We’re happy to announce the beta release of Stardog 7 which comes with a new storage engine that significantly improves write performance.
We have been talking about the new Stardog storage engine, Mastiff, for a while now. Mastiff is based on the open-source–and very low-level–key-value store RocksDb and brings multi-versioned concurrency control (MVCC) to Stardog transactions. Very broadly this means faster transactional writes especially for concurrent transactions and better scalability. You can read about the details of the engine in the earlier blog posts and find the details about the transaction semantics in our documentation. Here I will present some benchmarking numbers showing how Stardog 7 beta with Mastiff performs.
Write Performance
Stardog 6 and previous versions were optimized for reads and bulk loading performance. At database creation time, you can load your data at speeds up to 500K triples/sec but the transactional writes, especially with concurrent transactions, did not perform at that speed. This meant everything was fine if you had all your data ready to be loaded, but when your data arrives in small increments things did not work as well.
Mastiff brings significantly improved transactional write performance as we present below. But before talking about numbers, a word of caution: Benchmarking is notoriously hard even if you are very familiar with the system you are benchmarking. There are many different factors that affect write performance: the size of the database you are starting with, number of concurrent transactions, number of triples you are modifying in a transaction and so on.
So we always encourage users to benchmark Stardog using their data based on the characteristics of their use cases and apps.
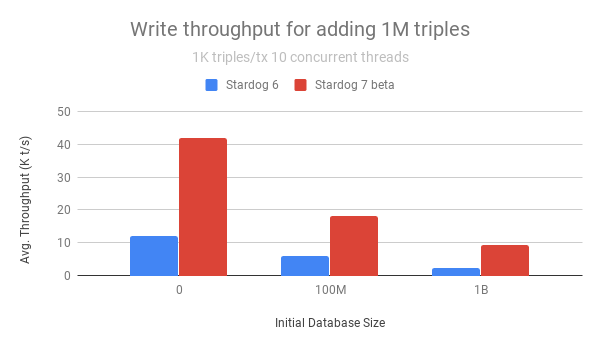
The first result we will look at is the write throughput for adding 1 million triples using 10 concurrent transactions where each transaction is adding 1K triples at a time. We measure the write throughput as the number of triples added per second so the higher numbers are better! As the following chart shows Stardog 7 beta outperforms Stardog 6 by 3 to 4 times regardless of the starting database size:
We also looked at the performance of loading 1 billion triples by adding 1 million triples at each transaction but using a single thread so there is no concurrency. So we need to execute a total of 1000 transactions in this case to get a billion triples. The following chart shows the average transaction throughput as more and more data is loaded into the database:
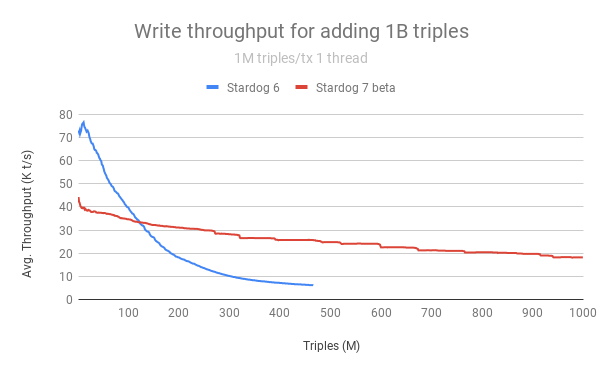
As you can see Stardog 6 starts loading data faster than Stardog 7 beta mainly because we start with an empty database and there is no concurrency. But the write throughput for Stardog 6 degrades much more quickly than Stardog 7 beta and slightly after 100M triples Stardog 7 beta becomes faster.
With Stardog 6 you can load billions of triples easily at bulk loading time or by using a small number of transactions. This is still the case with Stardog 7 beta, but now, thanks to the new storage engine, you also have the option of loading the data in smaller transactions with reasonable performance.
Read Performance
Nothing in life comes for free and it is even more so for software. Increasing write throughput and scalability comes at a price for read performance, but we have tried to keep the overhead to a minimum.
Benchmarking read performance of SPARQL queries is even harder than benchmarking write performance since the characteristics of the data and the queries vary widely between different use cases. We use a collection of 20 different benchmarks consisting of publicly available ones and others based on real-world datasets and queries shared by our customers and users. In the following chart we present the average query execution times for two publicly available benchmarks SP2B and BSBM:
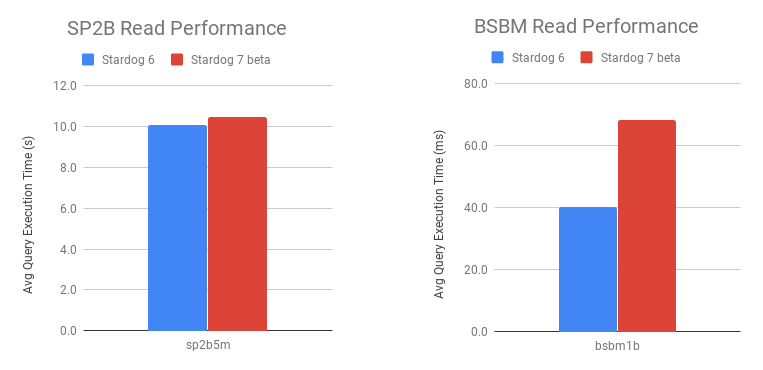
These two benchmarks have very different characteristics. SP2B queries are more analytical and some of them return millions of results, whereas BSBM queries are more based on lookups for specific nodes in the graph and return very small number of results. This is why BSBM queries take milliseconds whereas SP2B queries take seconds.
The results show that the performance of SP2B queries for Stardog 7 beta almost match the performance of Stardog 6 but the execution time for BSBM queries increased. The good news is that even with this slowdown average query execution time over 1 billion triples is less than 100ms! And rest assured we are working hard to improve the read performance of Stardog 7 as we move from the beta release to the final GA release.
Conclusion
Stardog 7 beta is bringing significantly faster transactional writes without sacrificing read performance too much. But as any beta release it is not ready to be used in production and we will continue work on performance improvements and robustness throughout the beta period.
We invite you to check out the Stardog 7.0 beta today. Read the full Release Notes for more details and get it from our community forum to try it with your data.
Just don’t do it with your production data without backing up your data first! :)
