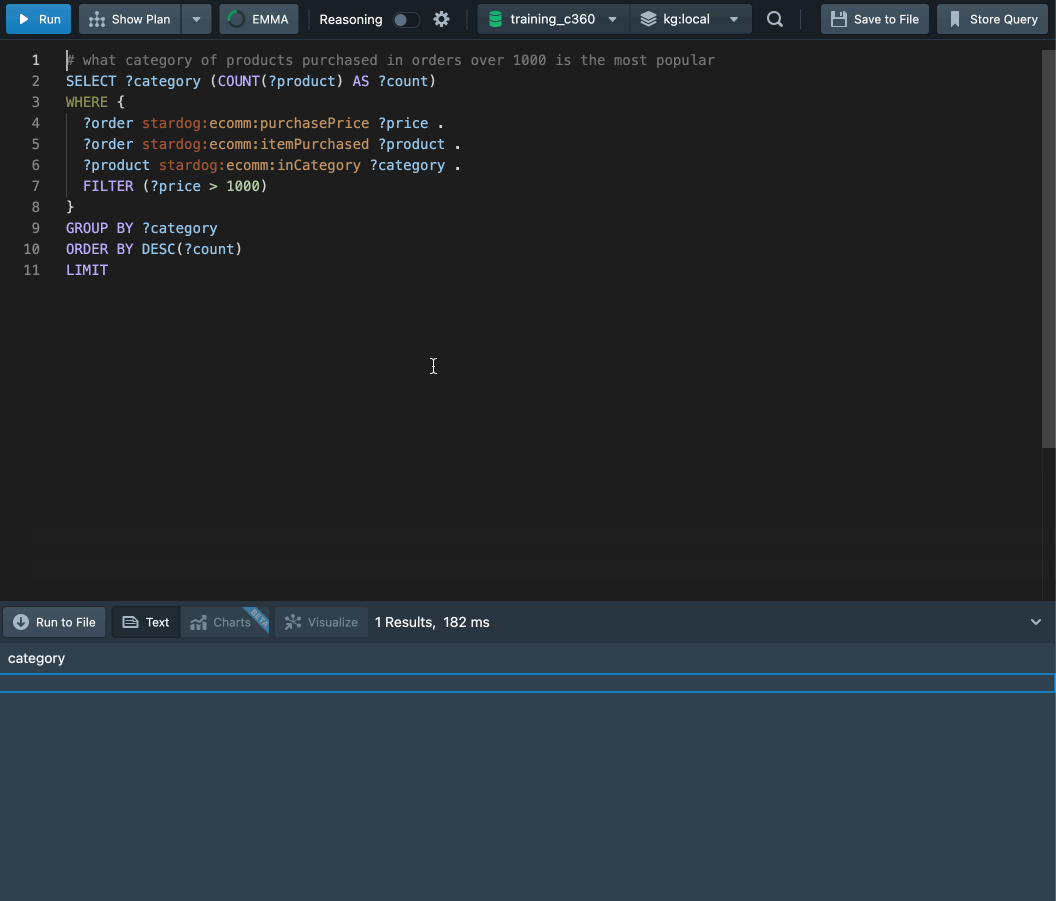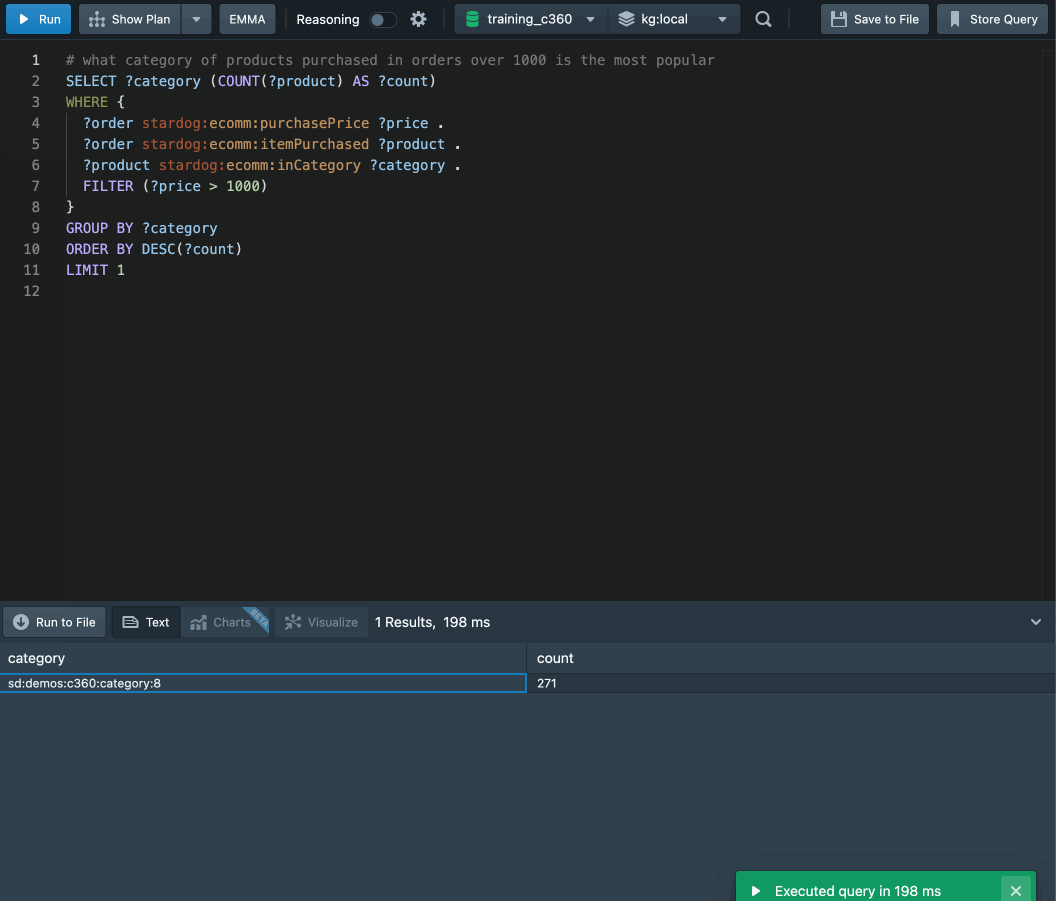
I think the results speak for themselves. Stardog Voicebox offers a friendly natural language query interface that can represent and perform complex queries including things like aggregations and comparisons.
A Natural Conversational Interface for Stardog
The design goal for Stardog Voicebox is an ordinary language, conversational interface for Stardog EKG such that the real-world semantics that people understand can be gotten into machine-understandable semantic graphs, and vice versa, as naturally as possible. That means, in part, taking query results and providing that back to Voicebox to get an ordinary language summarization:
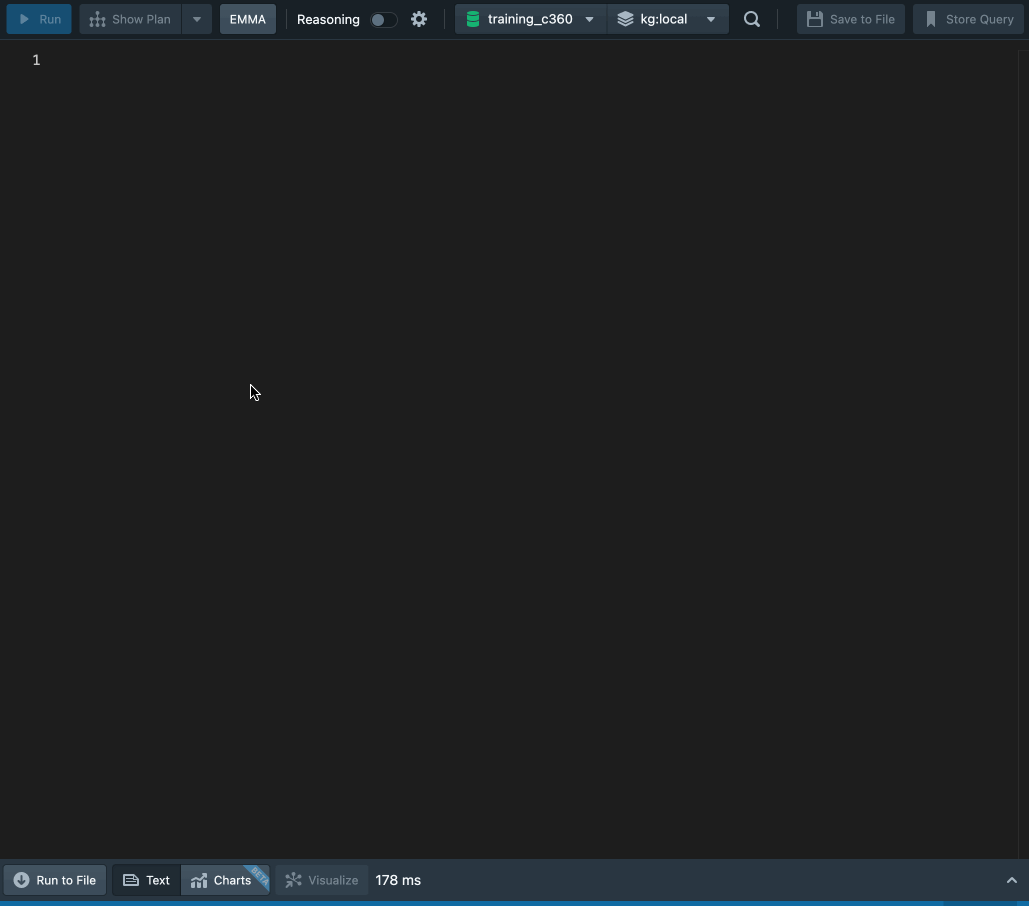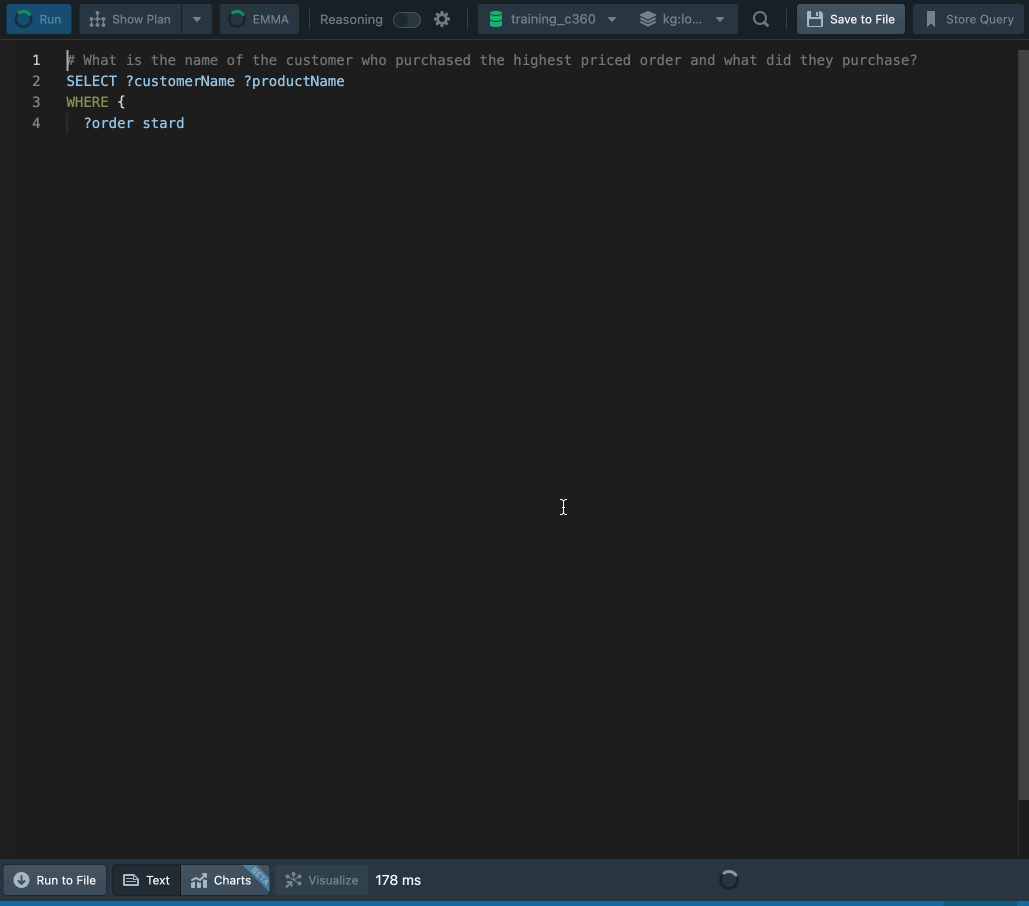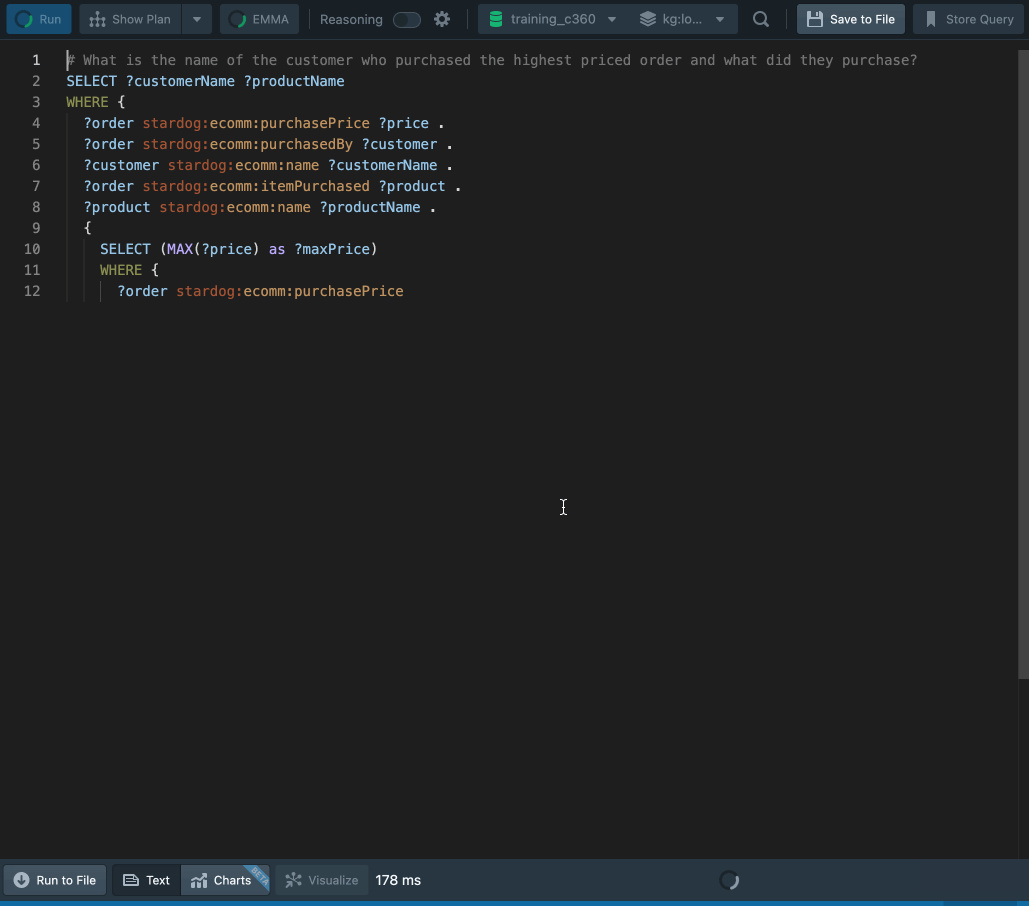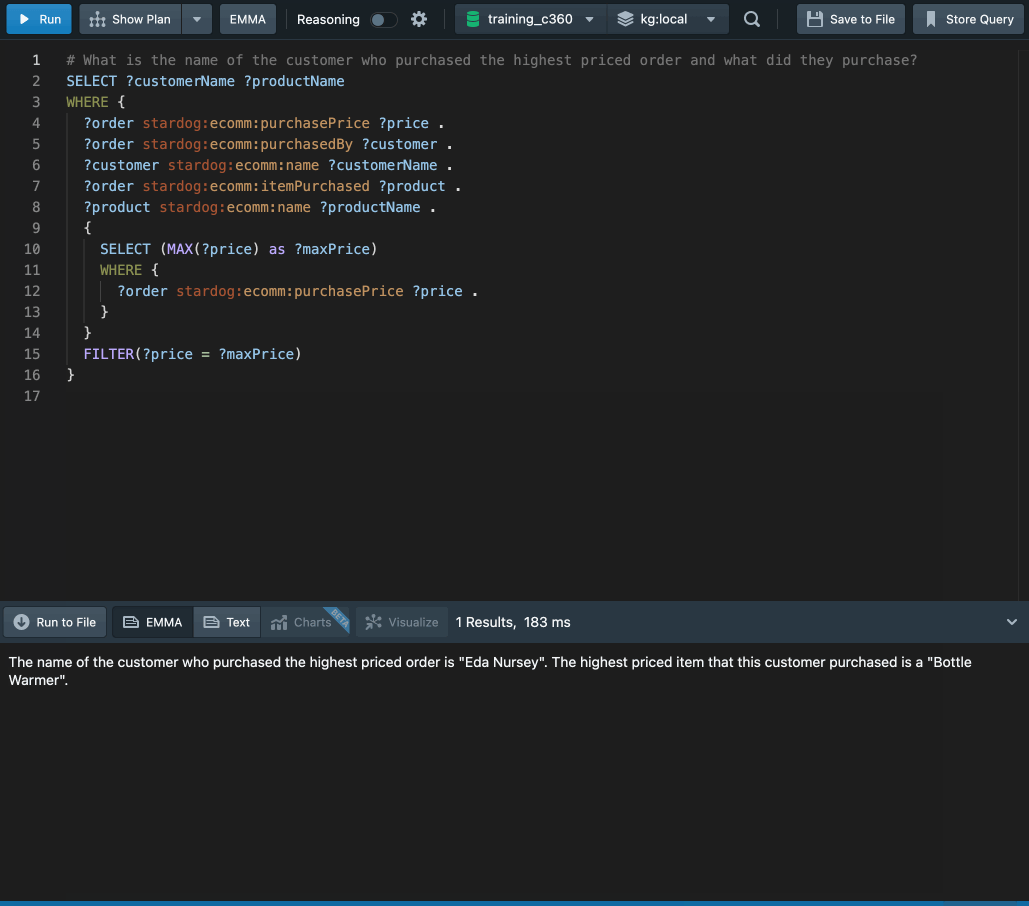
This way of interacting is elegant, ordinary, and has the accessibility of natural language backed by the precision and expressivity of Stardog.
Accelerating Data Modeling with Stardog Voicebox & LLM
Stardog Designer is an amazing tool for building data models. But for all the great things I can say about Designer, it still requires people to at least extend a model using a Knowledge Kit or to build one from scratch. How can we accelerate the earliest days of model building (and model maintaining, too) with Stardog Voicebox?
When we talk to Designer users, they always have a notional model in mind. Given that everyone has a starter prompt, we thought we could add data modeling to Stardog Voicebox, powered by LLMs. Stardog Voicebox is integrated with Designer and the early UX prototype looks like this:
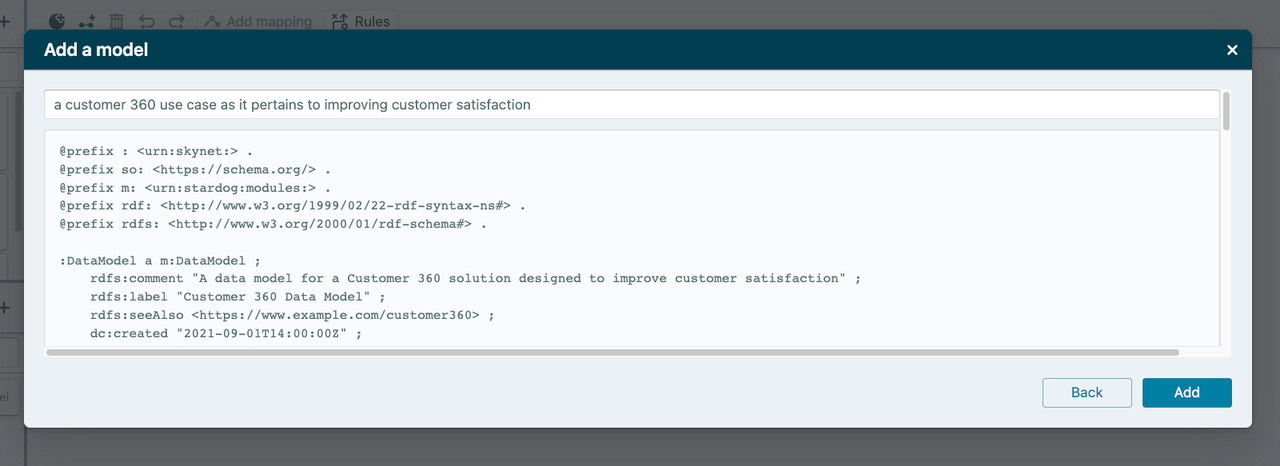

We’ve prompt-engineered and trained LLM to, again, turn ordinary language inputs into a Stardog Data Model, which has the following constraints (for now):
- Derived from RDF, including the notion of classes, and properties, arranged in a hierarchy; properties come in two flavors:
- Relationships, aka
owl:ObjectPropertyand - Attributes, aka
owl:DatatypeProperty
- Relationships, aka
- Uses limited OWL expressivity
- Transitive, symmetric, and inverse relationships for properties
- Equivalence for classes and properties
- All classes and properties include human friendly short labels, long form comments that describe the class/property, and a short usage example
- Domains and ranges of properties use schema.org’s
domainIncludesandrangeIncludesas opposed to the traditional, and oft-misused,rdfs:domainandrdfs:range - Defines the model itself
- There is a meta-relationship that represents the model itself, which should have metadata associated with it like a summary, timestamp, and author; all of this will be inserted into the Stardog Knowledge Catalog
- Defines icons for concepts using our standard visual design language for Stardog Cloud
Of course the resulting, bootstrapped data model can be further refined in Stardog Designer. Of course the more you say in prompting Voicebox, the better the results. We’ve found being explicit in prompting helps as does iterating.
In less than 5 minutes, I generated a starter data model, added an additional concept, and added a rule using the generated model and my new concept to infer new data about my domain:
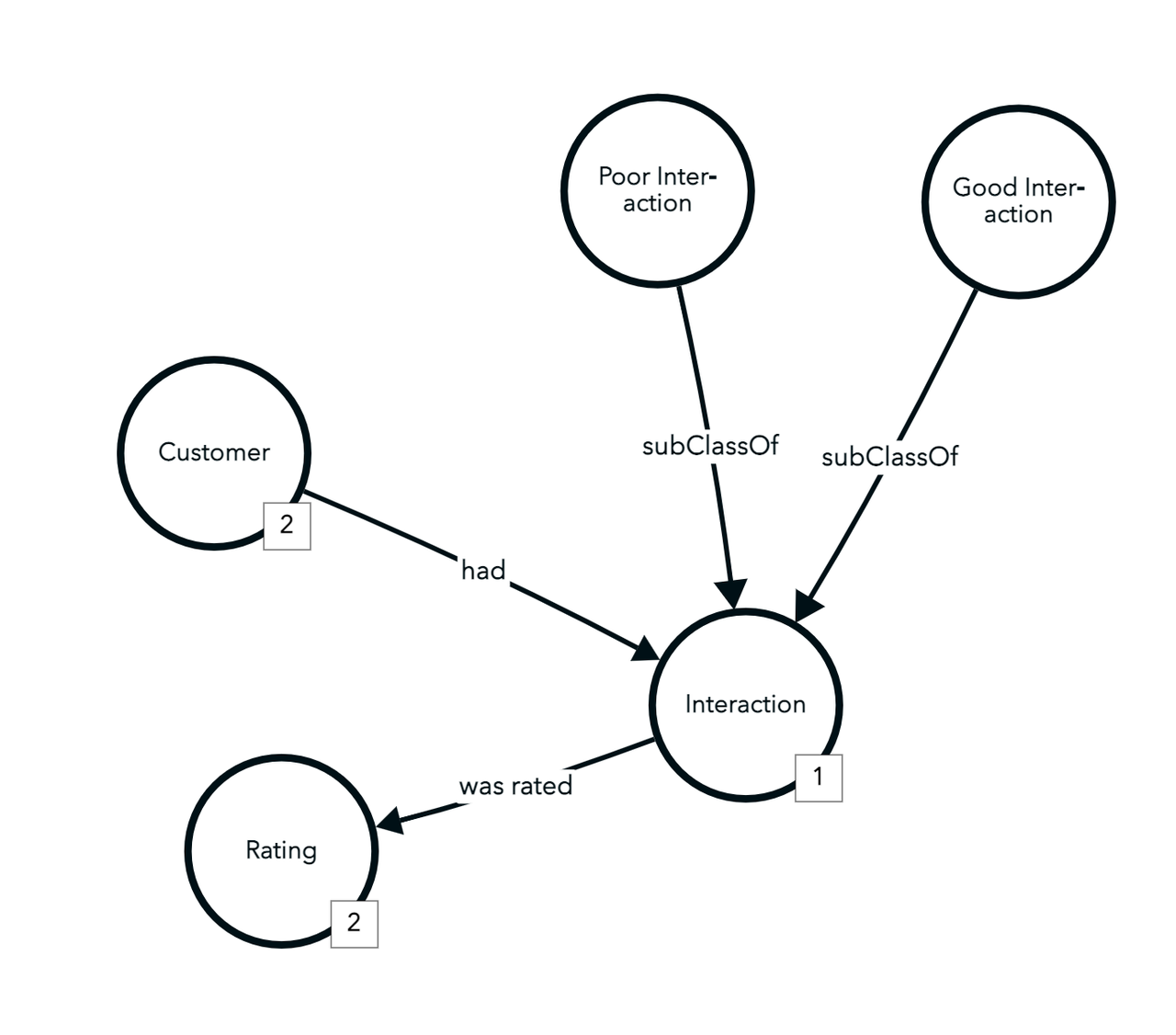

Making LLM do the debugging for us, too
Under the hood, of course, Stardog Voicebox is generating things like SPARQL and Turtle; arguably the point of Explorer and Designer is to prevent users from having to learn those (and other) languages before being productive in Stardog. Fortunately, Voicebox knows a bit about this stuff.
So instead of relying on people to suggest fixes in a follow-up prompt, Voicebox goes into an automatic debugging session. We pass it the error message, what it gave us that was problematic, what we were trying to do originally, and ask it for help. If that doesn’t work, we try again. As we iterate, we increase the temperature of the response to increase randomness to get unstuck.
Here are a couple examples taken from Voicebox CLI that shows it debugging itself, pulling out of an error, and finally recovering to provide the correct result.
$ svbx.py model "logistics for a car manufacturer for a digital twin of their car door assembly line"
Looks like there was an error generating your model ('at line 14 of <>:
Bad syntax (Prefix "dc:" not bound) at ^ in:
"...b' a digital twin of a car door assembly line logistics." ;\n '^b'dc:creator "Car Manufacturer X" ;\n dc:created "2022-01-01T0'..."
)
Let me try again...
Here's a revised data model:
@prefix : <urn:skynet:> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix so: <https://schema.org/> .
@prefix dc: <http://purl.org/dc/terms/> .
@prefix m: <urn:stardog:modules:> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
:DataModel a m:DataModel ;
rdfs:label "Car Door Assembly Line Logistics" ;
... and so on ...
Here’s an example of self-debugging an invalid, generated SPARQL query:
$ svbx.py query -t doghouse -d MDF "what is the label of the customer who purchased the most expensive order and what did they purchase?"
Looks like there was an error in the original query ([400] QE0PE2: com.complexible.stardog.plan.eval.ExecutionException: Invalid SPARQL query: Encountered " "count" "COUNT "" at line 9, column 8.
Was expecting one of:
"(" ...
"*" ...
"reduced" ...
"distinct" ...
<VAR1> ...
<VAR2> ...
).
Trying again...
The label of the customer who purchased the most expensive order is Davon Cullum. They purchased an Electric Tiller at a price of 24992.5.
+---------------+-----------------+---------+
| customerLabel | productLabel | price |
+---------------+-----------------+---------+
| Davon Cullum | Electric Tiller | 24992.5 |
+---------------+-----------------+---------+
In Conclusion
Voicebox will dramatically shorten the time to value for an Enterprise Knowledge Graph.
Voicebox is an expert Stardog user and can handle the low-level details of crafting SPARQL queries, building data models, writing inference rules, etc, which allows human users to focus on what matters: what their enterprise data means and unlocking the insight it contains.
As you can see, we’ve already got some basic integration within both Studio and Designer, and the Explorer integration is well underway. If you want to see this in action, we’ll have Voicebox open for anyone to use at our booth at the upcoming Knowledge Graph Conference, where we will also talk more about our plans for the semantic-powered future of data management. You can also use our non-LLM powered chat app on our site to get in touch with our team and arrange a demo.
