
5 Steps to Building a Data Fabric

Get the latest in your inbox
Get the latest in your inbox
We hear from many of our customers that they’re interested in building a data fabric, but they’re not sure how to get started. Luckily, with a knowledge graph-based approach, you can start small and grow your data fabric over time. In this post, we’ll share an easy, approachable 5-step process for getting started with a data fabric.
Before getting into our data fabric implementation framework, however, let’s revisit the reasons why you would want to build a data fabric. This will root us in the outcomes we’re hoping to achieve.
Conventional data integration, which involves ETL jobs to move data around and consolidate it within various data warehouses and data lakes, is broken. This is because, today, data generation occurs at such break-neck speeds that traditional tools can’t keep up. The location of data, the shape of it, and its complexity is constantly changing.
What are the consequences of this?

It makes your data machine-understandable for AI/ML. Machine understandability is key for machine learning, AI, driving insights, making predictions, and other things that require seeing the connections between data. With a knowledge graph, you don’t have to go through the code to translate that information into the models. Instead, by abstracting out the context and meaning and putting those into the model itself, different data structures can all appear the same for these types of AI and ML activities.
It leverages existing data infrastructure. These models are able to leverage existing systems already in place and reuse existing components, like ETL systems, data catalogs, repositories of metadata, data governance programs, etc. By leveraging these systems, you can get to the end goal faster and more cheaply.
It’s more flexible than alternatives. A core advantage of semantic technology is that because the data model sits separate from the data itself, it’s like having a lens looking at the data, so you can have multiple of them. Different groups can see things different ways without having to load the data or reshape it multiple times for different problems.
It provides better, explainable insights. Being able to represent data in a consistent, machine-understandable fashion from various different applications lets you discover connections in the data that you did not previously know existed.
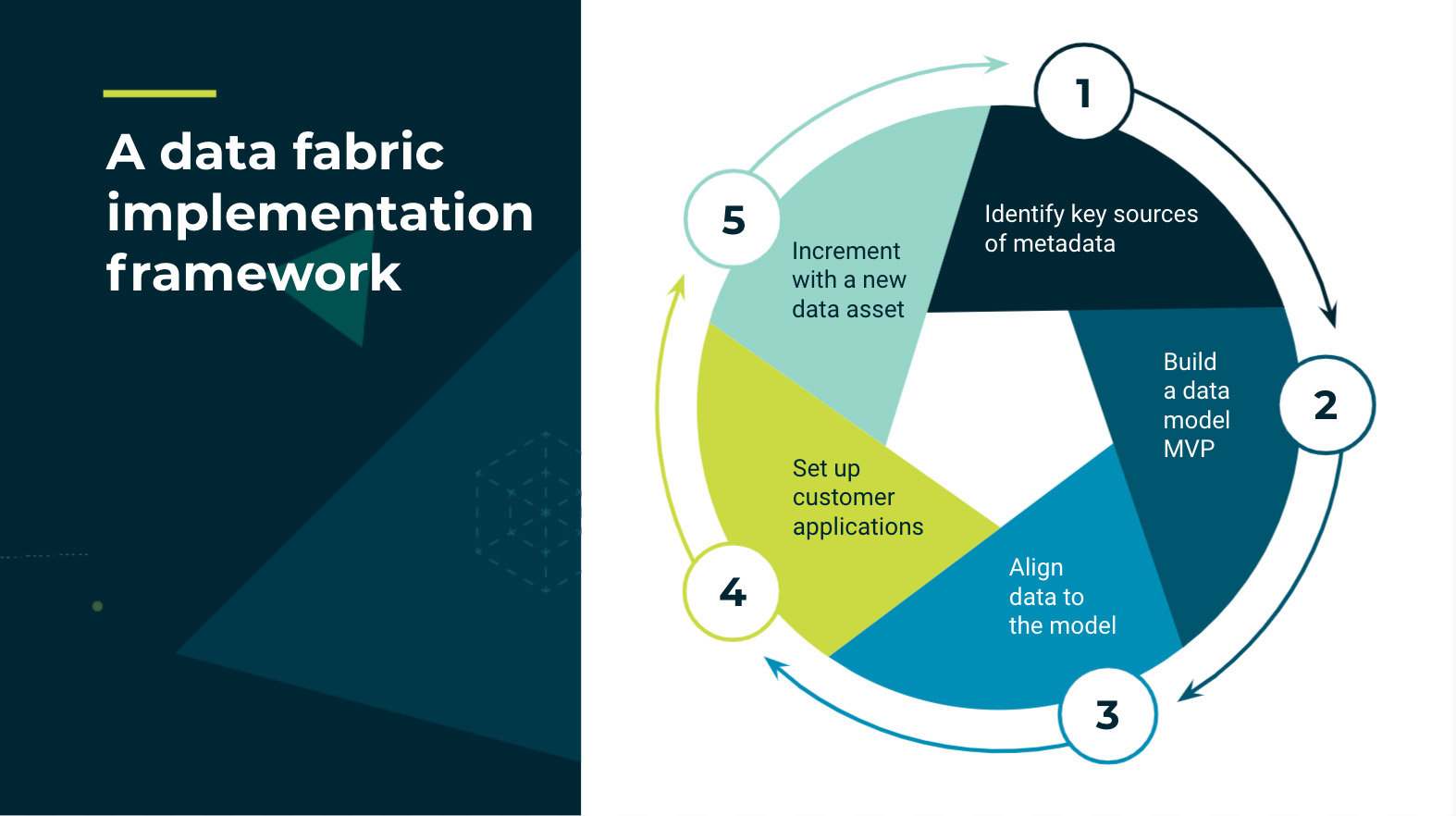
Now that we’ve established why you would want to build a data fabric, let’s get into the steps of how you actually set one up. We’re going to walk you through a 5-step framework that allows you to quickly show value and iterate as you go through the process. For anybody familiar with agile methodology, this will look familiar. One of the key characteristics of semantic technology is that the data model is reusable, and this type of MVP approach is critical to the success of your data fabric project.
Here are the steps to building a data fabric:

The first step is to identify key sources of metadata, but really there also is a step zero ahead of this, and that is to understand the business question you want to answer. Be sure that when you start this project, you know, “what am I trying to answer?” This is not a “build it and they will come” type of project, but rather you want to go into this with the idea that I am solving a real problem for someone. Problems like:
The critical piece is to understand the question, and then identify the data sources you need to answer the question. It’s important to not let perfect be the enemy of good here and not spend too much time trying to find the “perfect” use case for the “perfect” set of questions. One of the key benefits of a data fabric is that it is iterative.
To accelerate this step, you should have subject matter experts helping you define the business questions you need answers to, as well as explaining where the data lives. You also can reuse work done by your data governance programs or data catalog. Also be sure to request access to these critical data sources at this stage; this will make connecting to these systems later on much easier.

The second step is to build a data model MVP. This is a very important step, as one of the issues we see with data fabric projects is scope creep where a data model becomes too big and implementers lose sight of the core questions they’re trying to answer. It’s very important to stay focused on what you need to answer the question.
A good rule of thumb is to spend no more than 2 weeks on this and look at no more than 5-10 different entities. If you look at your questions, and they require more than 5-10 entities for you to understand and model, it is probably too big of a question, and you should go back to step one and refine your scope.
There are several things you can do to help ensure success at this stage. There are many publicly available data models, like FIBO, Brick, and others that can be found on sites like schema.org that you can leverage. With these reusable data models, you’re not starting with a blank sheet of paper; you’re starting from work that other people have done. If your organization has a data catalog, this is another resource you can leverage. A lot of data catalog initiatives have already defined key business terms and determined how these terms are related to one another.
Stardog helps with building a data model MVP by allowing you to connect to existing data catalogs so you have a starting point to create an initial data model. We’ve also created a visual environment for you to build these data models.
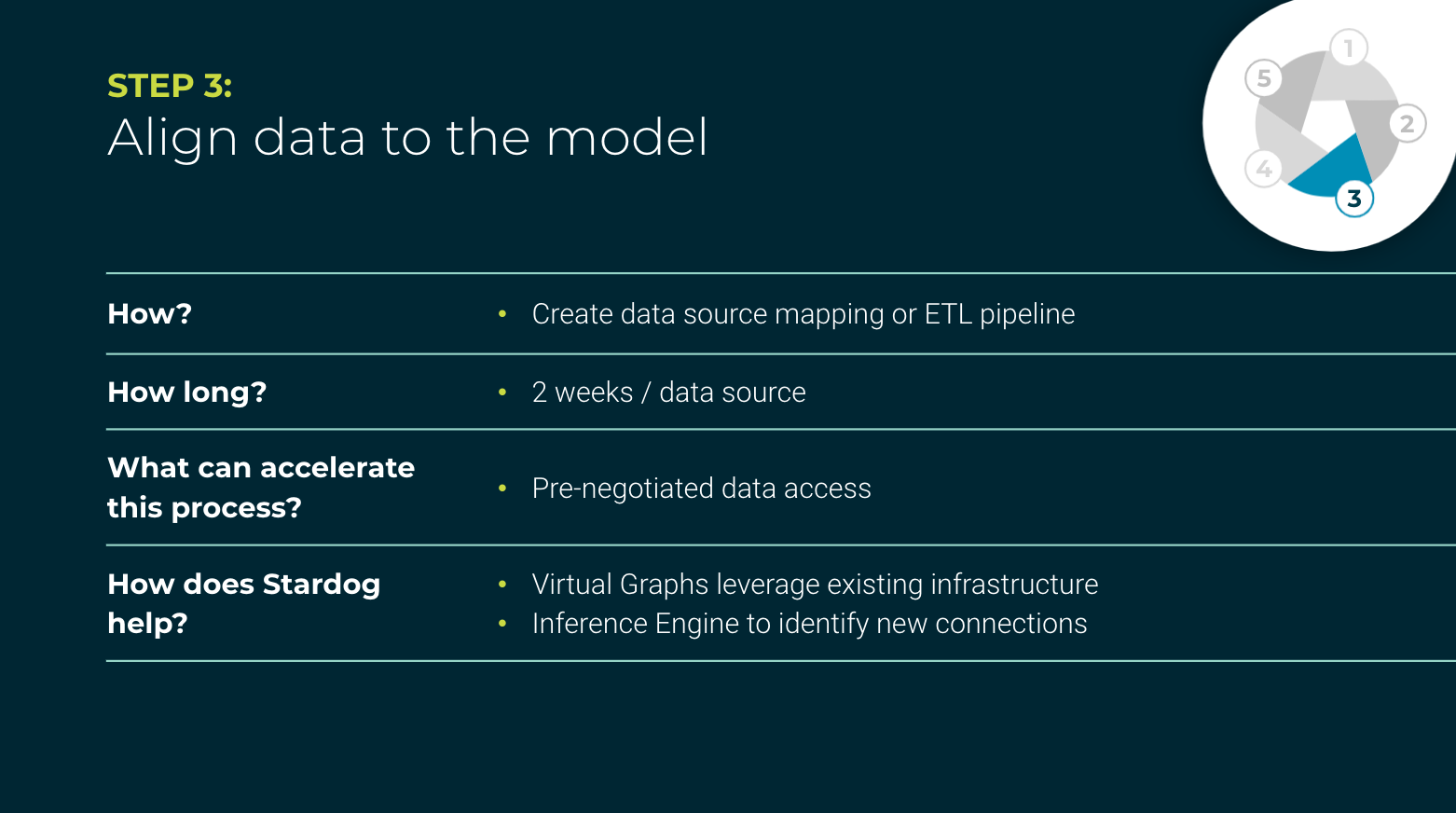
The third step is the core of the whole data fabric project. It is the heart of the data fabric. This is where you connect the data to the model.
This is where you tie the metadata, the model, and the data itself to the downstream systems. At this point, data virtualization really comes into play. The greatest advantage of virtualizing your data is that it accelerates your time to value. You don’t have to worry about extracting out the data, making sure it’s in a format you can use, reformatting the data, loading it, and waiting for the jobs to finish. Instead, you can look at the data in place and leverage the investments you’ve already made in existing data repositories.
Some systems are not well suited to being virtualized. For example, data sources where performance is the top concern. There also might be security concerns, for example with external systems. That’s why the combination of virtualization and materialization capability is so important.
If you’ll remember, back in step one, we mentioned you needed to pre-negotiate access to the data sources required to answer your business questions. We’ve seen projects get bogged down at this step if they don’t have that access already in place so be sure you take care of that ahead of time.
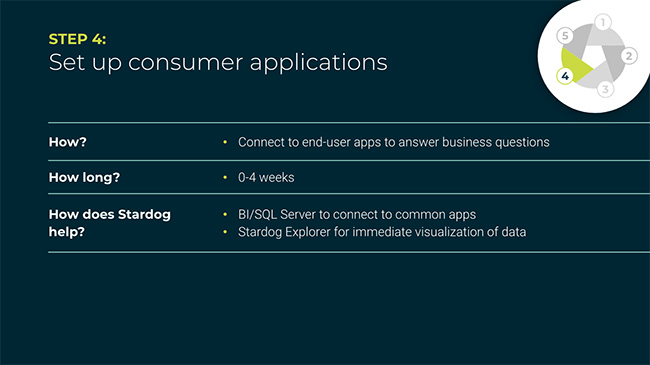
The fourth step is all around the consumption of the data. It’s critical that people are able to answer their business questions as part of the data fabric.
We’ve seen our customers do a variety of different integration approaches, for example by integrating into apps they already have in place, something like SharePoint. We also bring to the table SQL endpoints, which lets you leverage tools, like PowerBI, Cognos, or MicroStrategy. This lets end users see the data in these various systems without having to learn how to interact with a knowledge graph or having to learn a query language.
The other way we speed up consumption of the data is via Stardog Explorer, our graph visualization tool. This is a way for non-technical users to explore and look at data within the graph and investigate connections without having to stand up a separate application.

The final step is to repeat the process. The key differentiator of a data fabric is that it can grow over time. This means repeating the above process — going on to the next question or a related question. Those questions could reuse some of the same items you’ve already modeled or perhaps they require connecting a new data source. Either way is easy with a data fabric using this framework.
By iterating through this process over and over again, you’ll build out a full picture of your organization that can be represented in a data fabric. All of the work you’ve done previously can be leveraged and built upon so not every project needs to be begun anew.
Data fabric is ushering in a new era of enterprise IT. Data fabric offers a different way forward and one that’s a significant departure from the world of rows and columns in a table that we’re used to. But what outcomes does a data fabric really promise? Read on to learn more.
The truth is, data silos are inevitable! They exist for excellent reasons, allowing for local control and governance when important to a particular part of your business. Instead of replacing legacy technologies, a data fabric works alongside existing investments and improves their utility.
How to Overcome a Major Enterprise Liability and Unleash Massive Potential
Download for free