Data fabric is ushering in a new era of enterprise IT. Traditional data management solutions have failed to deliver the connected data ecosystem they promised. Data fabric offers a different way forward and one that’s a significant departure from the world of rows and columns in a table that we’re used to.
But what outcomes does a data fabric really promise?
Banks can resolve risk incidents more quickly. One Stardog financial services customer, a global bank with nearly $900 billion in total assets, uses a data fabric for their operational risk practice. When a risk event occurs, analysts need to analyze 25,000 controls—safeguards put in place to mitigate risk events—and then figure out which control needs to be modified to prevent a similar risk event in the future. These controls exist across a dozen or more systems. While once, risk response required ad hoc analysis of each individual system, now the bank can easily traverse the linked information across various applications involved in risk management to uncover dependencies within the data and identify root causes of particular incidents.
Scientists can focus on the science. Boehringer Ingelheim, one of the world’s leading pharmaceutical companies, turned to a data fabric to help its scientists uncover data needed for critical drug discovery analysis. 30% of active ingredients under evaluation were sourced from external collaborations, and Boehringer has limited control over the quality of this data. Furthermore, they needed to be able to evaluate the many-to-many relationships within their R&D data, such as, “find a set of compounds which are creating a similar effect,” or “find compounds which have been tested in similar conditions and similar treatments.” By implementing a data fabric, Boehringer created a consolidated, one-stop shop for 90% of their R&D data, making it easier for scientists to directly access the data they need and deliver innovative drugs to market faster.
Product teams can transform raw data into innovative new products. Schneider Electric is using a data fabric to transform data collected from hundreds of thousands of devices, controllers, and sensors used in building management systems into SaaS solutions that help customers optimize efficient building operations. This data existed in disconnected silos and, in and of themselves, each dataset had limited value. However, when all linked together, data like digitized floor plans, IoT sensors, elevators, and access controls, Schneider Electric made it possible for customers to answer questions like: “what were the temperature readings for the past month in this particular room on this floor?” And then, using Schneider’s new SaaS solutions, they could automate the operation of these controls.

How do data fabrics achieve this? We need to start by looking at the limitations of past data management solutions.
The relational problem
The enterprise data landscape is increasingly hybrid, varied, and changing. The emergence of IoT, rise in unstructured data volume, increasing relevance of external data sources, and trend towards hybrid multi-cloud environments are outstripping the capabilities of traditional data management solutions. That’s because those are based on static models where data is related in rows and columns in tables. Today’s use cases require a model that is flexible, that can be extended, and that learns as new data is added.
The structured data management systems worked acceptably well when the enterprise data landscape was itself predominantly structured. But what is the right solution for the new normal? How can enterprises shift from a reactive to a responsive data strategy?
The path forward: data fabric
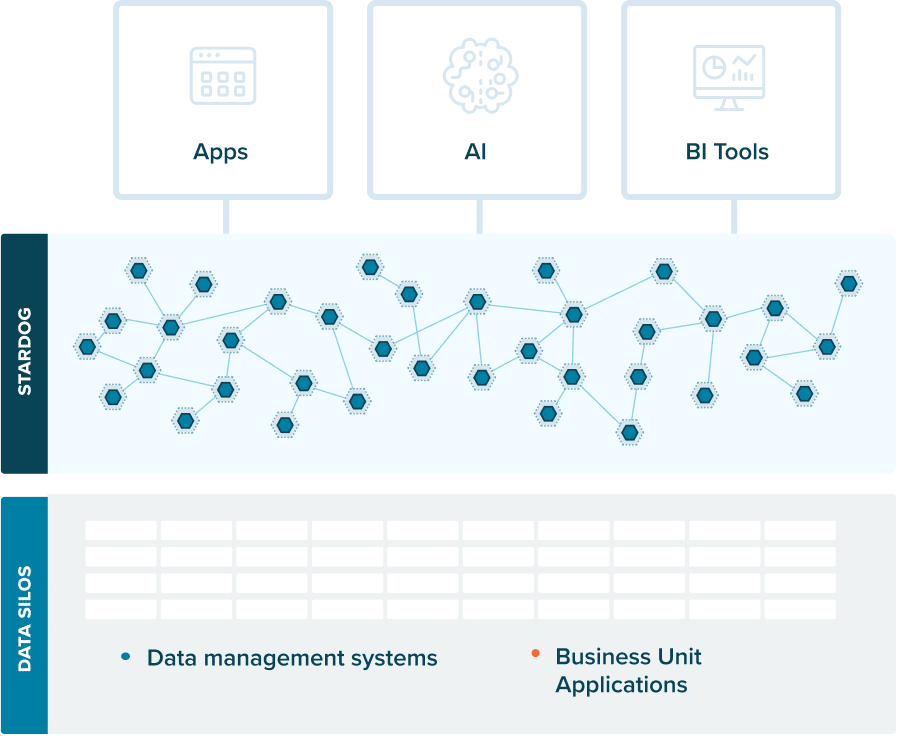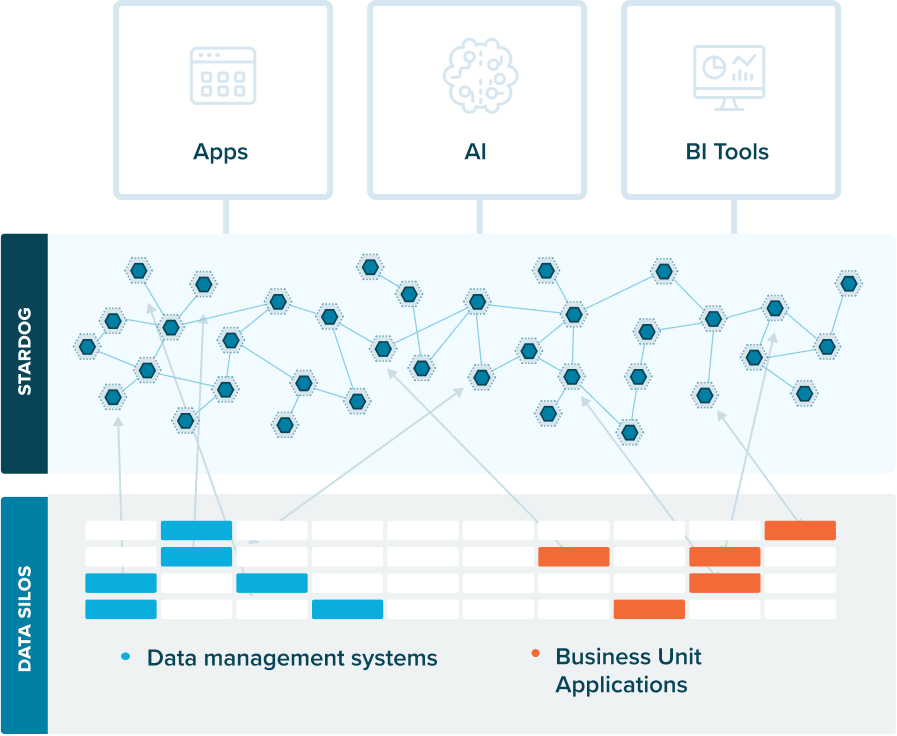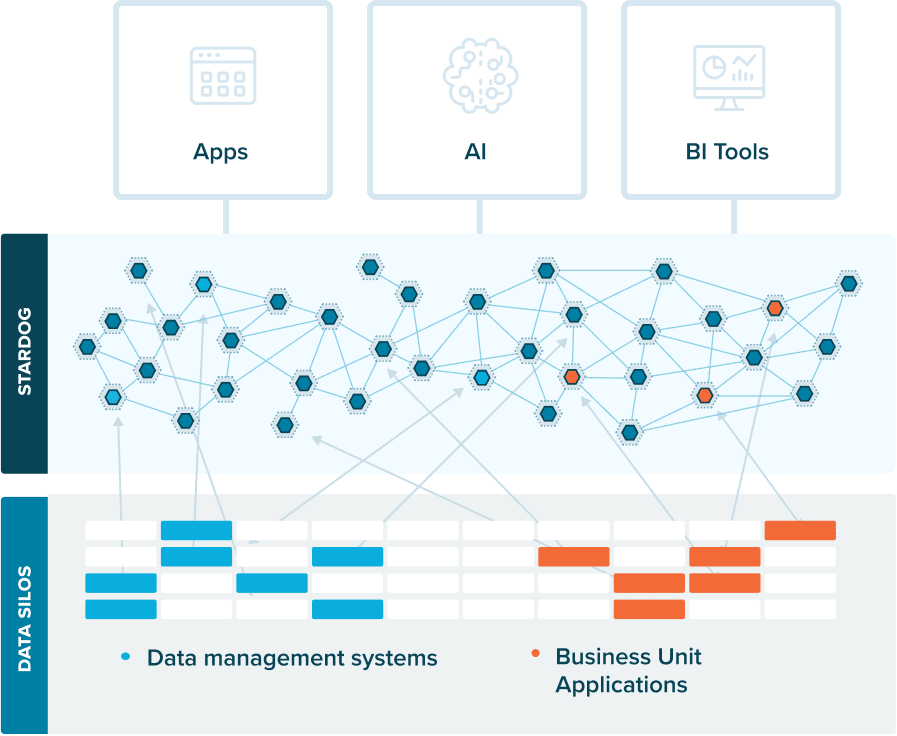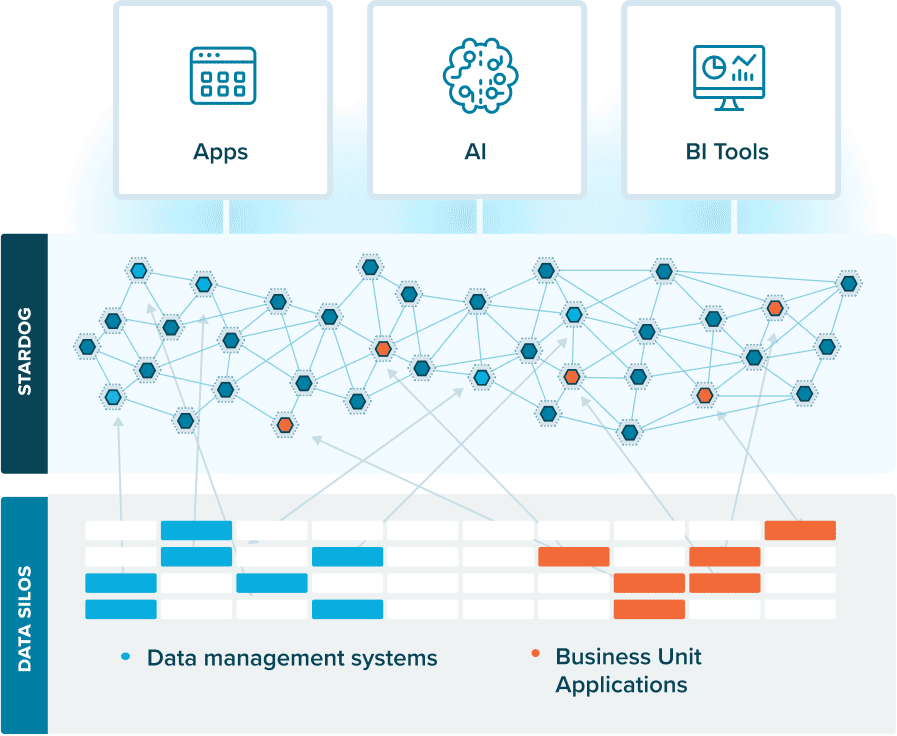
Data fabrics offer the new way forward. They provide the critical data infrastructure that powers your business’ apps, AI, and analytics. The data fabric weaves together data from internal silos and external sources and creates a network of information to power your business’ applications, AI, and analytics. Quite simply, they support the full breadth of today’s complex, connected enterprise.
The good news about data fabrics is that they don’t require you to rip and replace your previous investments. They just stitch together what you already have, enhancing connected apps with enriched data from each source system. The key ingredient to transforming existing data infrastructure into a data fabric? A knowledge graph.
Knowledge graphs are an application of graph technology that turn your data into machine-understandable knowledge. Knowledge graphs capture the real-world context that is often missing from traditional data management systems. While knowledge graphs offer the benefits of dramatic reduction in code (as highlighted in the graphic above) and capturing real-world business meaning, they are also a departure from the traditional relational data systems you are likely most familiar with.
In the next installment of this series, we’ll dive into this core technology that makes data fabric possible: graph. Learn how graph compares to relational, the benefits of graph, and why and when you should opt to use graph.
