Defining Data Mesh
Rather than dwell on the definitions (Gartner counts at least three) of data mesh, I’ll go with my lay version:
data mesh [dey-tuh- mesh]
A decentralized architecture capability to solve the data swamp problem, reduce data analytics cost, and speed actionable insights to better enable data-informed business decisions.
There, I said it without the buzzwords like “data democratization” or “paradigm shift.” Mea culpa for throwing in “actionable insight.” Let’s decompose what data mesh means for the real working class, our data engineers, architects, and scientists.
Why Use Data Mesh
Data swamps are losing their role as a centralized data platform
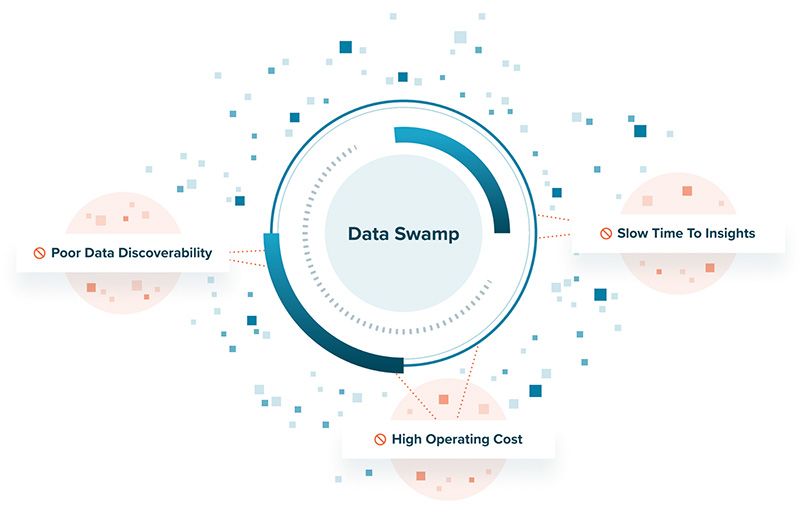
In the mid-1990s, data warehousing was bursting onto the data management scene. Fueled by the hype of the fabled “beer and diapers” story, businesses were pouring tens of millions of dollars to build huge data monoliths to handle the consumption, storage, transformation, and output of data in one central system to answer business questions that required complex data analytics such as “who are the high-value customers most likely to buy X?”
The thesis of data warehousing worked like a charm at that time. However, as the appetite for data analytics increased, so did the need for more data to be ingested. The complexity and pace of data pipelines soared (as did the nickname “data wranglers”). I began to see the cracks forming in the data warehouse theory and delved into its growing failure to get value from analytical data in my master’s research.
As social media and the iPhone became the norm, many turned to a second generation of data analytics architecture called data lakes. While traditional data warehouses used an Extract-Transform-Load (ETL) process to ingest data, data lakes instead rely on an Extract-Load-Transform (ELT) process that puts data into cheap BLOB storage. This eliminated the big shortcomings of data warehouses but spurred the “Let’s just collect everything” theology of data swamps.
Further learning: Data Lake Acceleration
Is Data Mesh Right For Your Organization?
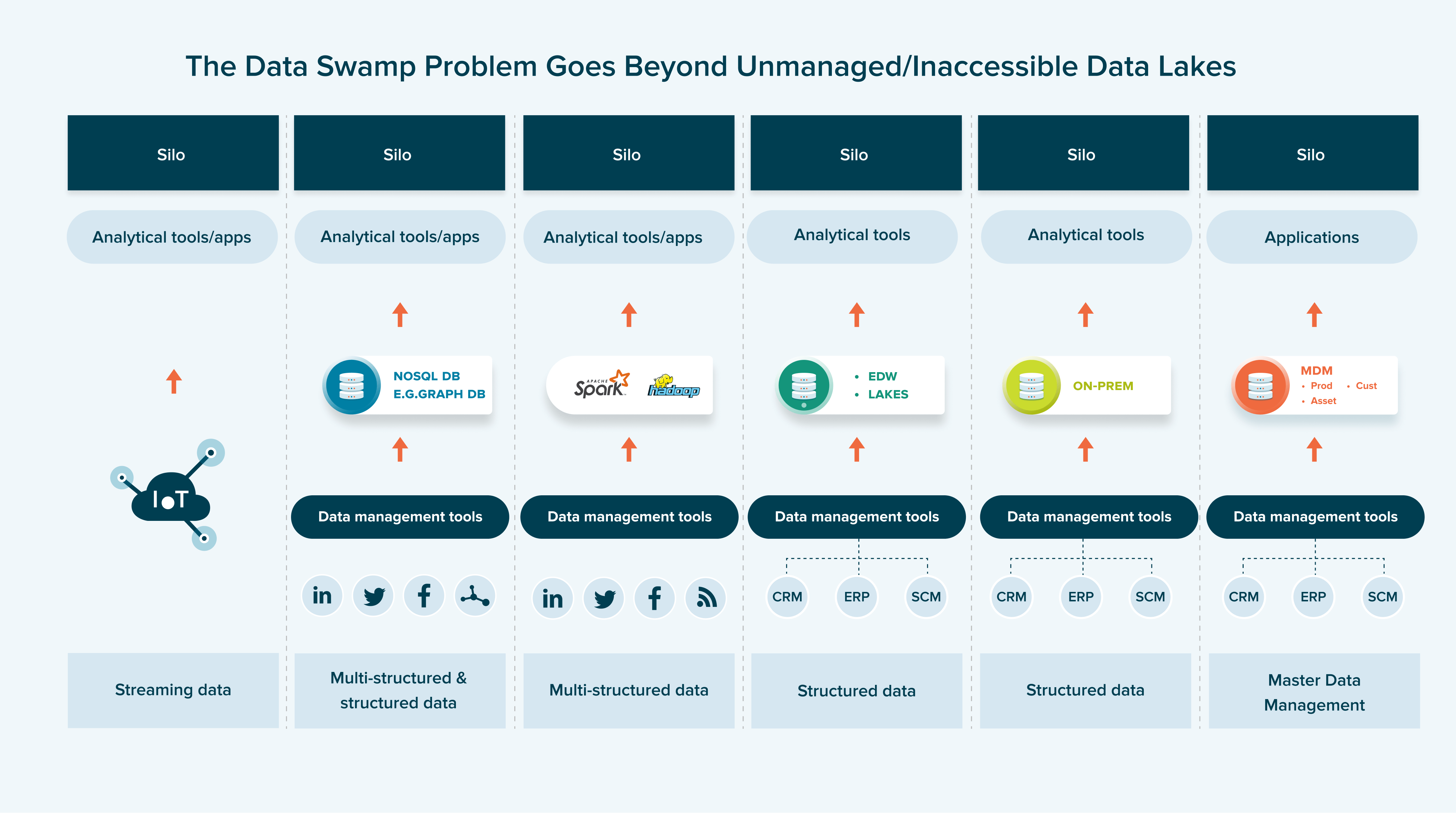
Fast forward to today. Only 32% of companies are realizing tangible and measurable value from data (“trapped value”), according to a study by Accenture. The roaring demand for “discovery or iterative style analytics” (where consumers don’t really know the questions or data they need) is raising access to data to a whole new level with new/expanding data sources (or “wide data”) across multi- and hybrid cloud environments, thrusting massive friction onto traditional data lakes and warehouses.
Nowhere is this pain more visible than among data and analytics teams where:
- Data scientists consider themselves 40% a vacuum, 40% a janitor, and 20% a fortune-teller Toward Data Science
- 78% of data engineers wished that their job came with a therapist to help with work-related stress Survey commissioned by data.world and DataKitchen
- 65% of large, data-intensive firms have a CDO or CAO, but the average tenure is just 2.5 years Harvard Business Review
Data Mesh Principles
A data mesh aims to create an architectural foundation for getting value from analytical data and historical facts at scale – scale being applied to the constant change of data landscape, proliferation of data and analytics demand, diversity of transformation and processing that use cases require, and speed of response to change.
To achieve this objective, most experts agree that the thesis of data mesh is based on four precepts:
- Decentralize the ownership of analytical data to business domains closest to the source of the data or its main consumers. This removes the need for authoritarian bottlenecks of data teams, warehouses, and lake architecture, scaling out data access, consumers, and use cases.
- Make access and use of data products easy and self-service. This removes the friction of data sharing, from source to consumption, streamlining the experience of data users to discover, access, and use data products for their use cases.
- Federate the governance of data based on an appropriate operating model that balances decision-making and accountability. This precept builds on domain-oriented ownership and data as a product.
- Manage data as a product and a development methodology. Consider how data teams can create value in their organizations. Think features like discoverability trustworthiness, reusability, and value. This facilitates, regardless of silos, the sharing of data with users.
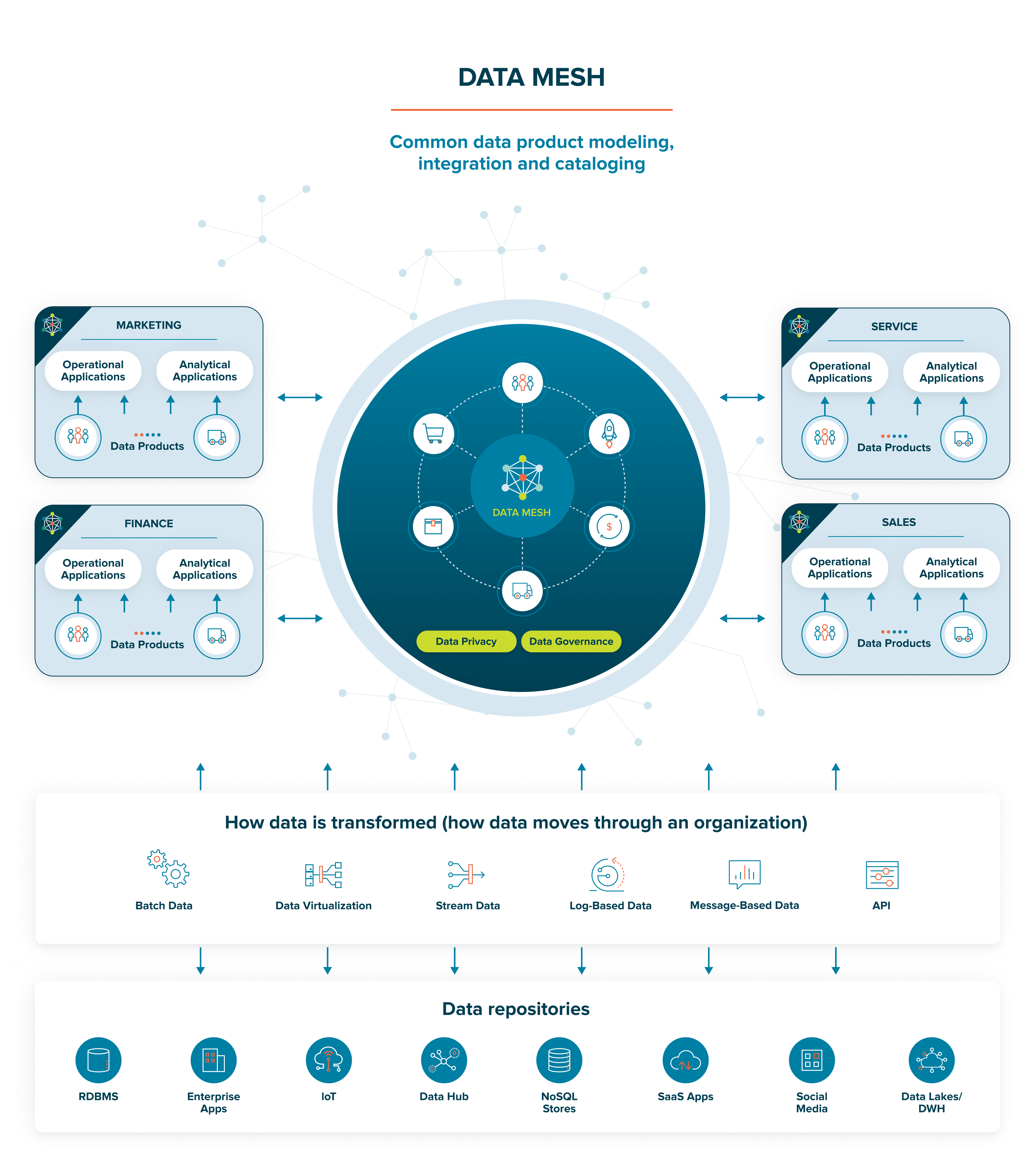
Data mesh inverts the traditional data warehouse/lake ideology by transforming data gatekeepers into data liberators to give every “data citizen” (not just the data scientist, engineer, or analyst) easy access and the ability to work with data comfortably, regardless of their technical know-how, to reduce the cost of data analytics and speed time to insight.
However, the rise of data mesh does not mean the fall of data lakes; rather, they are complementary architectures. A data lake is a good solution for storing vast amounts of data in a centralized location. And data mesh is the best solution for fast data retrieval, integration, and analytics. In a nutshell, think of a data mesh as connective tissue to data lakes and/or other sources.
Introduced by Thoughtworks, data mesh is “a shift in modern distributed architecture that applies platform thinking to create self-serve data infrastructure, treating data as the product.” It is a data and analytics platform where data can remain within different databases, rather than being consolidated into a single data lake.
Like a data fabric architecture, a data mesh architecture comprises four layers. To provide useful information to data and analytics professionals, I’ll break the data mesh rule by also talking about specific technologies and representative vendors.
- Storage: This is where much of your data lives once it’s ingested and organized from OLTP databases, data lakes, data warehouses, graph databases, and various files. The composite of analytic systems equates to your central data platform. Representative vendors are Snowflake, Databricks, and Google.
- Analytics: This layer is responsible for delivering the process data to the end-users, including business intelligence analysts, data scientists, and business stakeholders who consume the data with the help of reports and analytic models. Representative vendors are Tableau, PowerBI, and SAS.
- Governance: This is where processes, roles, policies, standards, and metrics ensure the effective and efficient use of your data. Data catalogs define who can take what action, upon what data, in what situations, and using what methods. Representative vendors are Alation, Collibra, and Promethium.
- Semantic: This is the virtual “connective tissue” of the data mesh. Knowledge graphs (not to be confused with graph databases) connect any data into a canonical data model, harmonize it into real-world business meaning and relationships, and enable self-service data exploration and discovery.
VentureBeat says a data mesh architecture “connects various data sources (including data lakes) into a coherent infrastructure, where all data is accessible if you have the right authority to access it.” This doesn’t mean there is one big, hairy data warehouse or lake (see data swamp problem) — the laws of physics and the demand for analytics mean that large, disparate data sets can’t just be joined together over huge distances with decent performance. Not to mention the costs of moving, transforming, and maintaining the data (and ETL | ELT).
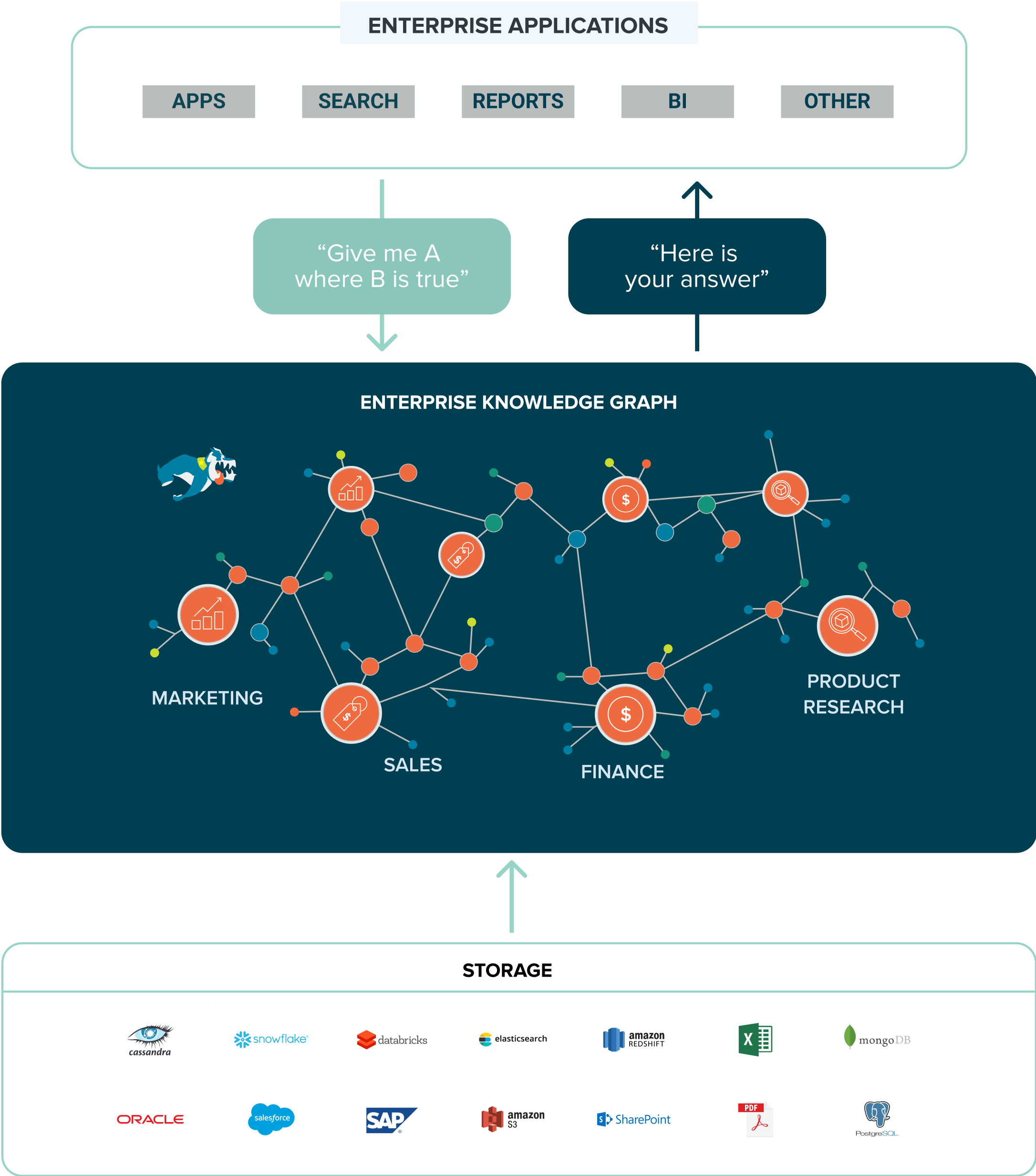
Enter the semantic layer. A semantic layer represents a network of real-world entities— i.e., objects, events, situations, or concepts — and illustrates the relationships to answer complex cross-domain questions that can be shared and re-used based on fine-grained data access policies and business rules. It is comprised of three layers (and a knowledge catalog that interfaces with governance tools):
- Business meaning: This is a business representation of data. It enables users to quickly discover and access data using standard search terms — like customer, recent purchase, and prospect. Data can be shared and reused through a common, standards-based vocabulary.
- Data storytelling (inferencing): Creates new relationships by interpreting your source data against your data model. By expressing all explicit and inferred relationships and connections between your data sources, you create a richer, more accurate view of your data and cut down on data preparation.
- Virtualization: Provides an alternative to costly, slow ETL integration and permanent transformation of source data. Virtual graphs allow you to leave data where it is and bring it together at query time to reflect the latest changes, which scales analytics use cases and users at minimal cost and reduces data latency.
The big payoff of a semantic layer is in providing a better way to enable self-service, federated queries, enabling you to build and deploy analytics data products quickly and efficiently.
Further learning: How Knowledge Graphs Work
Data Mesh Benefits
Generally, organizations handling and analyzing a large amount of data sources should seriously consider evolving to a data mesh architecture. Other signals include a high number of data domains and functions teams that demand data products (especially advanced analytics such as predictive and simulation modeling), frequent data pipeline bottlenecks, and prioritizing data governance.
Stardog commissioned Forrester Consulting to interview four decision-makers with experience implementing Stardog. For this commissioned study, Forrester aggregated the interviewees’ experiences and combined the results into a single composite organization. The key findings were that the composite organization using the Stardog Enterprise Knowledge Graph platform realized the following over three years:
- 320 percent return on investments
- $4.7 million total data scientist productivity improvement
- $2.6 million in infrastructure savings from avoided copying and moving data
- $2.4 million in incremental profit from enhanced quantity, quality, and speed of insights
