
Three Evaluation & Design Questions of GenAI: UX, Data, Analytics

Get the latest in your inbox
Get the latest in your inbox
The design of a GenAI app—no more nor less than any other kind—is, on the sell side, a set answers to key questions; but so too is the evaluation of a GenAI app on the buy side.
To date, evaluation of GenAI has been haphazard and ad hoc. Ask a few questions, spot check the answers. Not very scientific and surely not very satisfying.
In what follows I organize the design-evaluative questions into three orthogonal groups—
A GenAI app is…an app, which means it has a UI and, thus, a UX. What are the primary design considerations for the UX of a GenAI app? Well there are a few types, including:
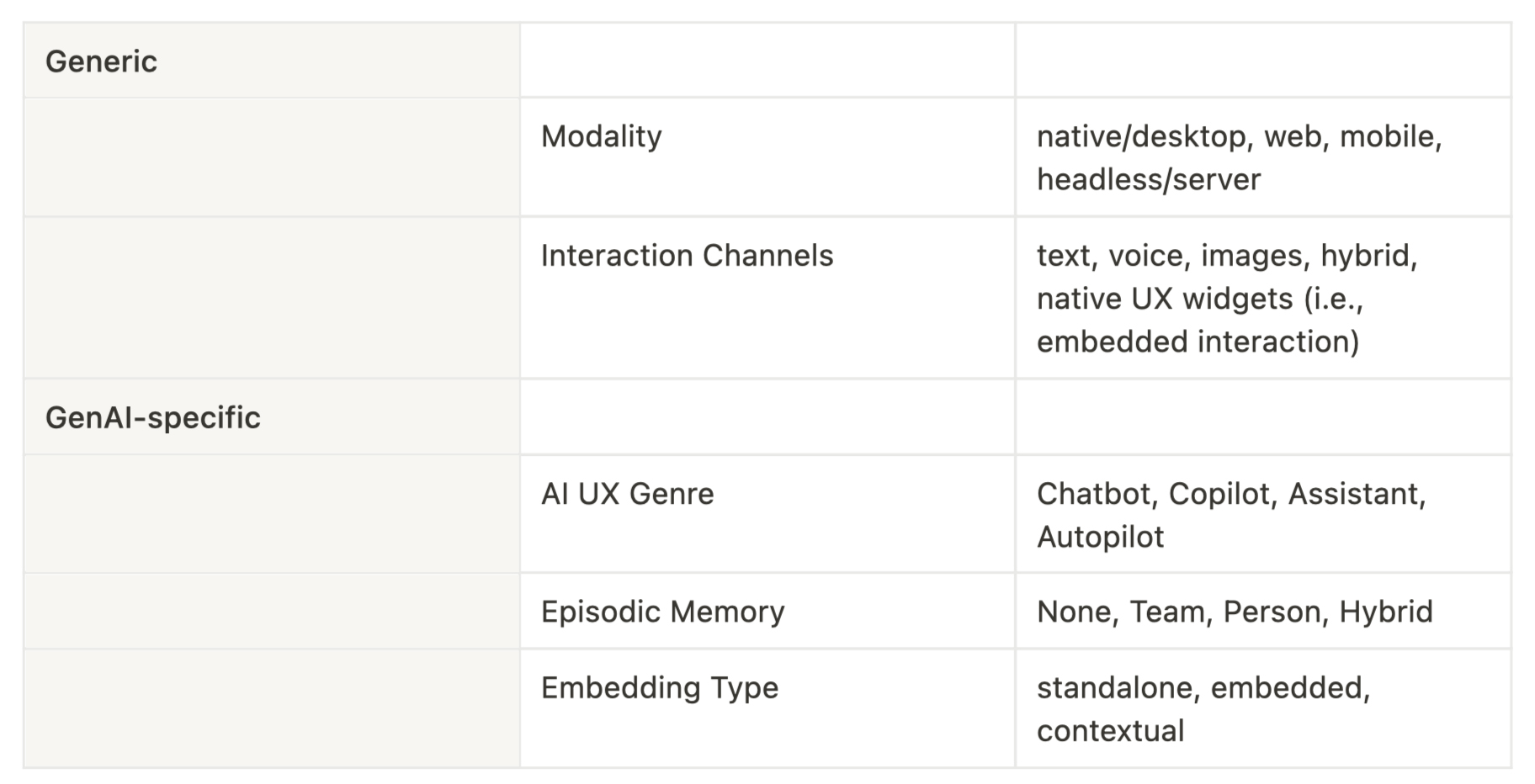
Most of these are self-explanatory but I’ll say a few words about Episodic Memory.
Of course pre-GenAI apps may have the notion of a user’s interaction history. But given that it wasn’t until LLM-powered apps that we felt like it made sense to say an app “understood human intent”, at all, then it now makes sense for apps to have the notion of an episodic memory, that is, an ongoing diachronic context of interaction (that is, a partially ordered set of human intent detections) with the user.
This is especially relevant for AI assistants like Stardog Voicebox that try to aid users to accomplish their goals over time, including understanding long-running conversations, linguistic references, and multiplexing different contexts that cluster around various overlapping (and non-overlapping) projects and goals.
GenAI apps “work on” or address data, but not all data is addressed equally or at all. So a key consideration to understand what differentiates one GenAI app from another—or, equally, how to design and build GenAI apps that create value for users—is to be clear about what data is addressed and how.
TLDR — Is the GenAI app addressing data that’s proprietary? Open? Both or neither but restricted by some other means?
Not to be all legalistic, but a central consideration is whether or how a GenAI app is connected—or, better, restricted—to some particular Walled Garden of data. For example, Einstein for SalesForce is pretty amazing but it only works for data hosted, i.e., physically resides, in the SalesForce universe, by design. Want to use Einstein to ask questions about data in SAP or Oracle or Azure? Too bad, you’re out of luck. And of course I’m not picking on Einstein since it’s just an example of a general point.
Data location matters more in the GenAI era, not less. Where data lives is often as important as what data means to the business.
In other words, a Walled Garden data ecosystem doesn’t get more (or, likely, less) Walled because GenAI has been added to it. Whether or not a Walled Garden or an open ecosystem is important to you, only you can say, but Stardog Voicebox intends to address all enterprise data and that means we play the game as an open ecosystem based on public standards. That’s one reason for our embrace of a robust partnership with Databricks since they—unlike many others, Palantir mostly notably, perhaps—disdain the Walled Garden approach in favor of an open source ecosystem based, indirectly, on public standards and, directly, on de facto standards like Apache Spark.
What is the type of data that yr GenAI addresses? Is it text, ie, documents? Database records? Metadata? Imagery? Audio? Music? Videos? Geospatial? APIs? Code? Increasingly we will begin to see novel combinations of these in hybrid GenAI apps that are less focused on a data type specifically and more focused on whatever data types are necessary to accomplish valuable or tedious (or both) jobs-to-be-done.
This will influence or determine nearly everything about the app, from its UX to its core algorithms and data structures to the choice of agent frameworks, foundational models, embedding models, etc.
Separate from the other considerations in this section, a GenAI app must also answer the question about where the data it operates upon lives. Is that data native to the app or does it live locally or in the private cloud or public cloud or etc? Further, what sort of data silo or siloes does the data natively call home? A data warehouse, lakehouse, time-series database, document database, GIS, SharePoint, Dropbox, Box, S3, API, data catalog, etc.
The importance of Knowledge Graph cannot be overstated here since it answers two kinds of deep implementation question for GenAI apps:
Enterprise Knowledge Graph-backed GenAI apps do #1 and #2 better than other kinds of data-layer infrastructure, not least since they can simultaneously power the (relatively) easy, low- and medium-stakes apps where RAG is appropriate (and some form of “Graph RAG” is best) as well as the (absolutely) harder, high-stakes apps where all forms of RAG are inappropriate and Semantic Parsing is best.
Finally, let’s conclude by first reviewing; so far, we’ve
“Questions…answered” could just as easily be called “what sort of analytic operations upon the data is supported?” What do I mean by kinds of questions? Well here are some of the kinds of question I have in mind—
I discuss these and other types of analytic question that Voicebox is committed to and already answers in The Stardog Voicebox Vision in Full.
Not only can we differentiate one GenAI app from another by considering their UX and their addressable data, but also by thinking carefully about what sorts of question they can answer. For example, Github Copilot either can or eventually will be able to answer questions about SDLC like “is this pull request valid with respect to our coding standards?” and “what code is licensed with AGPL or another ‘viral’ license type?”
And that’s a quite different kind of experience for the user than the six questions types that Voicebox is concerned with, described above, since Voicebox is an AI data assistant and not a software engineering copilot—and this would be helpful and true even if, counter-factually, they had the exact same UX.
Stardog Voicebox ROI comes from eliminating a significant part of the tedium of knowledge work—the “dead time”—by fully democratizing access to insight.
Enable anyone to ask any question of any data and get accurate, timely, and hallucination-free answers—immediately. Check out the details.
How to Overcome a Major Enterprise Liability and Unleash Massive Potential
Download for free