
What LLMs Don’t Know

Get the latest in your inbox
Get the latest in your inbox
Your enterprise AI agents are failing. Not because they can’t think, but because they can’t access what matters most.
If you’re building agentic AI for your organization, you’ve likely experienced the frustration firsthand. Your pricing agent achieves less than 50% accuracy on straightforward calculations. Your customer service agent can’t access the conversation history that happened last week. Your compliance agent cites outdated regulations while missing critical internal policy updates. Meanwhile, your IT team is drowning in fragile data connections, and your business stakeholders are quietly reverting to their old manual processes.
The promise of “AI magic” has collided with a harsh reality: most enterprise AI agents are built on shaky foundations. They’re impressive in demos but unreliable in production. The problem isn’t the sophistication of your models. It’s what those models can and cannot access.
To understand why enterprise AI agents consistently underperform, we need to examine the universe of information through two critical dimensions: relevance to your business and accessibility to your agents.
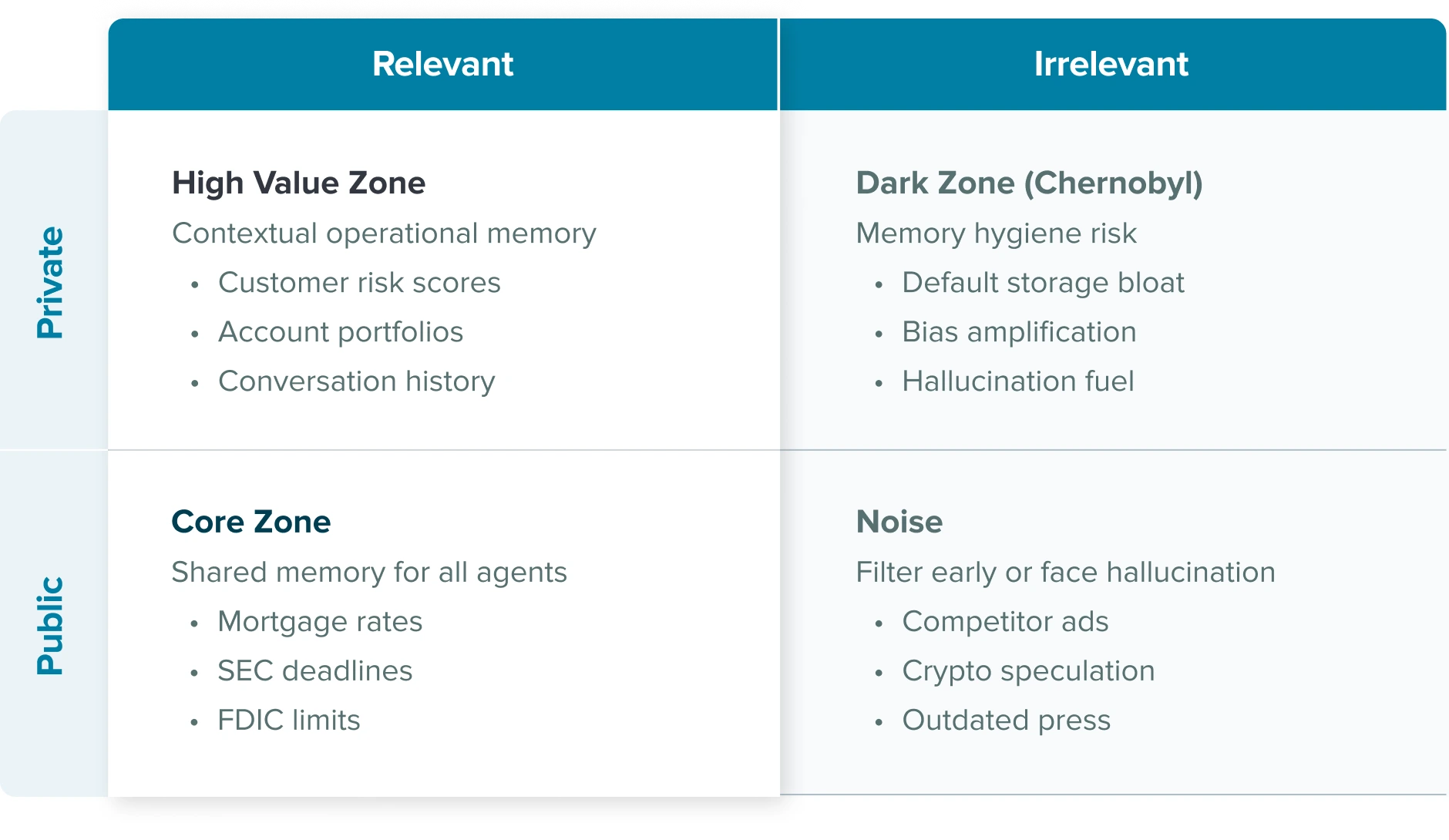
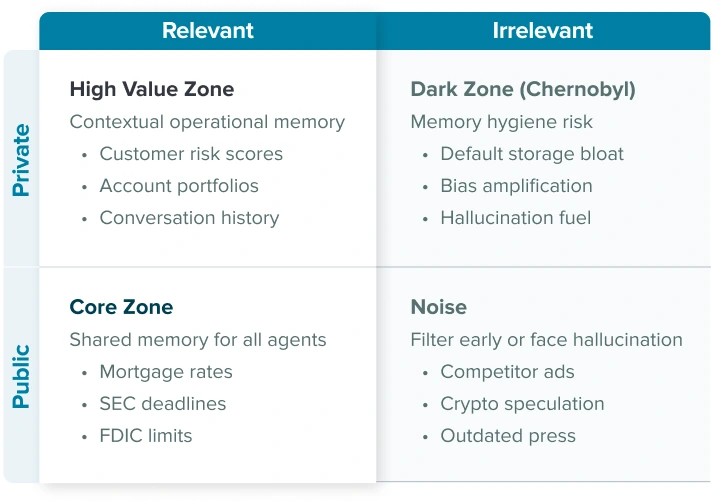
Public + Relevant (Core Knowledge Base): This is your agent’s shared memory. Accessible, verifiable, and essential for explaining offerings or ensuring compliance. Every agent needs this foundation.
Public + Irrelevant (Noise Suppression Zone): The vast expanse of public information that should be filtered early. Without tight filters here, agents hallucinate and lose focus.
Private + Irrelevant (Chernobyl): The danger zone where storage bloat becomes memory hygiene risk. This is where hallucinations and bias creep in through accumulated organizational noise. Often stored by default, desperately needs purging, compression, or intelligent tagging.
Private + Relevant (High Value Zone): This is where enterprise AI agents either thrive or die. This quadrant fuels personalization, reasoning, and task continuity. It’s what transforms a generic AI assistant into a powerful business agent.
The cruel irony? Most enterprise AI initiatives focus on the wrong quadrants. They optimize for public knowledge that LLMs already handle well, while the High Value Zone remains frustratingly inaccessible to their agents.
Your IT team knows the truth. Building these agents isn’t just difficult; it’s a maintenance nightmare. Each new data source requires custom connectors. Each schema change breaks existing integrations. Each new use case demands another round of ETL pipelines and data modeling. The result is a growing collection of fragile services that someone has to manage, debug, and keep running.
Business stakeholders start with high expectations. They’ve seen the demos, heard the promises, and imagined AI agents that understand their specific context and data. But when the pricing agent can’t access current inventory levels, when the compliance agent misses recent policy updates, when the customer service agent can’t see last week’s interactions, trust erodes quickly.
The traditional approach scales poorly. You end up with dozens of point-to-point integrations, each requiring specialized knowledge to maintain. When something breaks, it’s often unclear which system is the culprit. When requirements change, the ripple effects are unpredictable. What started as “AI transformation” becomes “technical debt amplification.”
Here’s the uncomfortable truth: your agents’ poor accuracy isn’t primarily a model problem. It’s a data access problem. When your pricing agent achieves no better than 50% accuracy, it’s not because the underlying LLM can’t do math. It’s because the agent can’t access current pricing data, inventory levels, customer history, and market conditions in a coherent, timely manner.
Your agents are making decisions with incomplete information. They’re reasoning about outdated data. They’re missing critical context that exists somewhere in your organization but isn’t accessible through a unified interface. No amount of model fine-tuning can fix this fundamental data access gap.
🐕 Case Study: Global Energy Manufacturer
Consider a global energy manufacturer we recently engaged with—let’s call them “MegaCorp Energy.” They operate multiple refineries worldwide, each generating approximately billions in annual revenue. Their challenge perfectly illustrates the High Value Zone access problem.
The Problem: MegaCorp’s sales teams needed to create complex pricing proposals that factor in geopolitical events, tariffs, supply chain disruptions, port logistics, route planning, existing customer contracts, and regulatory changes. Each proposal required data from over 10 different sources, both internal systems and external feeds.
Their AI agents were achieving only 54% accuracy on pricing recommendations. Sales professionals, who were responsible for hundreds of millions in revenue decisions, had lost confidence in the system. The business was losing $100+ million annually due to poor information quality, with one geographic region alone missing $70 million in sales revenue.
The Data Nightmare: MegaCorp had thousands of data silos across relational and NoSQL databases. Each sales decision required manual data gathering across multiple windows and systems. Proposals took 1-2 hours to compile, during which critical information often became stale. Data was replicated 2-3 times across systems, creating consistency issues and compliance gaps.
Their IT team was overwhelmed, constantly building new data pipelines for AI initiatives while being blamed for agent inaccuracy. When new data sources were needed, integration took months—by which time executive decisions had already been made with outdated information.
The High Value Zone Gap: MegaCorp’s Private + Relevant quadrant contained exactly what their agents needed: real-time refinery throughput data, shipment tracking, inventory levels, customer contract terms, and market intelligence. But this critical information was trapped in silos, accessible only through manual processes that introduced delays and errors.
The Breaking Point: Sales teams were manually sharing data via Excel spreadsheets, creating compliance and legal risks. Throughput updates and other critical information lived in disconnected spreadsheets, leading to 20-30% inaccuracy in contract value estimates. The disconnect between their sophisticated AI ambitions and fragmented data reality had become unsustainable.
MegaCorp’s experience illustrates a universal truth: no amount of model sophistication can overcome fundamental data access problems. Their agents weren’t failing because they lacked intelligence—they were failing because they couldn’t access the High Value Zone information that drives accurate business decisions.
Business stakeholders are tired of managing multiple AI agents that don’t talk to each other. They want a single interface where all agents contribute to a unified experience. But achieving this requires more than just UI consolidation. It requires a fundamental shift in how agents access and share organizational knowledge.
The answer isn’t more integrations. It’s a semantic layer that transforms how AI agents access structured data.
A knowledge graph-powered semantic layer represents a fundamentally different approach to enterprise AI data access. Instead of building point-to-point integrations between agents and data sources, you create a unified semantic interface that understands the relationships, context, and business logic that govern your organizational knowledge.
Here’s how it transforms the four quadrants
Core Knowledge Base Enhancement: Public, relevant information gets properly tagged and structured, creating a reliable foundation that all agents can access consistently.
Noise Suppression: Advanced filtering mechanisms ensure irrelevant public information doesn’t pollute agent responses or contribute to hallucinations.
Chernobyl Cleanup: Intelligent data governance automatically identifies and quarantines irrelevant private information, preventing memory bloat and bias amplification.
High Value Zone Activation: This is where the magic happens. Your semantic layer makes every relevant fact in your organization accessible through a single natural language query. Customer risk scores, conversation histories, portfolio performance data—all connected through meaningful relationships that agents can navigate intuitively.
The semantic layer doesn’t just solve data access; it transforms the interface. Instead of forcing agents to navigate dozens of APIs and data formats, they can query your entire organizational knowledge using natural language:
The semantic layer handles the complexity of joining data across systems, applying business rules, and returning results that respect access controls and data governance policies.
Look, there’s no GenAI without vector databases. However, that can’t be your entire stack for solving context engineering. Feeding agents or an LLM only the data you retrieve from the vector database isn’t going to get you very far. Why not? Well, that’s basically RAG and it has issues
Models are super intelligent but the RAG data bottleneck is exaclty the chunking, vectorization, etc. And, of course, the Structured Data Blind Spot. A semantic layer addresses these shortcomings directly by contextualizing any relevant data data so your agents and people get real context.
The vision is both ambitious and necessary: every relevant fact in your organization, accessible through a single natural language query. This isn’t about building another data warehouse or business intelligence tool. It’s about creating a semantic understanding of your enterprise data that can power any AI agent, any application, any user.
When your agents can instantly access complete customer context, risk assessments become more accurate. When they can correlate market data with internal performance metrics in real-time, strategic decisions become more informed. When they can trace regulatory requirements through operational procedures to specific transactions, compliance becomes proactive rather than reactive.
The enterprise AI agents of tomorrow won’t just be powered by larger language models. They’ll be powered by semantic layers that bridge the gap between general AI capabilities and specific business knowledge. Organizations that invest in knowledge graph-powered semantic layers today are building the foundation for truly intelligent enterprise AI.
Your current approach isn’t working. Your agents are failing because they can’t access what matters most. Your IT team is overwhelmed by integration complexity. Your business stakeholders are losing trust in AI’s potential.
But there’s a better way. Instead of building more fragile connections between agents and data sources, build a semantic layer that makes every fact in your High Value Zone accessible through natural language. Transform your agents from impressive demos into reliable business tools.
The question isn’t whether your industry needs AI agents that understand your specific domain and data. The question is whether you’ll build the semantic infrastructure that makes such agents possible.
In the race to deploy enterprise AI, the winners won’t be those with the most sophisticated models. They’ll be those who solve the data access problem first. Because what LLMs don’t know about your business is exactly what your AI agents need to know to be truly useful.
Stardog’s Knowledge Graph-powered semantic layer gives the C-suite real-time, AI-powered visibility into supply chain exposure.
Knowledge graphs are essential for trustworthy enterprise AI. Learn how a federated knowledge layer solves data fragmentation, mitigates misinformation risks, and delivers hallucination-free AI.
How to Overcome a Major Enterprise Liability and Unleash Massive Potential
Download for free