There is no question that LLMs make new capabilities possible for knowledge graphs that would otherwise require people to have very specialized technical knowledge. In a previous post — where we answered the question, how does Stardog use AI? — we discussed in depth how Stardog uses Hybrid AI, including in Stardog Voicebox, which leverages LLM to build, manage, and query knowledge graphs using ordinary language.
But the question today goes the other way around: How does AI use Stardog? How does enterprise generative AI use an enterprise knowledge graph? We will answer that question in detail below, but let’s give a very simple and accurate answer now:
AI uses Stardog in the same way that an engine uses fuel injectors; an EKG provides data (fuel) to AI, which acts here as (part of) a human-aided and human-aiding engine for insight.
And, just as in the previous post, where we discussed how Stardog has pioneered Hybrid AI — that is, both symbolic and statistical AI and their interdependent interactions, what is sometimes called neuro-symbolic AI — so, too, here we discuss how Stardog’s Hybrid AI platform, using again both symbolic and statistical techniques, provides crucial value to generative AI in the enterprise.
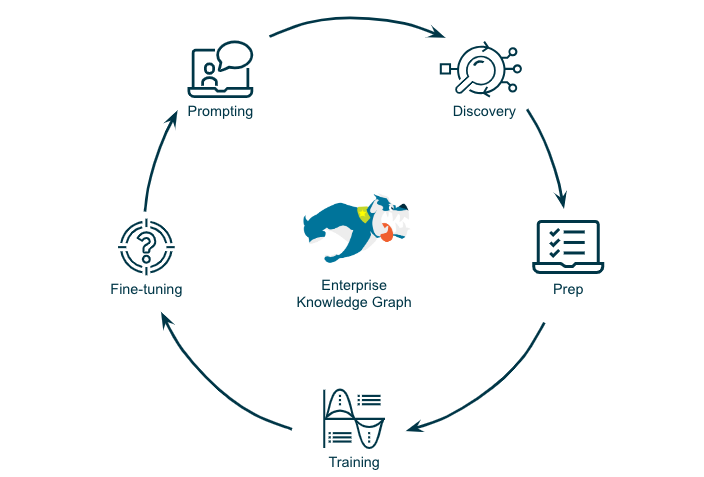
The full-spectrum data management lifecycle for generative AI
Supporting the Data Management Lifecycle for Generative AI
So what’s the big idea here? For generative AI to really work in the Enterprise, two crucial issues have to be addressed and an EKG platform like Stardog is crucial to addressing them:
- Providing a flow of trusted, reliable, and accurate enterprise data in all phases of the generative AI lifecycle
- Controlling the tendency of LLMs to hallucinate
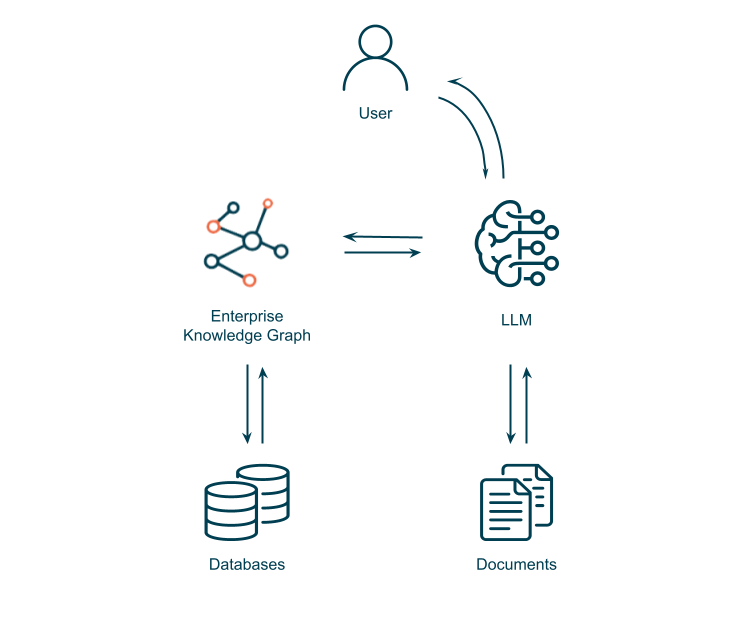
In this approach EKG provides data lifecycle management for LLM and also offers Grounding Services, i.e., ground truth to control hallucinations, while LLM provides to EKG an ideal abstraction over human language messiness, both at the level of ordinary language inputs but also as a way to handle static language messiness, that is, unstructured enterprise data sources.
Discovery → Prep → Training → Fine tuning → Dynamic Prompting
Stardog’s unique ability to virtualize and federate any data source within the enterprise to create a unified knowledge graph is an ideal way to create training datasets for LLMs. The data in knowledge graphs are contextualized and use business terminology. This is a very important point in the context of LLMs since the representation of business objects and relationships in knowledge graphs is closer to how people think and talk about the business which is not the case for relational tables where everything needs to be turned into a rigid tabular format.
Stardog contributes to each phase of the enterprise data management lifecycle for LLM by providing contextualized data access to timely, accurate, and trusted enterprise data sources:
- Discovery: Stardog can help to identify data sources that are relevant to the LLM model by means of it’s “catalog of catalogs”, i.e., a unified enterprise metadata knowledge graph. Stardog can assess the quality of the data by providing metrics such as data relevancy (to the task of the LLM under training), data completeness, data consistency, and data freshness.
- For example, if an organization is interested in developing an LLM model for customer service, Stardog can be used to identify all of the data sources that contain customer information, such as customer support tickets, customer surveys, and product reviews.
- Prep: Stardog can help to create a training dataset that is representative of the data that the LLM model will be used to process by providing a way to join and merge data from different sources. Stardog can help to split the dataset into training, validation, and test sets.
- For example, if an organization is interested in developing an LLM model for product recommendations, Stardog can be used to join data from product catalogs, customer purchase history, and customer reviews to create a training dataset that represents the different ways that customers interact with products.
- Training: The initial training phase of an LLM involves using a very large text corpus, typically on the order of trillion tokens. This is time-consuming and very expensive but we expect most beneficiaries of LLM won’t have to train models from scratch. There are many open-source foundational LLMs that provide excellent starting points.
- Fine Tuning: The primary method of updating a trained model in enterprise LLMs is to fine-tune it with new data and Stardog’s ability to connect unstructured, semi-structured and structured data makes it the perfect hub to bring all the relevant information together to feed into the fine-tuning process.
- Dynamic Prompting & Re-prompting: Even a fine-tuned LLM might not have all the recent data so Stardog can be used to retrieve the most up-to-data relevant for the user request and include that context into the prompt that will be sent to the LLM. Typically a vector database is used for determining what is relevant but a vector database by itself is not sufficient as it does not have the metadata that the knowledge graphs provide and requires all the data to be loaded into a single location. Stardog can re-prompt the LLM model if it does not generate the desired output by querying the EKG for different prompts, contexts, and background data.
Stardog provides a queryable data fabric for all enterprise data. In short, Stardog makes the enterprise data management lifecycle for LLM more efficient, effective, and scalable.
Controlling Hallucinations with Knowledge
One of the obvious LLM challenges is the Hallucination Problem. Responses from an LLM, despite their rhetorical confidence, can be completely fabricated. But at least they sound just as confident as the other things an LLM says! Knowledge graphs address this issue by providing a curated and structured representation of factual knowledge that may span the entire enterprise. LLMs can utilize this valuable resource to fact-check information, cross-reference claims against the knowledge graph, and provide users with more reliable answers.
How EKG and LLM Are Better Together Than LLM Alone
Retrieval Augmented Generation (RAG) is a paradigm for text generation where an AI model first retrieves relevant information from a large-scale dataset, in practice typically a vector database, and then uses this information for generation. It’s a combination of retrieval-based and generative models, aiming to combine the best aspects of both.
A fusion of EKG and LLM control hallucinations in three ways:
- Post-generation Verification: After text is generated, a knowledge graph is used to verify the information in the text, potentially identifying hallucinations.
- Direct Querying: In the process of text generation, the model may query a knowledge graph for specific information to use in the generation, which could help prevent hallucinations by providing the model with accurate information directly.
- Training Enhancements: A knowledge graph could be used during the training of the RAG model to teach it to avoid certain types of hallucinations. This would involve using the knowledge graph as a source of “ground truth” during training.
In order to use knowledge graphs to fact check and augment responses from LLMs, the LLM should be capable of generating a plausible response for the given prompt which brings up the bigger bottleneck for using LLMs in the context of a large enterprise:
Foundational LLMs are trained on publicly available datasets and training is not continuous; these models used inside an enterprise have no information about the enterprise’s proprietary data universe; in the rare case that enterprises train their own models from scratch, that training is not continuous, and models don’t know anything about what’s changed since training ended.
Solving this challenge is where the fusion of EKG and LLM goes beyond the current consensus stack of LLM-agents-vector-database coupled directly with, say, a data lake or data warehouse.
LLMs Must Be Fed Timely Data
Even when the largest enterprises — probably the first was Bloomberg — train LLM models from scratch using private enterprise data, which avoids the first issue described above, the training effort, cost, and time is such that enterprise LLMs will often be outdated before they’re complete.
Hence, EKGs play a critical role in filling the gap between what the LLM could possibly know and what new data or insights have been generated by the enterprise since the last LLM update.
We can overcome the Freshness Problem, just like the Hallucination Problem, by fusing LLM and EKG. Typical RAG applications use a vector database only to retrieve relevant information for user inputs and include that additional context in the prompt sent to the LLM. However, vector databases don’t contain metadata or enterprise policy invariants, and they do not provide search or query capabilities beyond semantic similarity. Complementing a vector database with an EKG retrieves richer and more accurate and more timely context to be included in prompts.
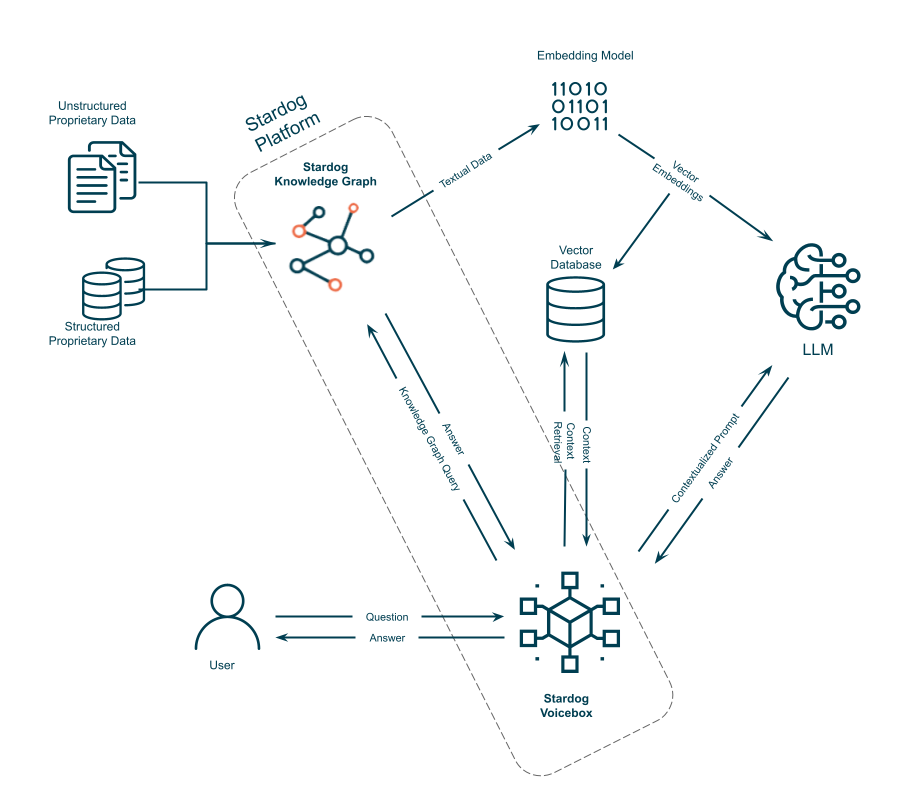 A generative AI architecture with knowledge graph and vector database integrations
A generative AI architecture with knowledge graph and vector database integrations
However, there are still shortcomings of the RAG approach that makes it unsuitable as a high-quality, long-term solution by itself. First, the initial context retrieval has a disproportionately high impact on the overall quality of the final response from LLM. If the vector database or the EKG fails to identify documents relevant for a question, then results will be incomplete or incorrect regardless of how powerful the LLM is.
The context window for LLMs has a limit ranging typically from 2K to 64K tokens; but even as these limits increase, the question is what increases faster: enterprise data volumes or context windows for LLM? Which means we cannot always provide all the relevant context via prompts. Even if you believe context windows will win, increasing the context window size increases response times, threatening to make the whole approach infeasible.
So RAG with prompting works, but it doesn’t work forever. Hence, the alternative to RAG for augmenting LLMs with enterprise data is fine-tuning. Fine-tuning takes an LLM — perhaps foundational but not necessarily — that already has general knowledge about the world and adjusts the weights within the model to encode new — probably domain-specific, but not necessarily — knowledge.
One bit of good news, both for budgets and the planet, is that fine-tuning is basically free. The quality and the breadth of the training dataset is crucial in fine-tuning just as in any other machine learning task. This is why knowledge graphs are a vital part of LLM data management lifecycle: They provide a mechanism to collect, organize, and update structured, semi-structured, and unstructured enterprise data.
In summary, Stardog EKG lets you build a connected view over an enterprise’s complete data landscape which can then be used to train, prompt, and fine-tune the LLMs; provide context for user questions in a RAG-style approach; and verify the results computed by the LLM against actual data. Stardog Voicebox is the orchestration engine between the EKG and the LLM controlling the information flow between these components.
Get Started Today
We just launched a Stardog Voicebox Early Access program, only available in Stardog Cloud. Use an LLM with an EKG and rest assured that none of your enterprise data is headed to OpenAI or anyone else.
