In the GenAI era, the disruptions are coming fast and furious and continuously, in no small part because GenAI is making hardware cool again, but also because the era started during a secular cycle of bearishness about cloud cost and value. After 20 years of cloud growth and investment, the Fortune 1000 spent 2022 and most of 2023 pushing back on cloud spend.
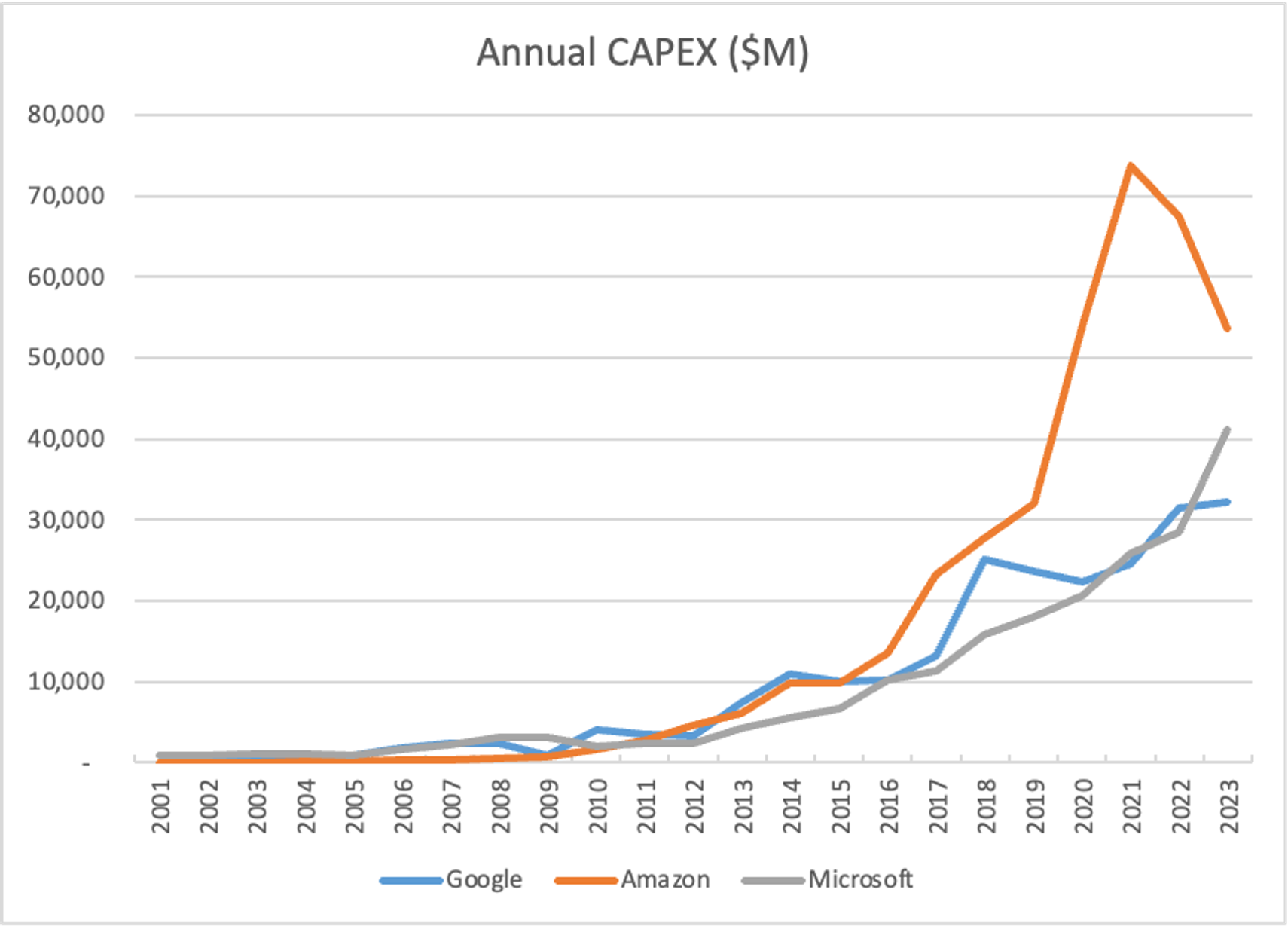
Source: Follow the CAPEX: Cloud Table Stakes 2023 Retrospective*
One of our moves in response is to build a private GPU cloud facility, which is more than little contrarian obviously. It’s called SKATHE and launches into preview release next week.
What SKATHE is and What it’s Becoming
SKATHE is a private GPU cloud adjacent to Amazon’s us-east-1 in the best data center market on the planet, Ashburn, Virginia. When I say “adjacent”, I mean literally; our data center facility is less than 1km from AWS. Not only is this a great place to put SKATHE-1, but it’s also halfway between my home and the barn where we keep a horse. Propinquity matters!
Source: https://www.datacentermap.com/usa/virginia/ashburn/
SKATHE is a compliant private GPU cloud, that is, a compute facility available to Stardog for processing the GPU compute traffic of Stardog Voicebox. SKATHE is a hybrid cloud: it processes—for now—GPU load but the CPU load remains in AWS (and, soon, Azure). As we expand SKATHE facilities globally over the new few years, we anticipate two expansion vectors: first, global expansion; and, second, compute expansion, to include non-inference GPU compute loads like GNN, vector embeddings, finetuning, and model training.
We expect as Stardog grows rapidly over the next few years that additional SKATHE facilities will be required in the markets we serve, including NYC—where our new HQ is now—the West Coast, Texas, London, Germany, and so on. Time and the market will tell, but we’re already seeing significant adoption.
Here’s a secret. “The cloud” is just someone’s data center where you can’t get a particular kind of access. There are other data centers where you can get that access. It’s not deep!
Building a Private GPU Cloud is Smart
We’ve made this bet because in the end it’s good for our business and good for our customers, too. There are two areas in which SKATHE will benefit Stardog and its customers. The first is about design, implementation, and quality. I call it “full-stack control”. The second is about big industry trends that GenAI has momentarily stalled but which will return in full force soon enough.
Full-stack Control is the 🔑 to UX & to Unit Economics
Okay, so let’s just baseline on a very simple fact: startups need growth but valuable startups that turn into real businesses need world-class unit economics, too, since that’s the path to profitability. Growth is mostly a function of delivering differentiated value to customers; hence the need for amazing UX. And profitability is mostly a function of unit economics and operational rigor.
In the AI era, the path of both runs through some new, unexpected parts of the world, including compute infrastructure.
UX in AI is Sensitive to a Wider Range of New Inputs
A great user experience in AI apps requires a degree of control over a wider range of concerns than is the case in ordinary SaaS. I don’t really care or even know much about the actual hardware that a SaaS operates on. That principled indifference is part of the value of cloud but it’s badly misaligned with engineering reality in AI. But that posture of unknowing doesn’t really work for GenAI.
Inference is less intensive than training, but even inference is a non-trivial compute load and owing to several factors it requires a new degree of control; those factors include immaturity of inference stacks; frothiness of GPU products; variability of GPU availability; long-tail workloads appear to dominate; it’s not (yet, or ever?) as simple as just generating the next token…; some inherent challenges around LLM inference, including the need to fully manage a “local LLM” in preference to using an LLM inference service from another vendor.
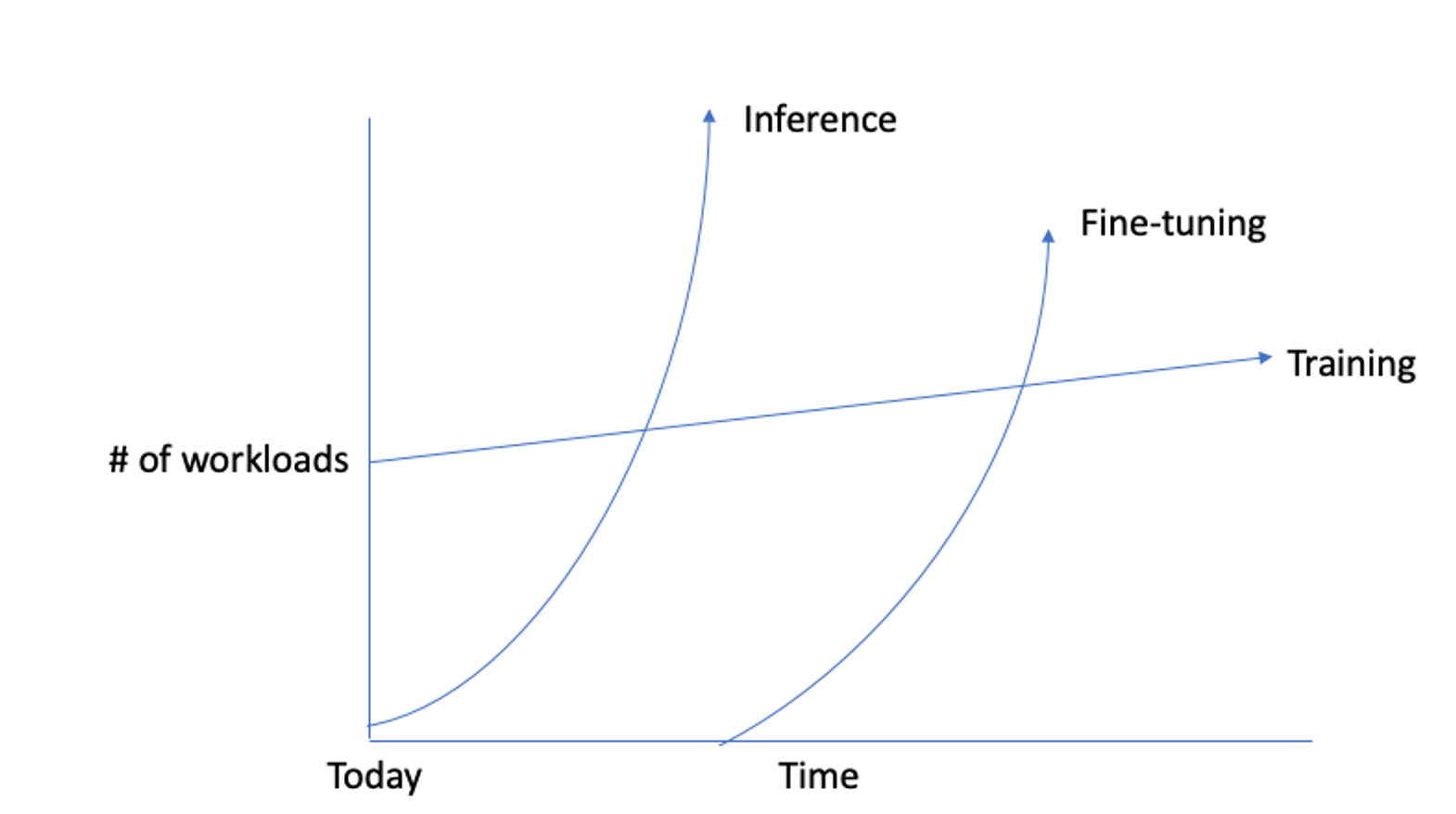
Source: A deep dive into the AI workload super cycle
These and other factors pushed us toward SKATHE from the perspective of delivering the very best UX we can provide in Voicebox. Tail latency in 95th to 99th percentiles dropped recently in Voicebox by about 60% because of some changes Engineering made that would be impossible with an LLM inference service, which will never give us the same degree of control as we have operating SKATHE directly.
So amazing UX in Voicebox requires full-stack control at the infrastructure layer. Not so much power or connectivity, but we suddenly care a lot more about things like DPUs, TDPs, residual streams ,and logit probes than we ever did before.
The Cost of Capital in GPUs is the Factor
World-class unit economics also requires full-stack control, too. Happily this convergence only required placing a few really big bets, including Voicebox itself, Karaoke, the Voicebox appliance, and SKATHE.
What do I mean about unit economics here? Well, let’s put it this way: if you’re renting GPU time, you aren’t going to have world-class unit economics except in some very rare situations. If you’re going to make money with GenAI, you have to own GPUs. Period. It’s just that simple.
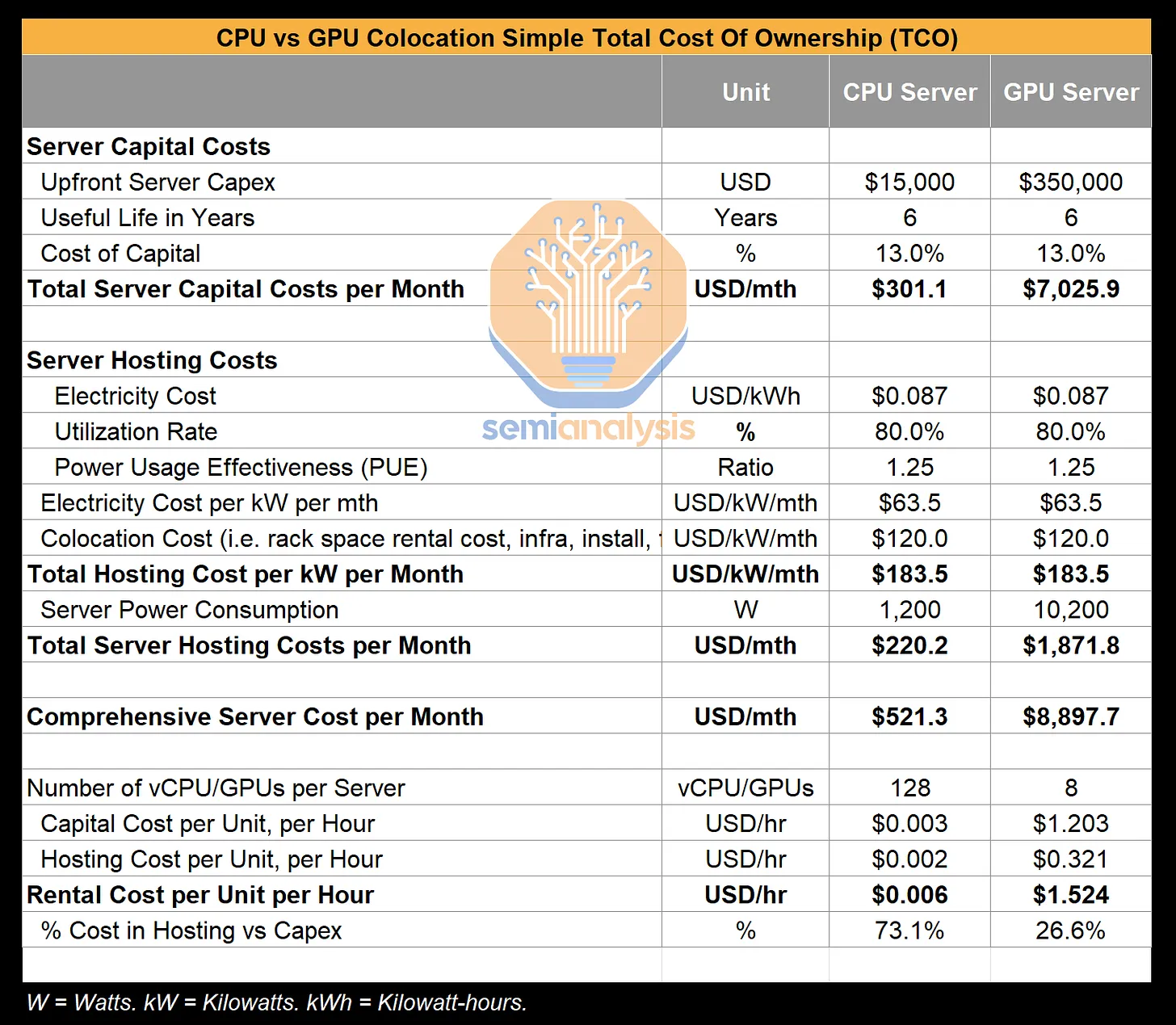
Source: GPU Cloud Economics Explained – The Hidden Truth
Now maybe that will change as prices and supply normalize, though it’s not at all clear what that would look like or when it will happen.
Startups are notoriously spendy with capital, often to the point of pride about burn rates. Which is historically anomalous. But in the GenAI era the dominant factor of capital needs is the cost of capital for GPU acquisition. And if you’re paying more than the cost of capital to lease them—and of course you are!—then you’re already losing, no matter what the adoption growth rate looks like.
I talked about engineering realities, but full-stack control extends to GPU ownership around UX, too. It’s pretty easy to spot which startups are using OpenAI to process GPU load based on how the startup charges for its product and how much it charges for it.
When the key driver of cost is rented over vanishingly small terms, you not only end up with far less flexibility to respond to the market and customer demand around pricing and usage patterns, but also that inflexibility extends to how many degrees of freedom you have commercially when selling into the enterprise market and aligning vendor needs with procurement’s demands.
One practical outcome to all this for Stardog Voicebox customers is a simple, all-you-can-ask model. Voicebox costs in a typical enterprise setting about $40 per user per month for unlimited usage. No weird talk of per-token fees or haggling around input versus output tokens, etc.
AI is Disintermediating the Hyperscalers
Full-stack control is key to nearly everything that matters in GenAI. But the larger context still matters, too. Recall that in the lead up to OpenAI starting the GenAI era, the dominant narrative in tech was public and private market valuation crashes in the face of growing buy-side revolt around spiraling cloud costs. Of course GenAI has put those concerns to the side temporarily because GPUs are mostly bought by a few big AI companies and the hyperscalers. But those underlying secular concerns around cloud costs aren’t going away and will reassert themselves.
In fact it’s easy to see this already in the rise of pure-play GPU cloud startups like Lambda Labs and CoreWeave, among many others. To say nothing of Nvidia’s cloud offering which is ambitious and disruptive.
I expect a nasty backlash against the hyperscalers as the secular cost trend reappears and coincides with the general realization that GPU costs in the cloud are unmoored from underlying reality.
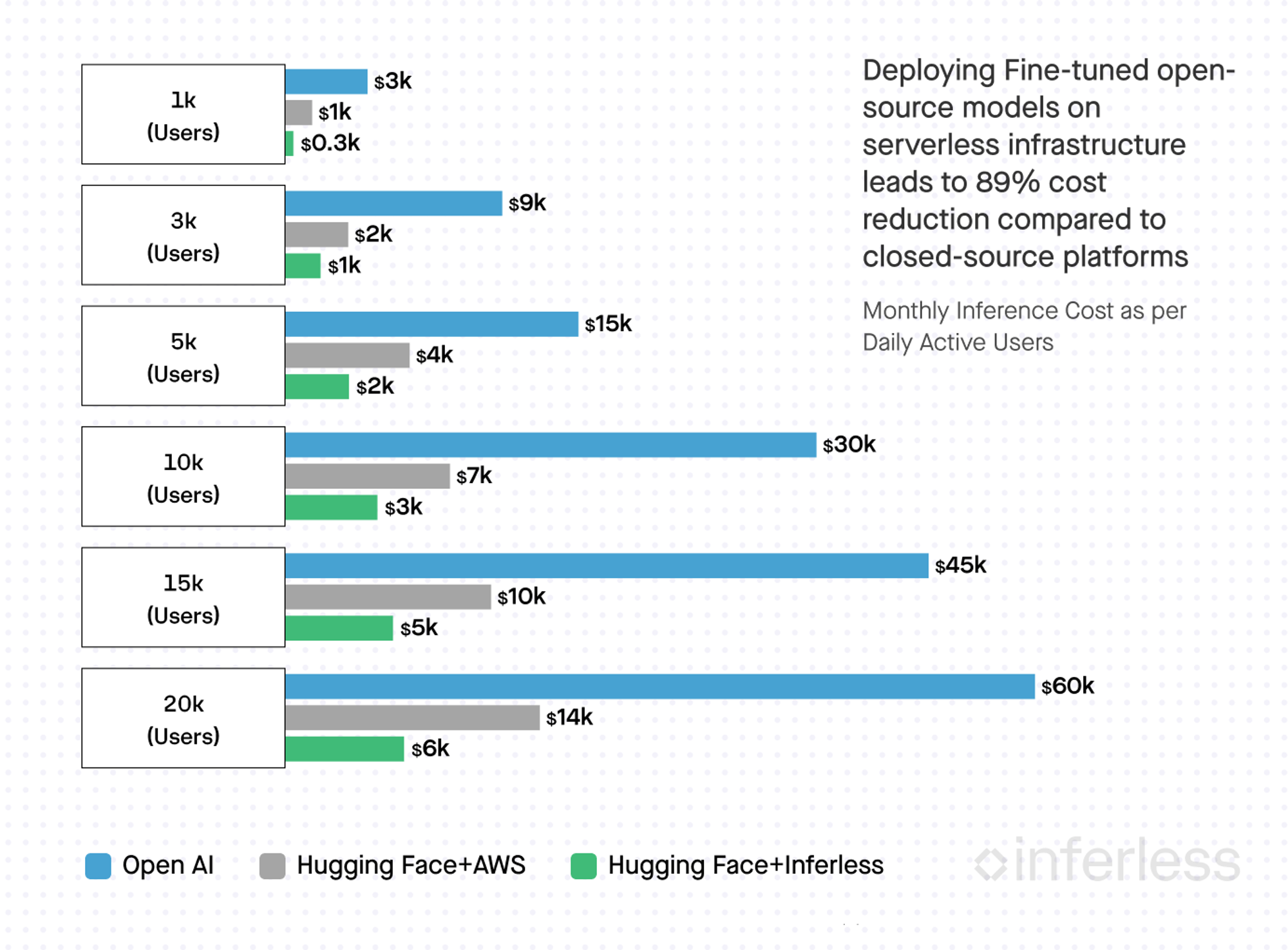
Source: Unraveling GPU Inference Costs for Fine-tuned Open-source Models V/S Closed Platforms
I have no idea how any of that plays out, in the end, but I expect it to be joined by the growing anti-cloud backlash, not so much about cost but about the reassertion of the fact that hardware matters and never more than in the GenAI era.
Stardog Voicebox is Positioned to Win
The biggest impact from GenAI will come from serving high-stakes use cases in regulated industries, exactly the most anti-cloud tranche of the market. Serving that customer base and serving it a world-class user experience is why we’ve built Stardog Karaoke and SKATHE. Both of which are different ways to bring the cloud to the data in cases where the data isn’t going to the cloud.
Stardog Voicebox is a fast, accurate AI Data Assistant that’s 100% hallucination-free, guaranteed, and it can run adjacent to the most sensitive data on the planet.
