
How to Achieve Data Democratization with your Data Lakehouse

Get the latest in your inbox
Get the latest in your inbox
Rapid innovation and disruption in the data management space are helping organizations unlock value from data available both inside and outside the enterprise. Organizations operating across physical and digital boundaries are finding new opportunities to serve customers in the way they want to be served. These organizations have done so by connecting all relevant data across the data supply chain to create a complete and accurate picture in the context of their use-cases. In other words, creating a data-centric culture that looks to democratize data across all aspects of their business functions and operations for richer, faster insights that turn into actionable intelligence at the speed of business.
This data-driven approach is demonstrated in the results of organizations considered Data and Analytics Leaders versus those considered Laggards. According to a recent Accenture study, “Closing the Data Value Gap,” 77% of the leaders are using data across their organization to reimagine their product and services, 70% see tangible results in terms of operational excellence, optimized customer experience, and 60% use data to make a business case to reduce internal costs. So what is driving that sea-change for them and what continues to haunt the rest in their ability to harness the full power and potential of data?
D&A Leaders have made tangible progress in their effort to wrangle all data from within and outside their organizations. Innovative companies like Databricks and their Data Lakehouse approach are helping many organizations co-locate data from across the organization with cost-effective approaches for storage as well as opportunities to operate on all that data at the computational layer to leverage the benefits of AI. These landing zones have effectively reduced the need for organizations to maintain expensive brittle ETL pipelines against traditional structured and costly data warehouses on-prem. So, yes, while access to all the data has become a reality, it is far from being democratized and available to the very users that need rapid insights to keep pace with the change in business dynamics and consumer preferences, in other words, enabling non-technical users to self-serve and collaborate. Sure, hooking up a BI tool like Tableau directly to Databricks might seem to accomplish that last mile, but there’s a lot to be desired in terms of reducing latency, promoting collaboration and re-use with an easy to understand vocabulary, providing context by connecting data across domains, enabling self-serve through data exploration and enriching analytics by inferring new insights.
The idea of a semantic layer is not new. It has been around for over 30 years, often promoted by BI vendors helping companies build purpose-built dashboards. However, broad adoption has been impeded, given the embedded nature of that layer as part of a proprietary BI system, often too rigid and complex and suffering from the same limitations as a physical relational database system which models data to optimize for its structured query language rather than how data is related in the real world—many-to-many. Introducing a knowledge graph powered semantic data layer that operates between your storage and consumption layers to enable that last mile by addressing the gaps I highlighted above. With Stardog, we anticipate a world that despite its best effort will continue to silo data (perhaps for the right reasons, one can hope, like in multi-cloud apps), demand access to just-in-time data and insight, communicate and share a common vocabulary about things (business concepts) not strings (technical metadata), and explore and exploit connections across their data universe by leveraging the often hidden value, i.e, context, to gain a more complete and accurate understanding of any given scenario.
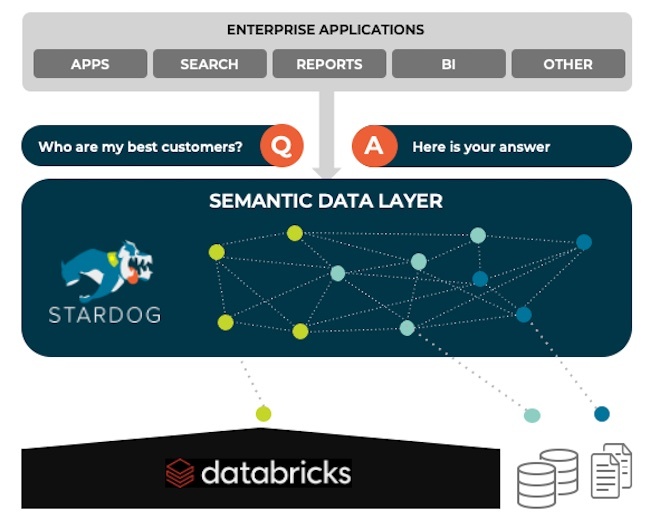
It all starts with a semantic model that represents a canonical (logical) view described as a set of interrelated business concepts that provide the foundation of good data uniformity, a basis for data story-telling and explainable AI, all while decoupling the location and complexity of the underlying data structures of the various sources of available data. This common vocabulary, for example, can complement pre-described (meta)data catalogs, like Unity from Databricks by tying it to the semantic layer and enabling faster build-out of data pipelines via Delta Live Tables. End-users can start by asking questions based on business concepts and the inter-relationships between them via the semantic layer. Those concepts, in turn, map to the underlying metadata (tables, views, attributes) that can help facilitate rapid pipeline development for sharing data across applications through the creation of metadata-informed data pipelines. The semantic layer also enables users to run fast and flexible federated queries between Databricks and data in other sources—structured, semi-structured, or unstructured—in support of ad hoc data analysis. Linking and querying data in and outside of Databricks enables just-in-time cross-domain analytics for richer, faster insights without creating data sprawl challenges for the organization. This drastically improves the productivity of the BI and Data Science teams by saving time and money spent on data wrangling and data movement activities, easily sharing their findings through visualization that promotes data story-telling and enable self-service analytics directly inside their existing investments like Tableau or Jupyter notebooks through the re-usable semantic layer.
This data architecture is key to accelerating value from your investments in Databricks and Tableau and finishing the last mile in your journey towards a data-centric enterprise. A knowledge graph powered semantic data layer becomes pivotal and powerful in enabling rapid innovation by connecting all relevant data across functional domains for richer insights, enabling a data-sharing culture that promotes findability, accessibility, interoperability, and reusability and closing the value gap from potential value to realized value of your single most valuable asset—data!
Using a Knowledge Graph to Power a Semantic Data Layer for Databricks by Prasad Kona (Databricks) and Aaron Wallace (Stardog).
Knowledge graphs make it easier to feed better and richer data into ML algorithms. The inherent traits of knowledge graphs posit them as a top tool of modern AI and ML strategy. Let’s examine a few ways in which they help.
Practical steps for building knowledge graphs: powerful tools for linked data, data integration, and data management. Scale all those use cases that have been inspired by data science. Increase your number of users, as needed. And spread the use of data itself. Do you really need a knowledge graph? Data rules the world. But organizations struggle to leverage that data for a competitive advantage. Raw, uninterpreted data in a system somewhere isn’t very helpful.
How to Overcome a Major Enterprise Liability and Unleash Massive Potential
Download for free