Stardog recently released a Knowledge Catalog as part of its knowledge graph platform, which quickly harvests enterprise metadata with integrations for Databricks Unity, Collibra and Microsoft Purview Data catalogs, and any JDBC-accessible data source.
These integrations make it easy to semantically enrich technical metadata with business concepts and enable Data Governance teams and end users to easily search, query, and explore available data assets with an Enterprise Metadata Knowledge Graph.
Why Organizations Struggle to Understand Their Data
Organizations continue to struggle when it comes to understanding the value of their data assets, largely due to three key reasons:
- Heterogeneity of the location and structure of the data.
- Lack of business context. For example, understanding “what does the data mean and how can I use it for my business needs?”
- Misaligned internal objectives that often clash when it comes to agreements around common definitions among different data teams and data domains.
Modern Data Platforms have come a long way in creating a searchable inventory of all their technical metadata via a Data Catalog, useful for a technical persona to understand everything about the system and its associated metrics - workspaces, tables, columns, identifiers, usage, etc. We see this with Glue on AWS, Purview on Azure and Google’s Data Catalog on GCP.
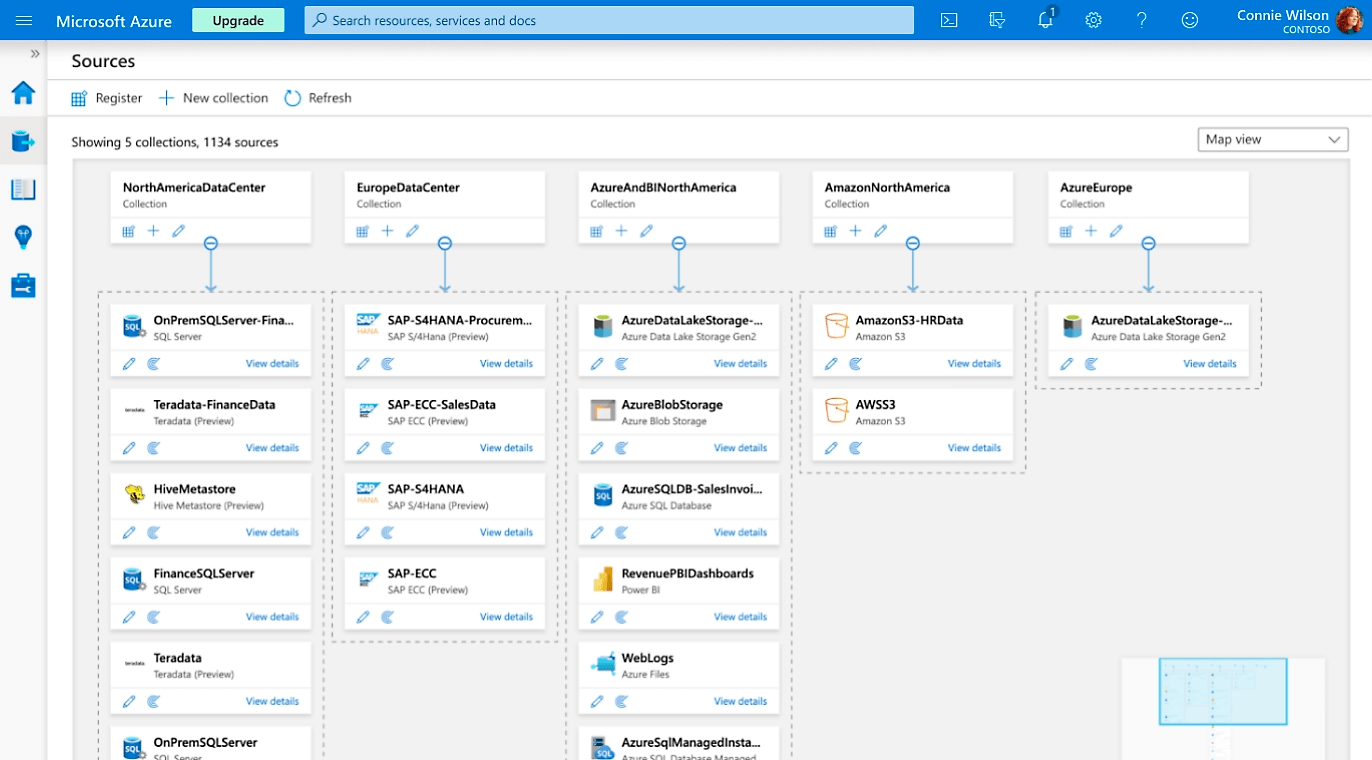
But, in any given enterprise, we know data lives beyond a single cloud vendor’s offerings or even a single data platform. In fact, data is often across cloud providers and even across multiple data platforms, whether in the cloud or on-prem. Some software vendors offer the ability to consume, classify, and catalog metadata across multiple data platforms with the goal to inventory all the technical metadata in order to help a technical user make sense of their data universe by tracking lineage, understanding the usage, and making decisions around planning and operations, but what they lose is the business context that lived in the source systems.
On the other hand, other vendors have taken a top-down approach with the goal of tying the technical metadata to a business glossary that can address the challenges around context and business alignment, ultimately tying it to business value and objectives. This approach can become difficult to scale as more functional areas are involved in decisions by committee, often leading to adoption by one business unit or functional area.
Either approach, whether bottom-up or top-down requires investment in additional resources — outside of existing data platforms — to build and maintain, adding more complexity in the modern data landscape, designed for technical users and with a focus ultimately on just metadata, meaning users still must query the underlying data platforms to answer business questions.
One of the key opportunities to this form of metadata governance is to look at ways to activate metadata that feed into principles of data sharing and provide a level of abstraction, automation, and governance that focuses the collaboration around data that is important to answer the most pressing set of business questions. In other words, metadata is enriched with semantics that democratizes data access with business context and enables an understanding of data lineage through that lens.
Activated Metadata with Stardog
Use Stardog to quickly harvest enterprise metadata with integrations now available for Databricks Unity, Collibra, Microsoft Purview Data catalogs, and any JDBC-accessible data source! Stardog’s Knowledge Catalog harmonizes metadata across catalogs and/or sources, utilizes the harvested metadata to help users define new business concepts, and automates modeling and mapping that can be annotated with business logic, enabling users to ask business-relevant questions without regard to the underlying structure and location of the data itself. Because the Knowledge Catalog captures all the metadata, including source, mappings, and usage, multiple user personas benefit from this insight:
- Data Governance teams get the ability to query, visualize and explore their entire data landscape to help them understand important aspects like ownership, quality and lineage.
- Data engineers get to easily identify and apply data in the service of business objectives.
- Data scientists get to identify new sources of relevant data to improve feature engineering for machine learning model development; for example, querying for where to find “geo-location” data across the enterprise data landscape.
- Data architects get to identify priority sources of data to consider as part of the cloud migration planning process and inversely consider shutting down data sources with low utilization.
Check out a quick overview of our Knowledge Catalog here:
The future is here
Stardog Voicebox, our newly launched product built on Large Language Models, brings a conversational interface to our knowledge catalog, making it easier for these user personas to ask natural language questions of the catalog like:
“Show me all the columns for a given table in a given datasource” 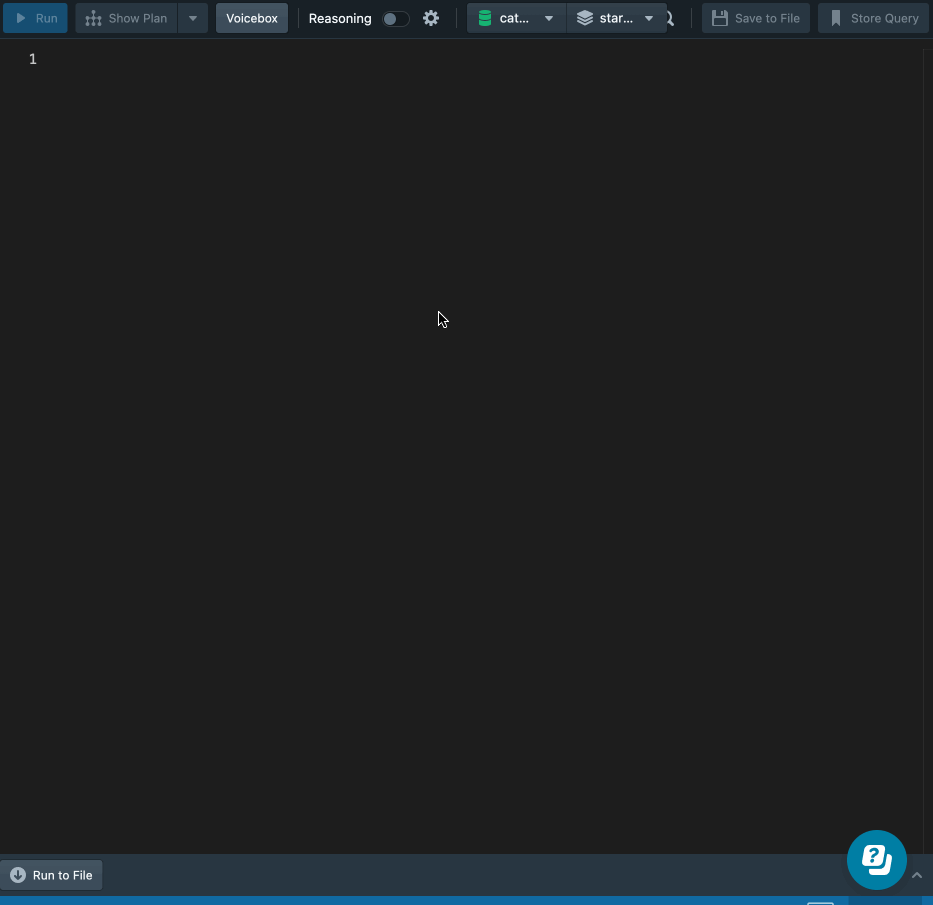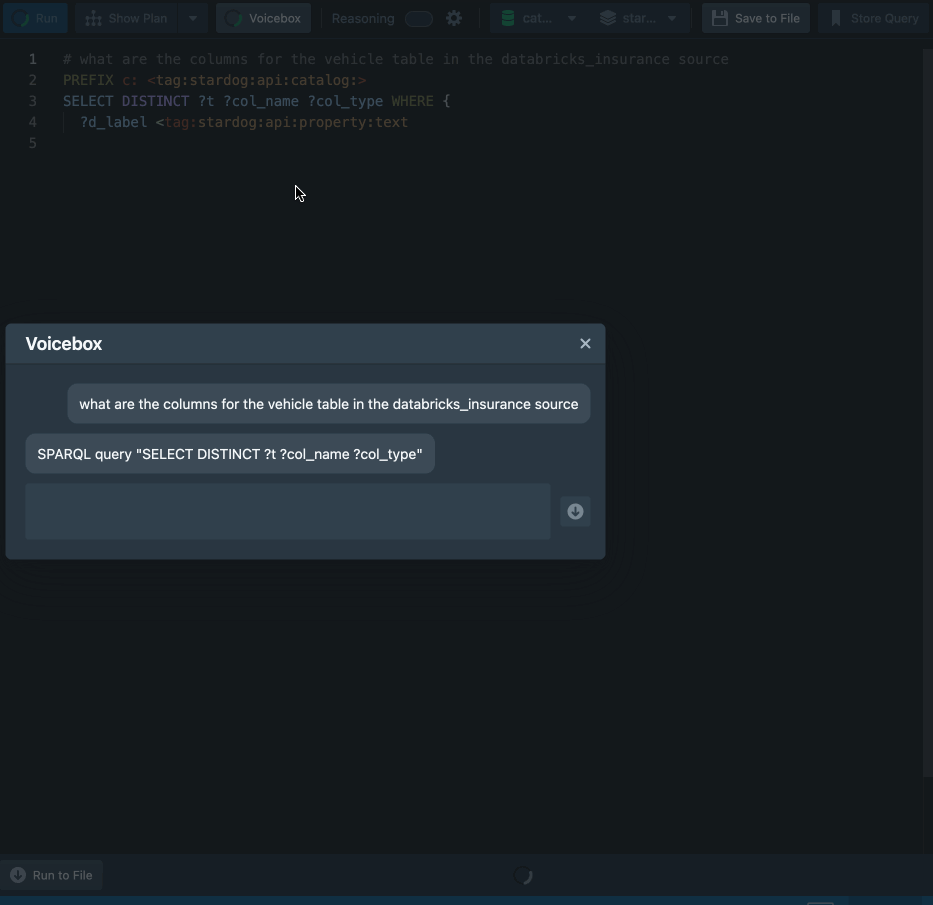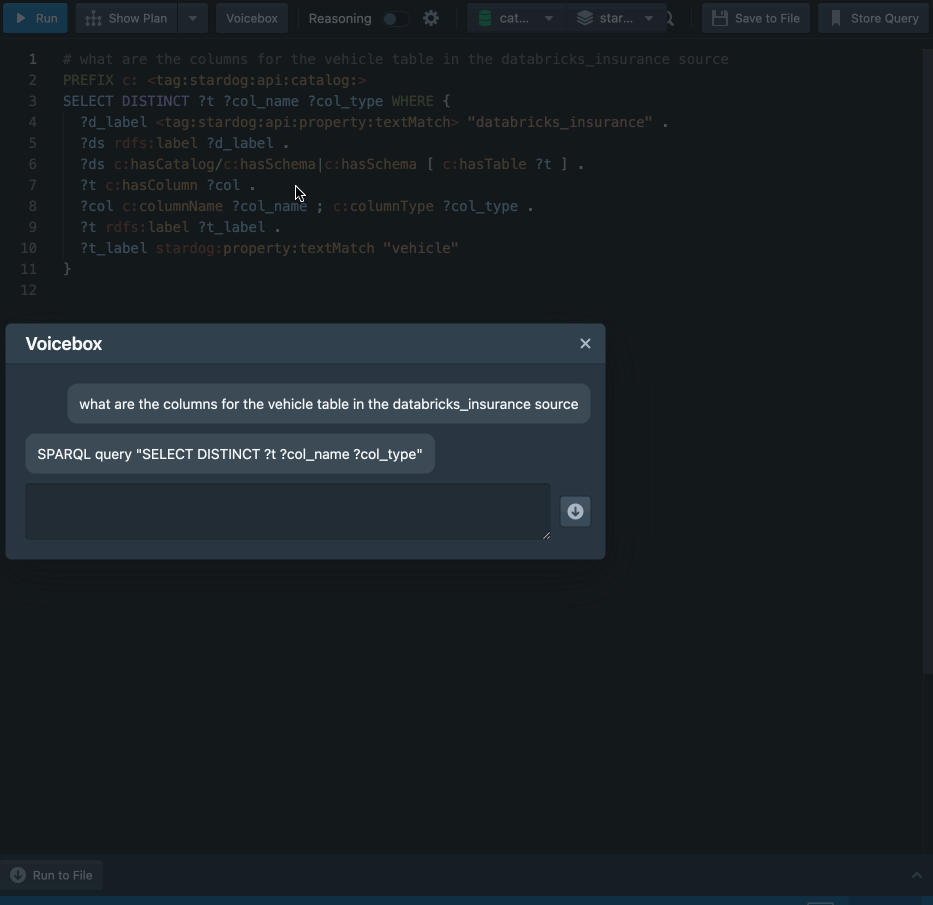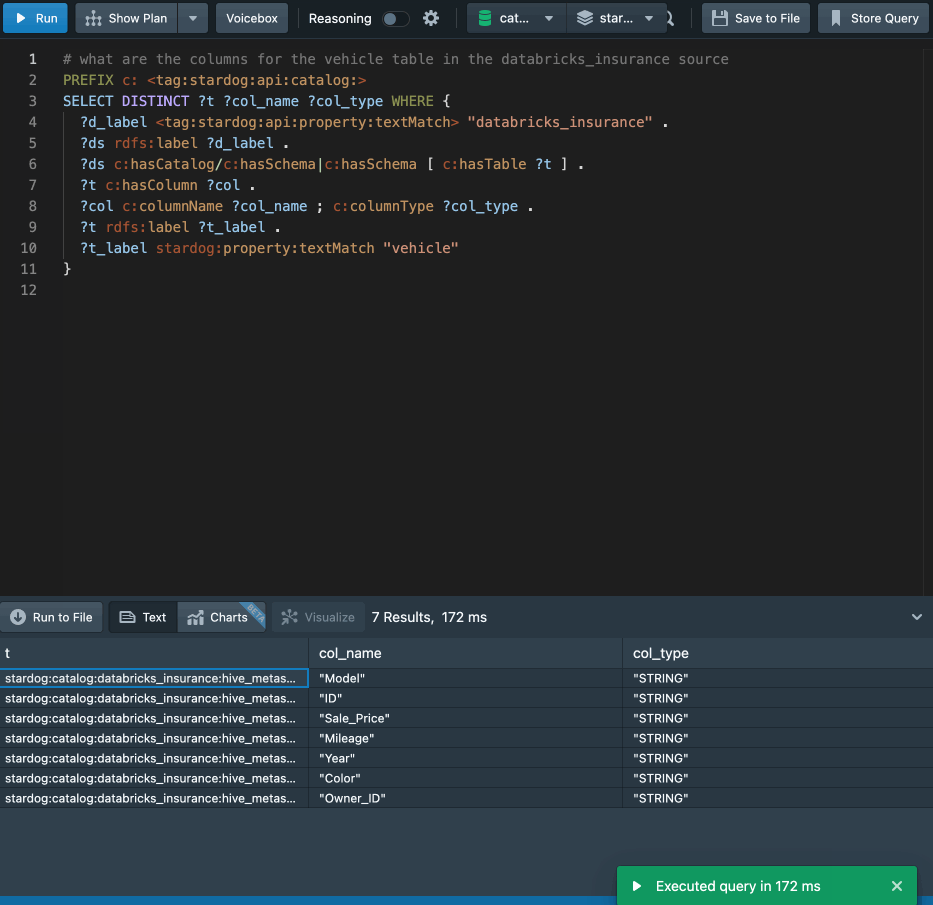
“Show me all concepts mapped against a given data source”
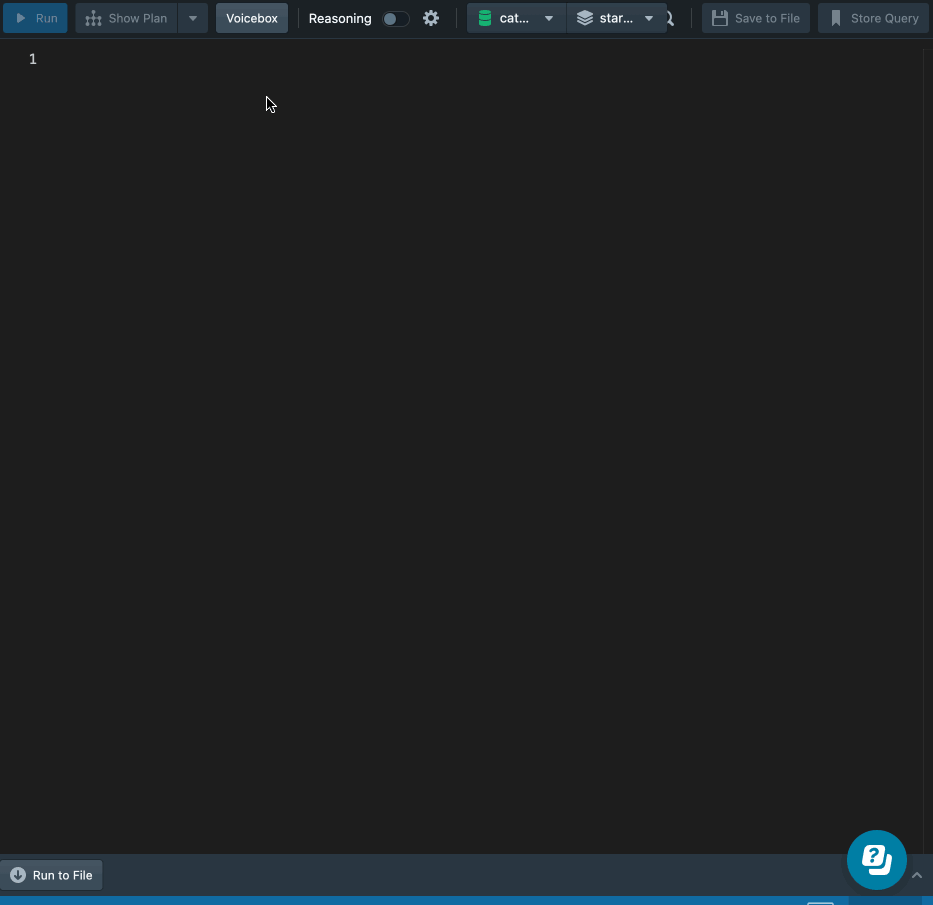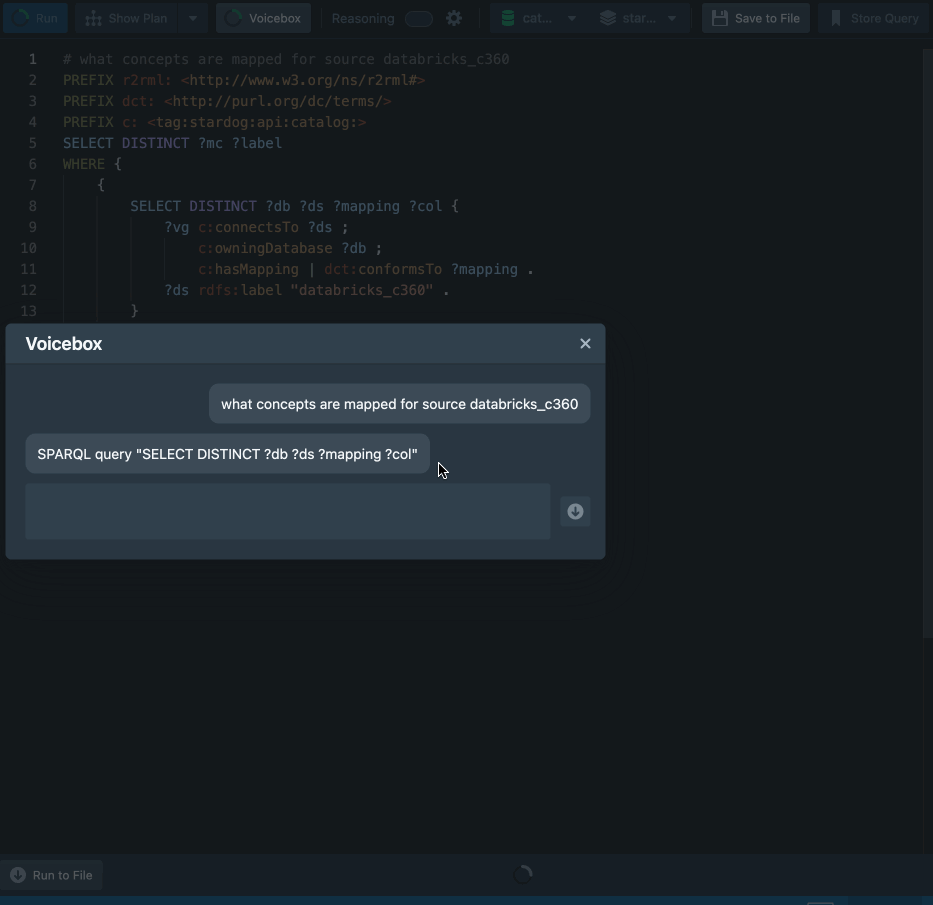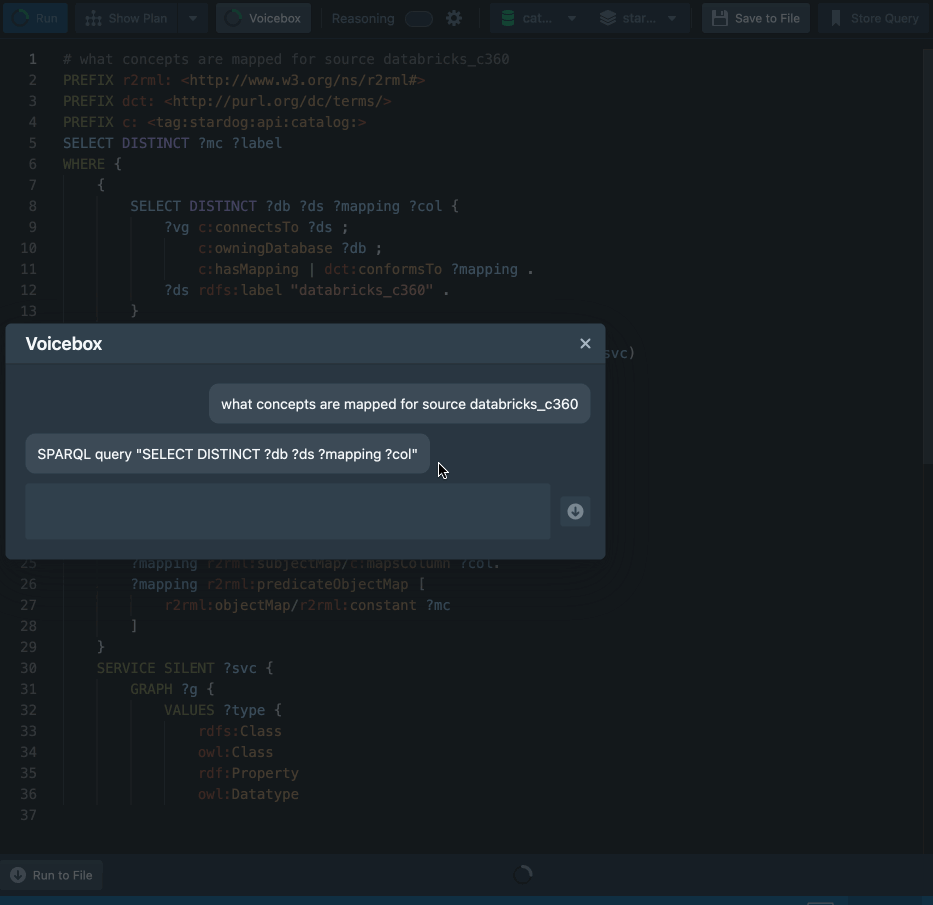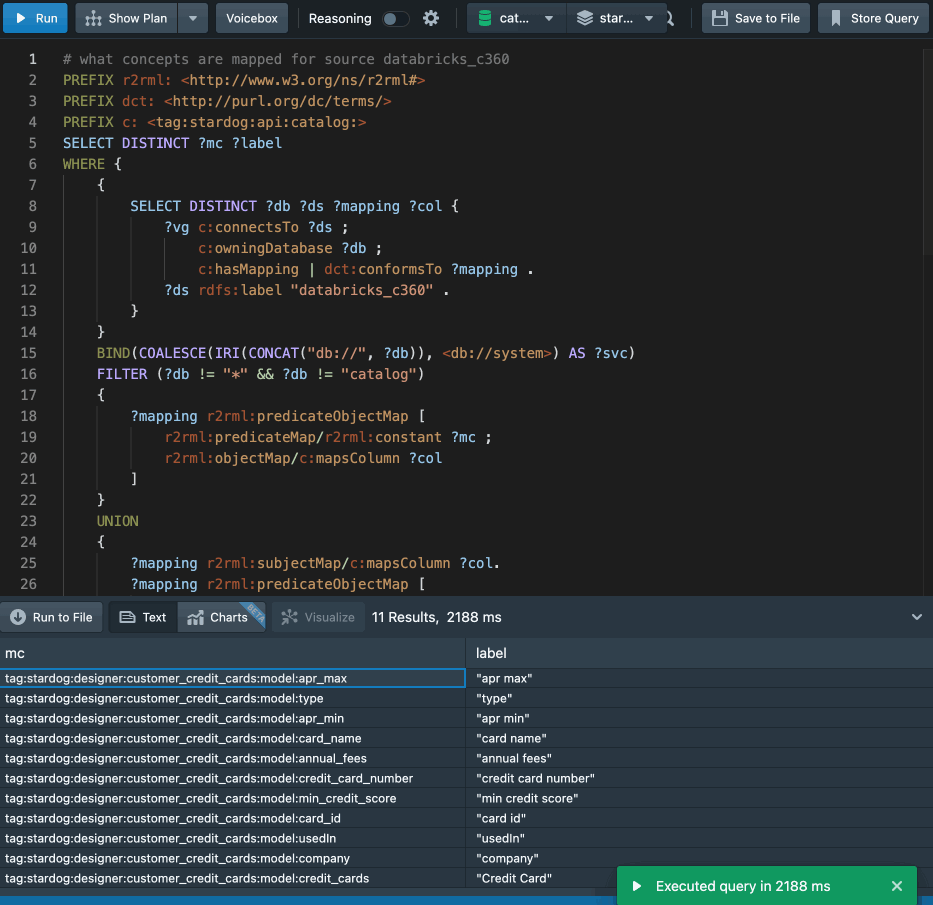
We are just getting started. More on the benefits and capabilities of Voicebox to bring metadata intelligence to the masses will be discussed in future posts. Watch this space.
Get Started
Create your free Stardog Cloud account, access our Knowledge Kits landing page, and choose the kit that matches your business goal.
Not ready for that? Check out our recent Demo Day where we walk through activated metadata and other topics.
