To get the best results in AI, the enterprise needs a platform that offers the best of LLM and Knowledge Graph, and it needs that combination for two reasons:
- Precision. For the most precise results, LLM and KG have to work together: the former to understand human intent and the latter to ground the former.
- Recall. For the most comprehensive results, LLM and KG have to work together: the former to handle unstructured data (i.e., documents) and the latter to handle everything else (i.e., structured and semistructured data, i.e., database records).
Recently at a meeting I was attending, a real GenAI infrastructure leader assured me, in response to my heresy about RAG, that hallucinations are fine because models are getting bigger and more powerful, and RAG works to “augment” model outputs.

But it’s not fine, not really. RAG augments LLM outputs; but the question isn’t whether RAG improves bare LLM. The question is really, for any particular use case, how much lying is okay? What is the acceptable frequency of hallucination for your use case?
Hallucination frequency matters because hallucinations are often (but not always) just bad; and they’re common! Here’s the latest hallucination leaderboard. It’s like a very common thing, as anyone who’s shipped a GenAI app to production can attest.
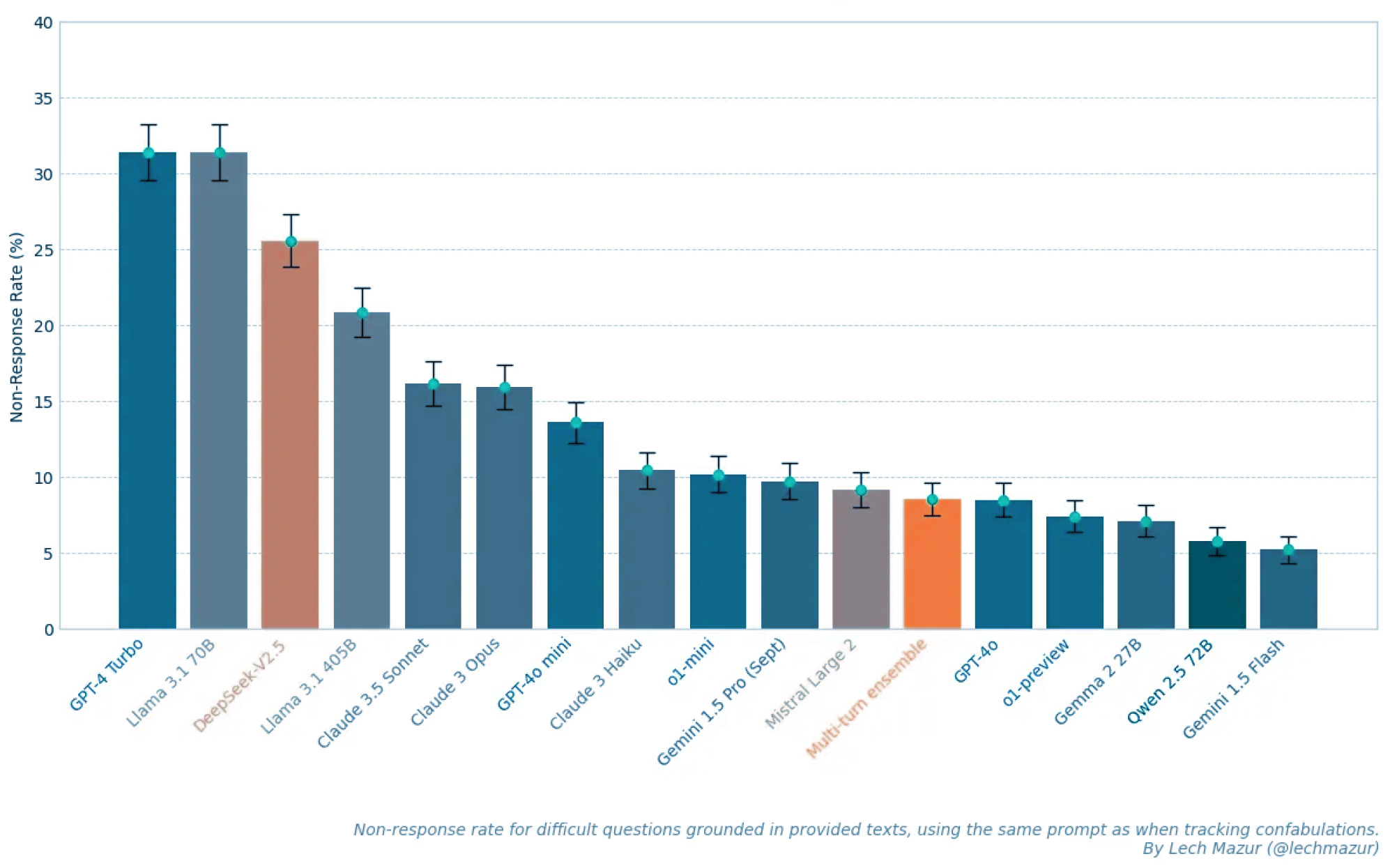
Non-Response Rate for Text-Supported Questions, Source: Lech Mazur
Given Stardog’s market focus on regulated industries, we address use cases for which there is no acceptable level of algorithmic lying.
What’s worse is the belief that, as models get larger, the hallucination problem will just go away. But that probably isn’t going to happen any time soon, if at all. Not if you agree with a new study in Nature (”Larger and more instructable models become less reliable”) that suggests that the more sophisticated models become the more likely they are to get some things wrong—
Schellaert’s team looked into three major families of modern LLMs: Open AI’s ChatGPT, the LLaMA series developed by Meta, and BLOOM suite made by BigScience. They found what’s called ultracrepidarianism, the tendency to give opinions on matters we know nothing about. It started to appear in the AIs as a consequence of increasing scale, but it was predictably linear, growing with the amount of training data, in all of them. Supervised feedback “had a worse, more extreme effect,” Schellaert says.
Well that’s just bloody awful!
RAG’s Limits aren’t (Only) a Hallucination
The recent Morgan Stanley survey about enterprise adoption of AI contains a better outlook than the naysayers would have everyone believe. One bit that stood out to me especially was this:
But here’s an overlooked challenge—25% of respondents are worried about reputational damage.
That’s exactly a concern about hallucinations. It suggests that any hallucination, no matter the “stakes” of use, can cause reputational harm and is a cause for enterprise concern.
Finally, Ali Ghodsi, CEO of Databricks, a great Stardog tech partner, suggests that RAG is inadequate for other reasons, too—
in RAG, you pull the latest info from a vector database into the LLM’s context window. How well the models can actually leverage that context is crucial—and surprisingly, most struggle with it. On key tasks, almost no LLM surpasses ~50% accuracy beyond 128k tokens.
We all do RAG in order to steer LLMs toward the truth, but the LLMs aren’t always very steerable. Maybe we can fix this at the neural network architecture level; maybe not. I don’t know.
Consider a thought experiment.
Is there a way to destroy two knowledge economy firms—let’s say, two banks—non-destructively? That is, without harming any people, or destroying any real property, or even deleting a single byte of data? Sure, it’s easy. I would give Bank A all of Bank B’s data and vice versa. No data is destroyed, nor people harmed, nor real property altered. And yet neither firm could function for a minute.
This absolute dependency on enterprise knowledge suggests that one of the essential functions of a knowledge firm is to safeguard its unique knowledge holdings.
And yet no foundational, external LLM knows anything at all about those unique holdings. Solving for that gap is the reason that Stardog Platform fuses LLMs and Knowledge Graphs. The rest of the benefit from fusing these two techs is a delightful bonus.
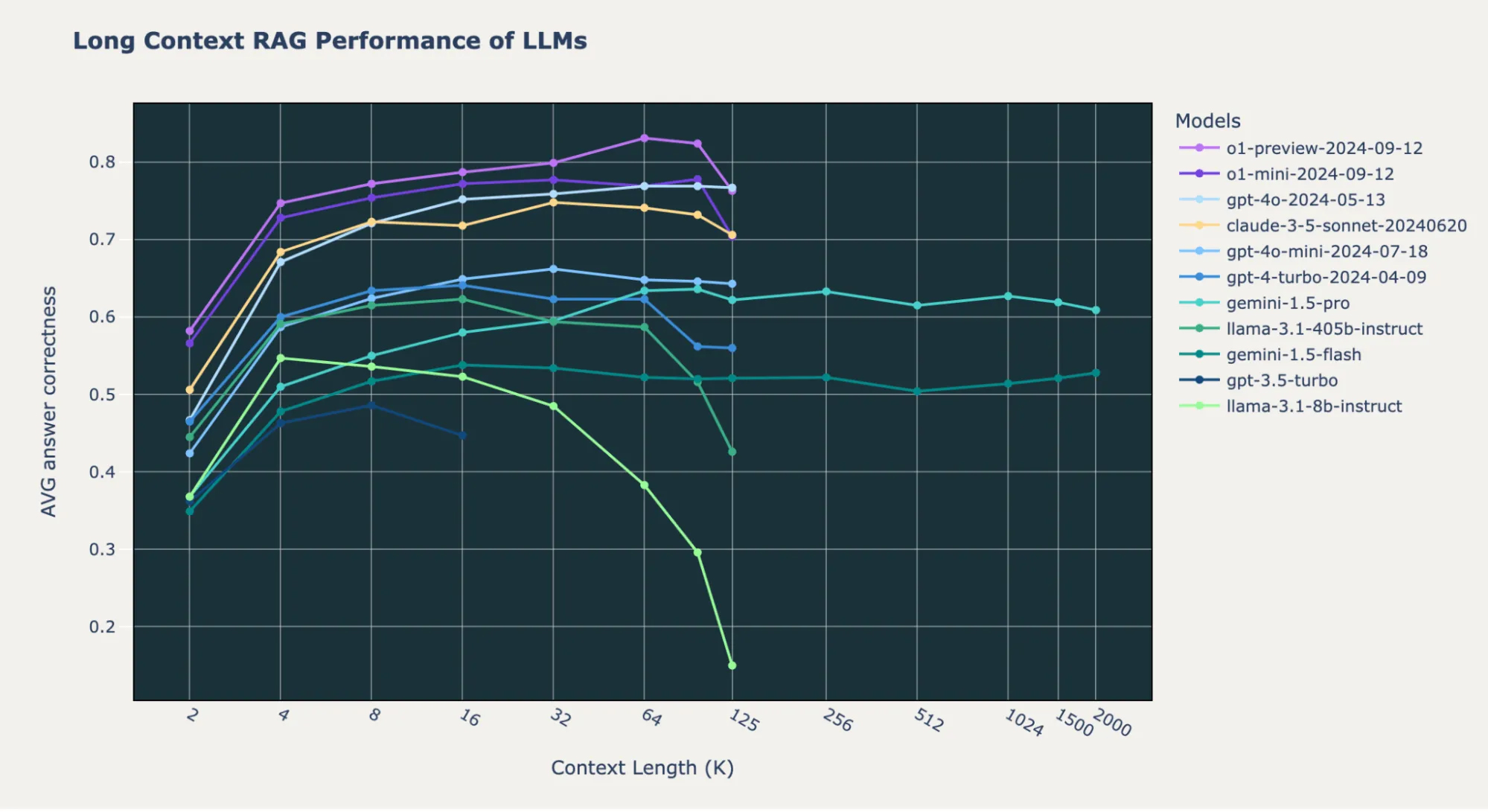
Long Context RAG Performance of LLMs, Source: Databricks
Stardog Fuses LLMs & Knowledge Graphs
Later on I will talk about how to fuse KG and LLM. Here I say why they should be fused.
TLDR—The logic of this blog post goes something like this:
- In a knowledge economy, a firm is its data, more or less.
- Foundational LLMs don’t know anything about a firm’s data. That’s a problem.
- Firms that adapt LLMs to their unique data holdings can gain an enormous advantage over their competitors by accelerating adoption and improving both precision and recall of AI-powered results.
- An LLM-Knowledge Graph fusion platform is an ideal LLM-knowledge adapter to accomplish that strategic advantage that comes from creating knowledge and meaning from data.
Why Enterprise GenAI Needs a Fusion
LLMs are great for background knowledge (“what everyone knows or should”) but they fall down hard on enterprise knowledge. Arguably in a knowledge economy what justifies a firm’s right to exist is the unique data universe it’s responsible for.
As we’ll see below, you can use a Knowledge Graph to do RAG. But you don’t have to do RAG only. No, really, there is an alternative. We’ve been working for the past year on Stardog Voicebox, a hallucination-free fast AI Data Assistant. We’re trialing Voicebox at life sciences, banks, manufacturers, and national security orgs, both existing and new customers.
For mission critical data insights, fully democratized by Voicebox’s conversational AI, our approach of grounding insights in enterprise data, 100% hallucination-free, is the only game in town.
For example, at a major US bank facing serious regulatory and data access challenges, they gave us a list of analytics questions that they’ve been unable to democratize using GenAI in an internal project that’s 18 months ongoing. We solved that challenge and are giving them access to democratized insights in 2 days. This isn’t a question of RAG versus Graph RAG; but, rather, Semantic Parsing—which is how Voicebox handles GenAI and user inputs—versus any variant of RAG including Graph RAG.
But if you take away only one lesson from this piece, let it be this: a single platform that can do the easy stuff (RAG), the medium stuff (Graph RAG), and the hard stuff (hallucination-free Semantic Parsing) is the one you want because you don’t want more than one platform. Stardog is the single platform that can do all three.
But there’s more to Stardog than just Voicebox. In the rest of this blog post, I describe the other part of Stardog, the part that is a platform fusion of Knowledge Graph and LLM for Enterprise GenAI.
What the Enterprise Needs from a GenAI Platform
Customers need help building a reusable, reliable, and sustainable GenAI stack that is modular; reusable and reproducible; that decouples machine learning, deep learning, GenAI tasks but grounded in quality data; that includes lineage and traceability; and that’s trustworthy.
Customers need flexible but foundational components in this GenAI stack:
- KG can be used for creating insights and connections from siloed data
- KG can be used for creating utility and value in data
- KG can be used for knowledge retrieval
- All of which is created once, used multiple times, across use cases and design patterns.
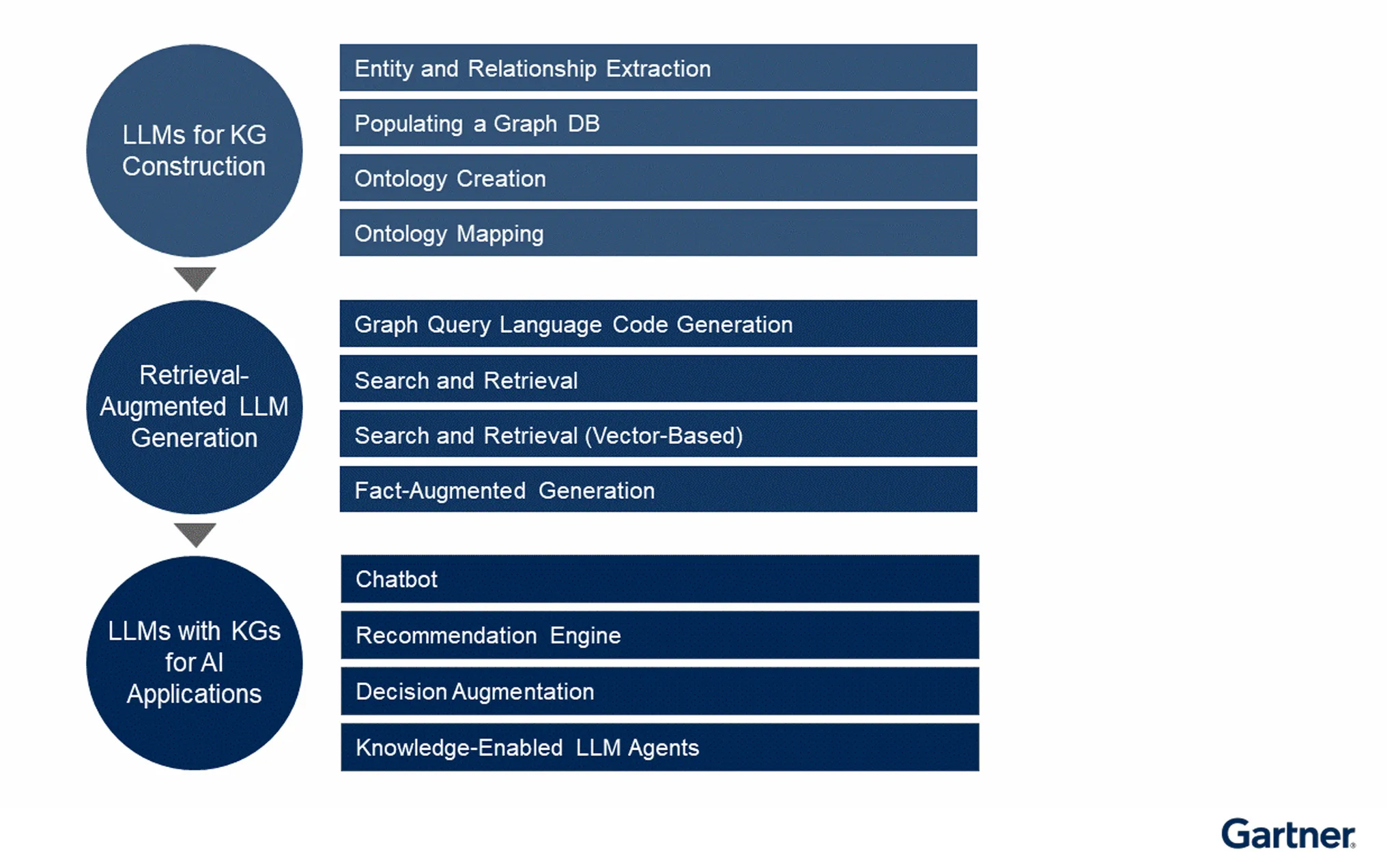
In short, the Fusion Platform that we offer in Stardog looks a lot like Gartner’s Knowledge-Enabled AI Architecture:
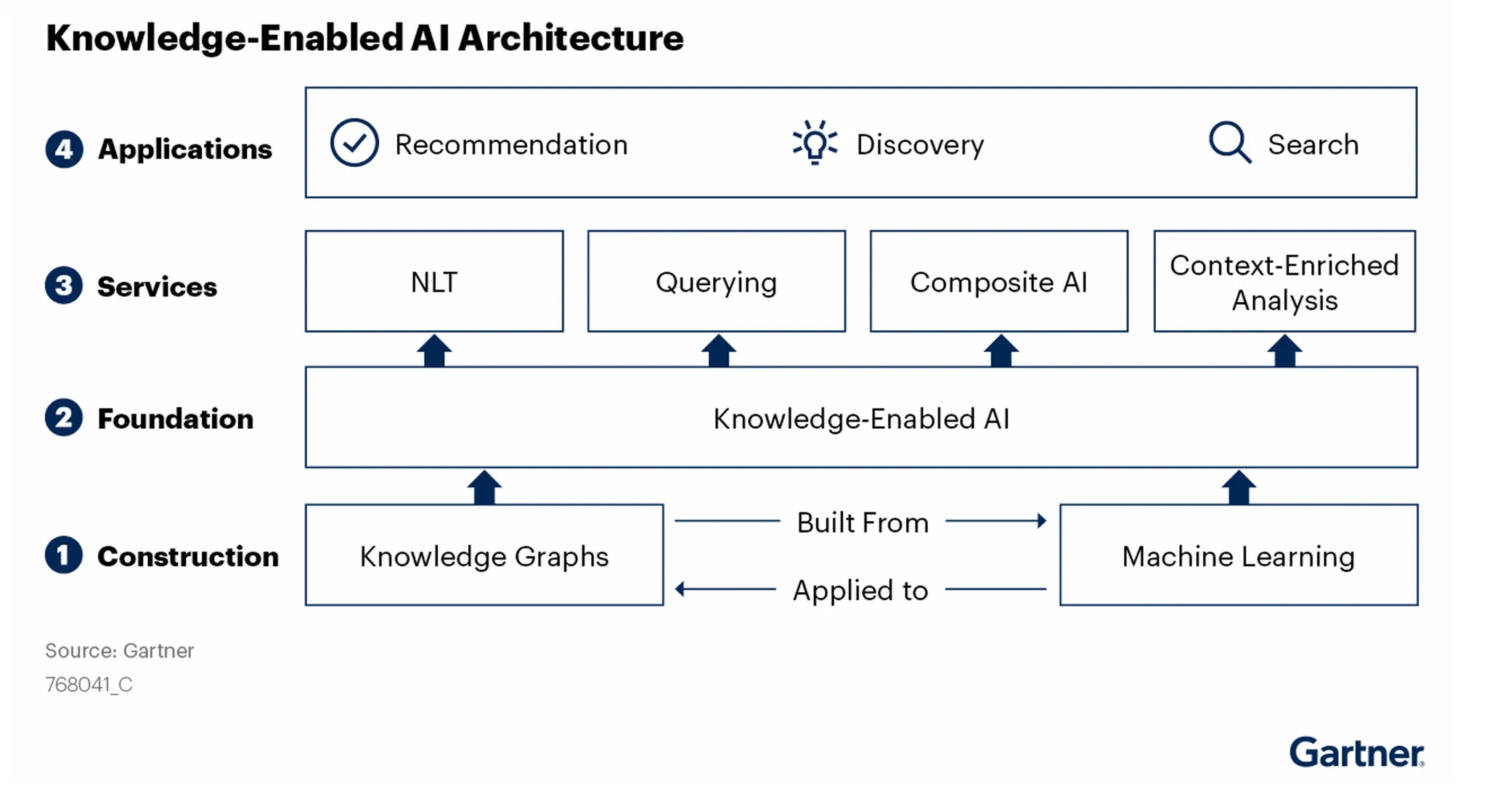
The Jobs to Be Done by an Enterprise GenAI Platform
The Stardog GenAI Platform uniquely fuses LLM and Knowledge Graph and is the ideal solution for a core set of six GenAI application requirements.
1. Querying All enterprise data, programmatically, from plain text prompts or from APIs.
There are many definitions of “knowledge graph,” but I prefer the one that I coined in 2017—
A Knowledge Graph about X is a software platform that can answer any question about X because it knows everything about X that’s worth knowing.
Put another way, knowledge graphs are data integration mechanisms that aim at comprehensiveness while, nevertheless, being tolerant of incompleteness. The comprehensiveness of an enterprise Knowledge Graph with respect to enterprise data silos is key to its value add for GenAI applications, including critically LLMs being hydrated with enterprise knowledge via programmatic querying of enterprise Knowledge Graph.
2. Grounding LLM outputs in reality, that is, in your enterprise data.
The main problem with RAG is that it allows the liar to speak last: if you have to allow a liar to speak, you should never let the liar have the last word. RAG essentially lets LLM speak (to the user) last, which is its greatest flaw. One way to ameliorate this flaw is to ground what the LLM says in reality, that is, in enterprise knowledge. Grounding acts as a sponge or filter of hallucinations generated by LLM.
But RAG’s other flaw is that it’s a fancy search engine, which is just to say that RAG’s data reach is limited to enterprise documents.
RAG only understands enterprise documents. That’s a real technology breakthrough, but it’s not sufficient in the enterprise. The enterprise has (at least) two sources of knowledge—
- Knowledge that resides in database records—RAG is blind to this knowledge.
- Knowledge that resides in enterprise documents—RAG only has visibility here.
LLMs don’t understand the distinction between these two knowledge residences, and that means an LLM will hallucinate about facts or knowledge the canonical source of which is, in an enterprise, some database or some document, equally often. So to effectively ground LLM outputs in enterprise knowledge, a Knowledge Graph must contain knowledge from both residences. We call this extending AI safety by extending AI’s data reach. See Safety RAG for more details about how Stardog Fusion Platform does this.
3. Guiding RAG with a Knowledge Graph—Safety RAG is RAG done right.
State of the art for RAG in the enterprise is retrieval from a fully-grounded Knowledge Graph, aided by LLM. If you’re going to do the wrong thing (RAG), you should do it in the right way (Knowledge Graph RAG). That’s a friendly exaggeration but it makes a crucial point, which is that plain old RAG isn’t really even sane any more. There, I said it. Friends don’t let friends do plain old RAG in late 2024.
As we build out Stardog’s LLM-powered capabilities of doing Knowledge Graph completion—see #4 below for more—that’s required us to add more infrastructure support in Stardog Platform for RAG since our approach to Named Entities, Events, and Relationship extraction, to automatically complete Knowledge Graphs with document-resident knowledge, includes an interactive process of extraction and then intermediate chunk retrieval. Ironic, I suppose, to do RAG inside a process the point of which is to avoid having to do RAG, but stranger things happen in computer science all the time. (For example, to avoid teaching people C, we build Python, which means a lot of software engineering in C.)
But as we’ll see below in the decision tree for guiding GenAI infrastructure investment there are use cases where plain old RAG is acceptable and the Stardog Fusion Platform supports those, with an straightforward lift-and-shift to Graph RAG and Safety RAG for the use cases where sensitivity about hallucinations is medium or high.
4. Completing Knowledge Graph via Information Extraction of enterprise documents with LLM.
Conventionally information extraction from unstructured text—to semantically lift its resident knowledge into a Knowledge Graph—is powered by a GNN or similar neural network architecture. Most State of the art results are still reported using some kind of GNN; but the issue is that GNN’s don’t typically generalize very well to out-of-distribution inputs. While LLMs don’t often achieve strictly State of the art results as compared to GNNs, they often generalize better and don’t require a specific training effort. We see at least two uses of LLMs in Stardog to complete knowledge graphs by deriving knowledge from enterprise documents—
-
Safety RAG (i.e., Semantic Parsing against complete knowledge) when hallucinations are unacceptable
-
Graph RAG for use cases where hallucination sensitivity is low (that is, some hallucinations are acceptable) and documents dominate the data distribution, since documents are all RAG can address.
5. Constructing important things programmatically.
-
Constructing Knowledge Graphs with LLM; see #4 above, since in the base case bootstrapping a KG from scratch via information extraction is a variant of completing an existing Knowledge Graph that already contains, say, entities and relationships derived from structured data sources.
-
Constructing ontologies—the data model of a Knowledge Graph—with LLM. We’re using LLM to automate the creation of, well, lots of stuff because life is too short to require every subject-matter expert to become a knowledge engineer, too.
So we’ve taught LLM to create ontologies from plain language prompts. This one is just easier to show you than to describe in words. Behold, the Stardog Designer ontologist-in-a-box.
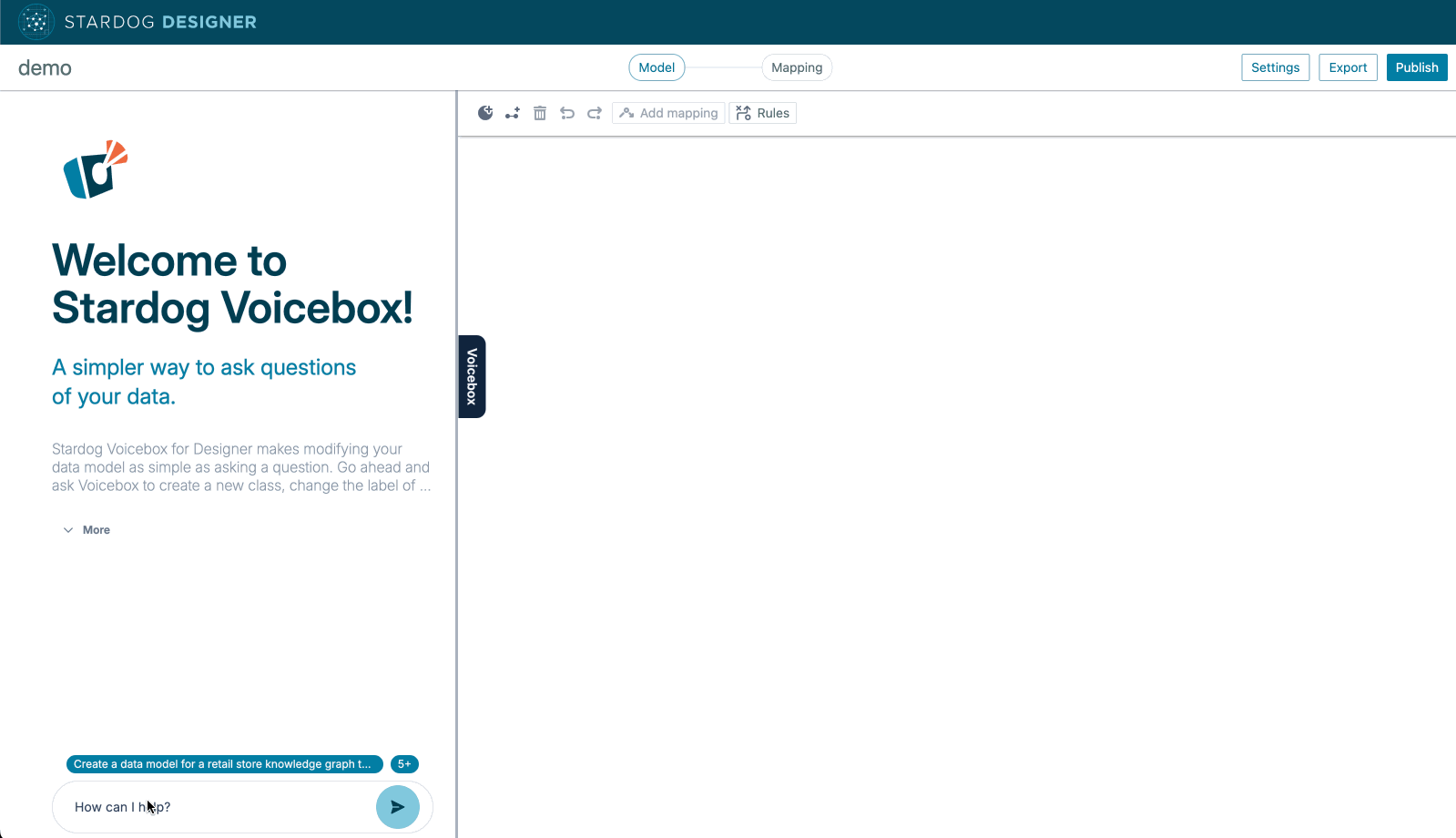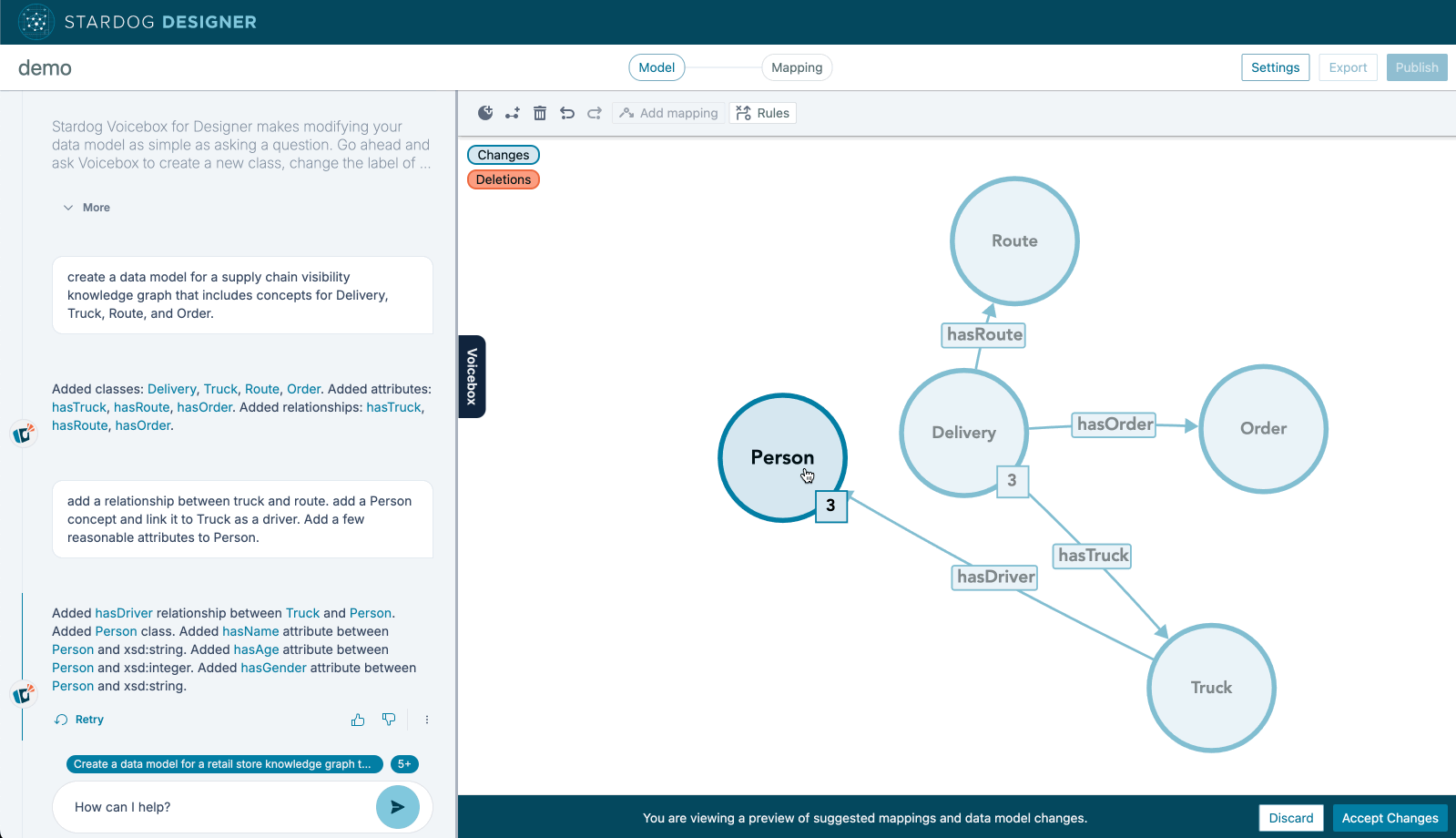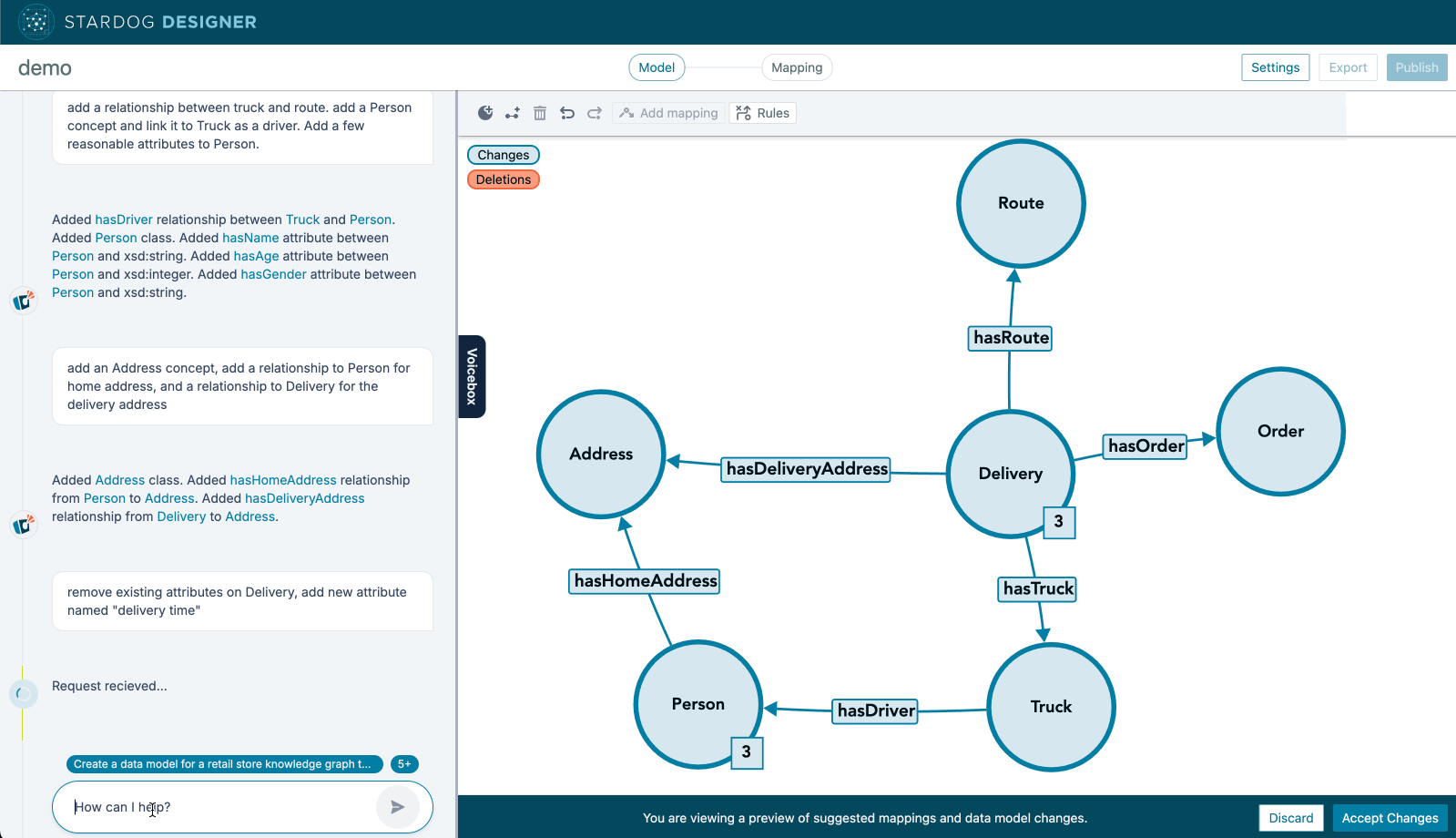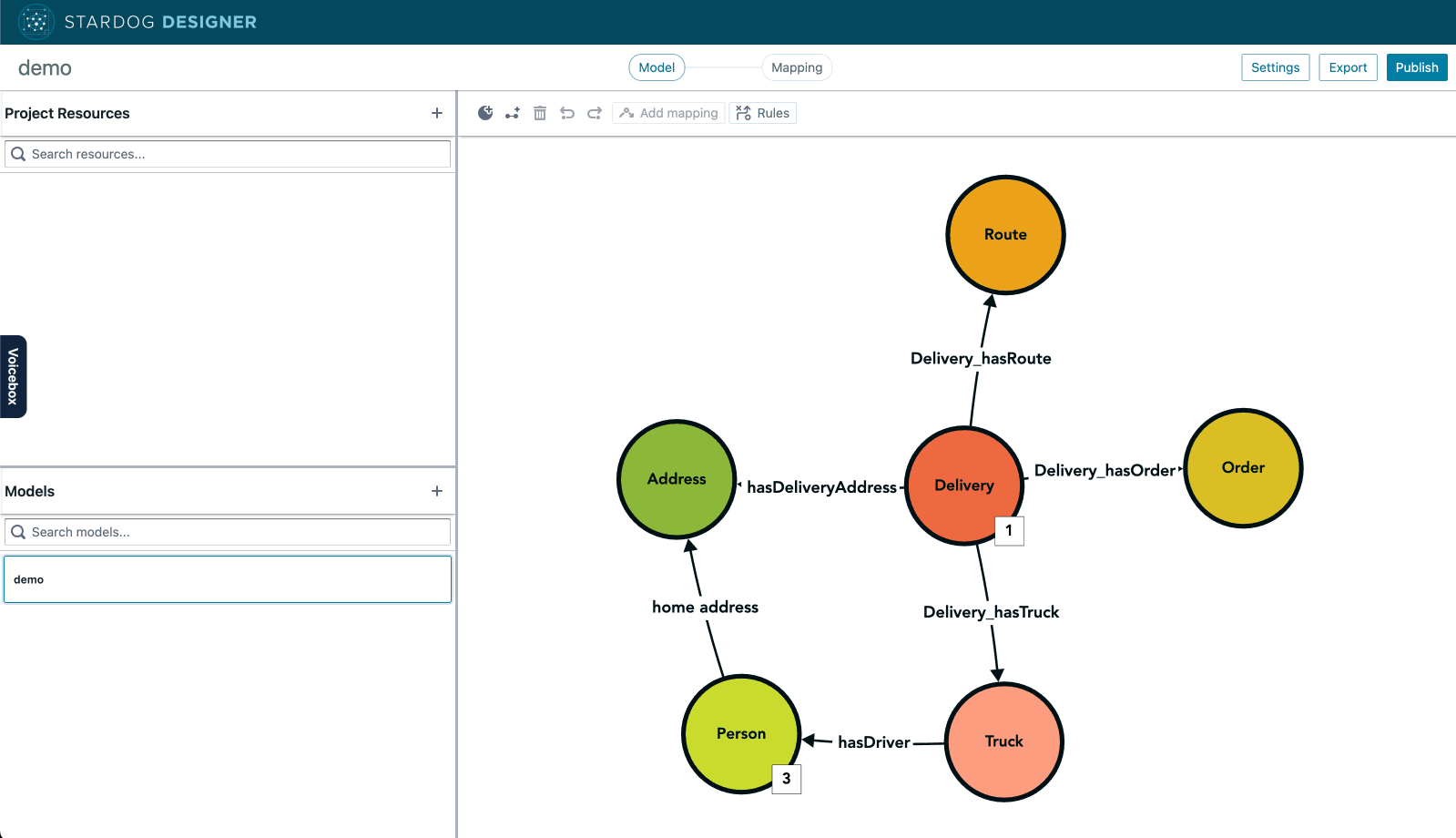
This capability which we are shipping now also generalizes over the next few releases to include adjacent capabilities like—
- Enriching existing ontologies with Designer running asynchronously in the background to offer modeling suggestions like new subsumption relationships, new node classifications and predicate types, and disjointedness axioms. We’ve taught LLM to use Designer as a tool which means the results of all this ends up queued into Designer for a person to accept before changes are applied to real ontologies. That makes this, technically, semi-supervised automation, and we think for a host of UX reasons this is the right approach. We will extend Voicebox Designer integration from ontology-creation and maintenance to additional capabilities over the next few quarters including Stardog rules creation and maintenance and SHACL data quality constraints.
The goal here is to automate the Knowledge Engineering discipline such that a Subject Matter Expert plus Stardog Voicebox is, ipso facto, a Knowledge Engineer, able to create and maintain enterprise Knowledge Graphs based on their domain expertise (hence, SME) and use of Stardog Voicebox via plain language UX.
-
Constructing Virtual Graph mappings—query-time silo unification—with LLM. I’ve been suggesting VG mappings for some time and the results have been acceptably decent; however, LLM has some unique capacities around understanding sparse context and we’ve been investing more time in improving the quality (in terms of F1) of auto-mappings.
-
Fine-tuning—there’s empirical evidence to suggest that using domain-specific ontologies (of the sort that Designer now semi-automates!) as PEFT input to LLM improves accuracy and lowers hallucination frequency. We’re working on automated PEFT for customer data that lives in Stardog (including ‘virtually living’ via our federated VG capability) using among other inputs customer ontologies:
6. Guarding—Post-generation Hallucination Detection via LLM and KG. In short, a Fusion Platform like Stardog KG-LLM queries, grounds, guides, constructs, completes, and enriches both LLM, their outputs, and Knowledge Graphs themselves. Stardog is a virtuous cycle for GenAI.
Again, Gartner nails this directionally; while I don’t agree necessarily with some of the details here, this isn’t about details but about Big Picture alignments.
We’re also working on some more far-out capabilities I’m not going to talk about just yet, except to say that there’s a very interesting collision of biz value to automate around LLM world models, symbolic knowledge distillation, and Knowledge Graph ontologies. Stay tuned.
Gartner is Aggregating Demand
Gartner gets it exactly right. Here’s the image you’ve probably seen. I ❤️ this image.
GenAI Infrastructure Investment Decision Tree
| Hallucination Sensitivity | Relevant, Addressable Data | Other Constraints | |
|---|---|---|---|
| Plain Ol’ RAG | None to Low | Business documents only; no structured data. | Reduces hallucinations but does not eliminate them; not appropriate for high-stakes use cases in regulated industries. |
| Generic Graph RAG | Low | Structured data may be considered but no principled unification of structured, semi-structured, and unstructured data sources across the enterprise. | |
| Salesforce Einstein | Low | Salesforce apps-resident data only | Doesn’t support data paths questions driving business value. |
| Microsoft Copilot | Low | Microsoft Office data plus Microsoft’s basic business artifacts: Word, Excel, etc. | No access to data that lives outside of the Microsoft universe, including on-premise and other proprietary data. |
| OpenAI ChatGPT | Low | Background knowledge; i.e., “what everyone should know about the world” | Critically, ChatGPT doesn’t know anything about enterprise knowledge. |
| Databricks TAG | Low to Medium | Relational data (regular, non-sparse, not highly-connected) | Cannot support data paths questions driving business value. |
| Stardog Voicebox | Low to High | Any database, document, or API; structured, semi-structured, unstructured data. | See Voicebox in the Sweet Spot to learn when Voicebox is the best choice. |
| Safety RAG | Medium to High | Any database, document, or API; structured, semi-structured, unstructured data. | Requires unstructured extraction and KG-ingest processing; Stardog includes that capability but other graph systems do not. |
| Stardog Fusion Platform | Low to High | Any database, document, or API; structured, semi-structured, unstructured data. | Connecting data silos, structured data sources, and database-resident knowledge |
Knowledge Graph and RAG—Sharing Accenture’s Learnings
Teresa Tung, Global Data & AI leader at Accenture, shared Accenture’s perspective on the importance of fusing LLM and Knowledge Graph in a single platform.
Accenture’s strategic investment in Stardog as the leading enterprise knowledge graph platform enables organizations to do more with, and achieve greater value from, their data in this age of generative artificial intelligence.
In a 2024 Accenture survey of 2,000 CxOs, 65% said that building an end-to-end data foundation was one of the top obstacles to scaling generative AI. This end-to-end data foundation breaks down silos and makes quality data available by managing the entire data lifecycle—from initial collection to post-use management.
Knowledge Graphs, with their ability to make real-world context machine-understandable, are used by companies to facilitate better enterprise data integration and unification. Instead of integrating data by combining tables, data is unified using a knowledge graph’s ability to endlessly link concepts—without changing the underlying data. This ability to unify data serves to connect data silos and produces a flexible data layer across the entire enterprise, which is key to sourcing data-as-fuel for the GenAI enterprise insight engine!
Generative AI and LLMs need to work with knowledge graphs to be relevant when answering questions to draw information that’s been contextualized with the user’s domain and data. This capability benefits users who want to explore data their own way, while also giving enterprise engineering teams the ability to extract structured data efficiently and meaningfully from documents.
We’ve discovered that Knowledge Graphs is a dominant design pattern in making RAG and LLM agents deliver value fast with strategic relevance. Stardog’s fusion of Knowledge Graph and LLM is a leading-edge solution that we’re excited to partner with.
Wrapping Up
Stardog Fusion Platform combines the best of Knowledge Graph, LLM, and, critically, blazes the path forward on fusing KG and LLM capabilities into a coherent whole.
Let’s go back to something I wrote in 2017:
A Knowledge Graph about X is a software platform that can answer any question about X because it knows everything about** X that’s worth knowing.
I like this definition because it gets at the two most important features of an enterprise Knowledge Graph:
- Its primary function is to answer questions about some domain.
- It answers questions by connecting data in a rich, contextualized, semantic way that counts as “knowing” about the domain, not just storing raw data or generating the next-most-probable token about it.
When it comes to AI in the enterprise, safety and accuracy are a function of completeness (all the correct answers) and soundness (only correct answers, that is, no wrong answers). But that’s exactly what the ideal data strategy for Enterprise AI is a function of, too. Win-win!
Why all the buzz about LLM and Knowledge Graph? Why did we build this Fusion Platform? It comes down to four big factors—
- Enterprise AI must be grounded in your enterprise data
- Only LLM outputs that are grounded are safe
- Knowledge Graph unifies documents and databases, which RAG alone cannot do; but if you’re going to do RAG, do it right with Knowledge RAG
- Timely, accurate insight on-demand is the biggest win of enterprise AI
If you want to win with GenAI in the enterprise, you have to understand the requirements and use cases of your customers. And in regulated industries and high stakes use cases—like fraud, compliance, and risk in Financial Services; providing Decision Advantage to the modern warfighter; or helping pharma and manufacturers manage a global supply chain end-to-end—you need safe, hallucination-free insights that are rooted in enterprise data sources and are always timely, accurate, and trustworthy. You also need answers and insights that are comprehensive, so you can’t choose platforms and solutions that can only deal with documents and unstructured data.
The only way to win with AI in the enterprise is to have the right data strategy, and the key to data strategy for AI is to deploy a platform that offers the best of LLM and knowledge graph.
