Today we introduce Safety RAG (SRAG), the underlying GenAI application architecture for Stardog Voicebox. Our goal is to make Stardog Voicebox the best AI data assistant available to help people create insights fast and 100% hallucination free.
Hallucinations are bad for business and threaten AI acceptance (see here, here, here, here, here, here, here, and here). Enterprise GenAI, especially in regulated industries like banking, pharma, and manufacturing, needs a corrective supplement to RAG-and-LLM, which alone is insufficient to deliver safe AI. SRAG takes the “data matters more than AI algorithms” rubric seriously and literally. Safety RAG is more safe than RAG because it’s intentionally designed to be hallucination-free, and it’s a more complete data environment for enterprise GenAI. SRAG extends AI’s data reach from documents-only (RAG) to databases and documents.
In this post we’ll discuss, first, why hallucinations make RAG-with-LLM unsafe for high-stakes enterprise use cases; you can find more detail in our LLM Hallucinations FAQ. We take a deep dive, second, into Safety RAG: its reference architecture; how SRAG handles document-resident knowledge (DRK); how SRAG uses records-resident knowledge (RRK) to ground LLM outputs; and, then, how SRAG can make RAG-with-LLM apps safer. Third, we take a glance at the novel agent workflow pattern that Voicebox and SRAG use internally.
Two Unappreciated Problems with RAG-and-LLM
There are two obstacles with the dominant GenAI application pattern in enterprise settings:
- RAG-and-LLM isn’t safe because—hallucinations
- Hallucinations are good for some B2C use cases
- Hallucinations are very bad for high-stakes use cases especially in regulated industries
- RAG-and-LLM is incomplete with respect to enterprise data
- RAG doesn’t work with knowledge that’s database-resident
- RAG is intended for document-resident data, but there’s no enterprise on the planet that needs GenAI benefits for documents only
Safety RAG addresses both of these issues by seeing them as two sides of the same coin.
Introducing Safety RAG
The basic idea of SRAG is to complete GenAI’s reach into enterprise data by unifying enterprise databases into a knowledge graph and then using that knowledge graph with Semantic Parsing to ground LLM outputs, thereby eliminating hallucinations. SRAG is fundamentally premised on bootstrapping a KG from databases and then using that KG to filter hallucinations that occur when LLM extracts knowledge from documents.
RAG versus SRAG: What’s the key difference?
RAG trusts LLMs to give users insights about the world; RAG augments raw LLM output with some contextualized enterprise data extracted from enterprise documents only. SRAG via Voicebox uses LLM to understand human intent but gives users insights by querying a knowledge graph that is (1) hallucination free and (2) contains knowledge derived from enterprise both databases and documents.
LLMs are the source of hallucinations. LLMs used internally inside SRAG systems absolutely will hallucinate like every other LLM; but SRAG systems are free of hallucinations if they never show users ungrounded LLM outputs. Hallucination-free is a software application property, not a LLM property.
Safety RAG Reference Architecture 1.0
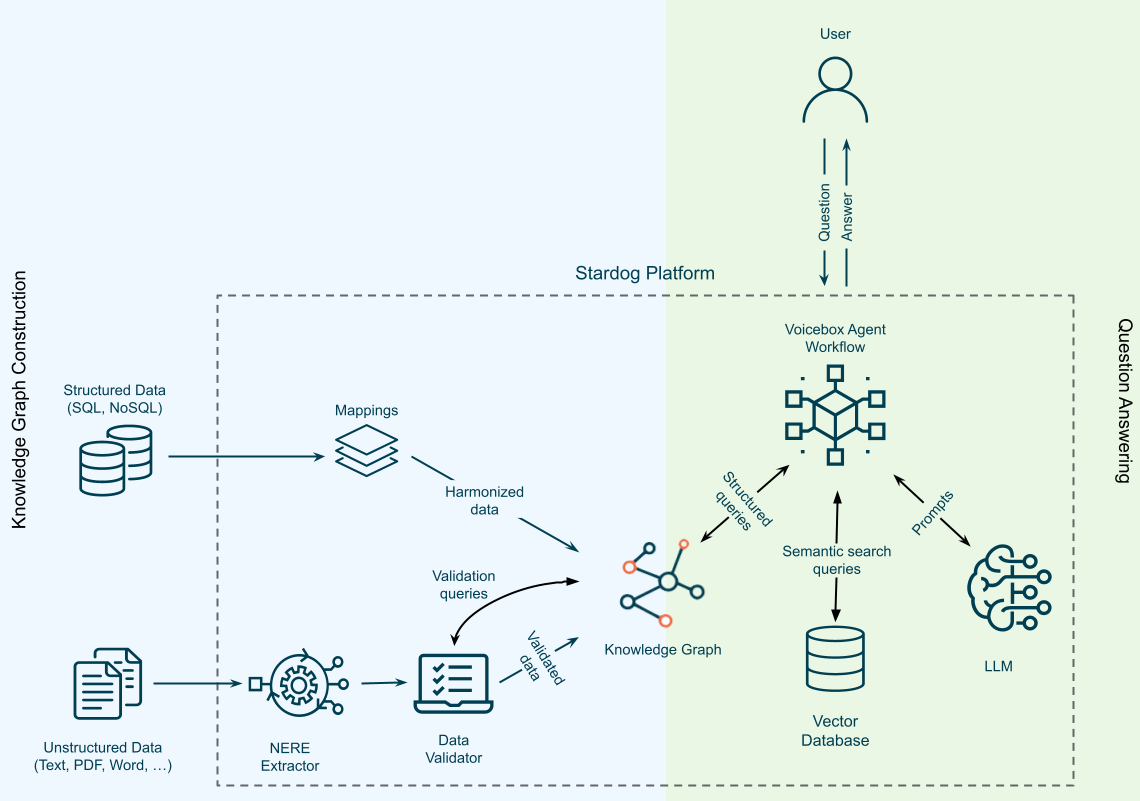
Safety RAG grounds LLM outputs in enterprise knowledge graph to filter hallucinations before they can do harm to users.
We can see the main components of SRAG. On the left we have enterprise data sources grouped into two types: first structured and semi-structured; second, unstructured.
Structured Data in Safety RAG
Structured data sources can be SQL or NoSQL databases and Voicebox’s automation services map them to a unified and harmonized graph data model. Stardog Designer also uses Voicebox to customize graph data models based on Knowledge Packs that we’ve developed for key use cases in targeted verticals, largely in partnership with Accenture and other alliance partners. Voicebox helps to semi-automate this process where users can verify mappings generated by Voicebox.
Unstructured Data in Safety RAG
Unstructured data sources can be any kind of document with text content like PDFs or Word documents. Voicebox uses customized LLM, agents, and specialized data extraction transformers to extract Named Entities, Events and Relationships (NEER) from text content. Of course this LLM-powered extraction model will hallucinate or otherwise generate incorrect data.
But that’s okay because these are intermediate outputs and won’t be shown to Voicebox users without further processing. Raw extraction results are validated using structured data unified in the knowledge graph. This process is called grounding and it’s the reason that AI safety is connected to AI data reach.
For example, if a relationship between two entities has been extracted from a document, then the first step of validation is to locate the corresponding entities in the graph. Then the relationship type is located in the KG and the matched entities are checked if they satisfy the typing constraints for the relationship. There may be other constraints associated with the relationship, e.g. a uniqueness constraint, that will also be used for validation. If any of these validation steps fail the extracted information isn’t ingested and is rather categorized as potentially unsafe and is then available for additional processing, including curation or supervised verification.
Safety RAG Uses LLM-Powered Agents
At the end, we have a knowledge graph whose backbone is the structured data sources within the enterprise that has been augmented and contextualized and in some cases completed by safe and verified information from unstructured data. When a user asks a question, Voicebox will use LLM to perform Semantic Parsing; that is it will convert the user’s natural language question into one or more structured queries over this KG.
Stardog Voicebox uses several agents to accomplish the job of being a fast, safe AI Data Assistant, which also means leveraging lots of LLMs, not just one. A brief overview of the agent-powered “jobs to be done” includes:
- Working Memory Agent. One agent is responsible for interpreting the conversation history to clarify and disambiguate user’s question based on previous messages exchanged.
- Schema Agent. Responsible for isolating the part of the data model that the question from the user implicates.
- Point Agent & Multihop Agent. There are various agents responsible for answering different kinds of questions, e.g. questions that require a single node in the knowledge graph versus questions requiring multi-hop traversals of many nodes.
- Router Agent. An agent responsible for identifying which one (or several) of the available agents and LLMs is best suited for answering the user question.
- Query Agent. Finally, there are agents responsible for verifying and validating the structured queries generated by these agents.
These agents rely to greater or lesser degree on LLMs, which can hallucinate while generating tokens, but these hallucinations can be managed because Semantic Parsing means that Voicebox is generating logical language expressions that are validated and executed by the Stardog platform. So if hallucinations occur in intensity or amount beyond what Voicebox can repair, in the SRAG worst case failure mode, Voicebox fails to generate a valid query and tells the user that it cannot answer.
Sometimes safety requires saying “I don’t know”. That’s real AI safety: help the human user by augmenting what they know and, when that can’t happen, then do no harm.
There’s more about Stardog Voicebox’s novel approach to agentic workflows for LLM in The Agentic Present: Unlocking Creativity with Automation.
Safety RAG Design Goals & Assumptions
Our motivating design assumptions and intuitions for SRAG include the following:
- Most enterprise knowledge comes in two forms: databases and documents.
- Yes, there are other forms, but we ignore them here without loss of generality.
- Enterprise data is a spectrum of types. Database records are inexpressive documents; documents are database records with bad field markers and a strange query language.
- A GenAI system’s “data reach” is the range and breadth of the enterprise data spectrum that it can understand and process on users’ behalf.
- Safety is a system property, not an LLM property. User-visible hallucinations are a function of an unsafe system design that trusts ungrounded LLM outputs.
- Safety is a system property because LLMs are inherently unsafe, that is, they hallucinate intrinsically.
- SRAG never trusts an LLM alone to tell a user anything about the world.
- An LLM isn’t a database! RAG-with-LLM doesn’t change this basic fact in any way.
- All user-visible or user-dependent system outputs must be grounded in trusted data sources via knowledge graph groundings.
- An AI system is free of hallucinations if a user never sees hallucinations and nothing the user sees depends on hallucinations.
- LLM should be used to detect human intent algorithmically.
- The value of GenAI in a high-stakes use case is proportional to its safety requirements. The utility of RAG-with-LLM in a high-stakes use case is inversely proportional to its safety requirements.
- Semantic Parsing is safer than RAG because its failure mode is more acceptable than RAG’s.
- In high-stakes use cases Semantic Parsing’s failure mode refusing to guess, saying “I don’t know, ask again in some other way” explicitly is safer than RAG’s failure mode, which is (for our purposes here) hallucination.
- SRAG bootstraps knowledge graph construction from enterprise databases via semi-supervised schema alignment.
- Extract knowledge-named entities, events, relations (NEER) from enterprise documents using LLM; represents this knowledge as semantic triples; and persists the grounded subset of triples to knowledge graph.
- Ungrounded NEER triples are likely one of three things:
- hallucinations to be discarded;
- otherwise stored for later processing but never written to knowledge graph until grounded;
- may be new relationships to force schema evolution; whether or how new relationship types are used to evolve data models is a business question and out of scope for SRAG.
- Ungrounded NEER statements extracted from documents may be true but aren’t safe and can’t be shown to users; see #1 and #2.
- Hence, for the sake of safety, SRAG doesn’t write ungrounded NEER to knowledge graph, at the potential cost of incompleteness, unless NEER can be grounded otherwise or manually curated.
The Safety RAG Advantage is Safe Insights at Speed!
Our focus is fast, accurate insights from data through conversations with Voicebox, the AI Data Assistant. SRAG is carefully designed to deliver that value to our customers and users. Better insights are a function of user’s being able to access all the relevant data and that’s what SRAG does.
