Knowledge workers need democratized data access to make better, faster decisions to boost productivity. Literally no one disputes this, not even a little bit. The ironclad law of AI and data is unbreakable—without good data, you get bad AI—for agents no less than for people.
So let’s talk about the ways an enterprise knowledge graph serves the data needs of LLM-based agents—
- Making real-time decisions using live operational data, which requires a knowledge graph platform that has real-time data integration
- Gathering accurate data to prevent or diminish LLM hallucinations via groundings
- Supplementing an LLM’s general knowledge (what everyone knows in principle) with enterprise-specific policies and knowledge (what only the enterprise knows)
- Discovering data dynamically through integrated enterprise knowledge catalog (a catalog-of-catalogs as a knowledge graph)
This is relevant to Stardog because it combines the agent-centric benefits of a semantic layer, data fabric, and knowledge catalog in a single, unified knowledge graph platform.
An Agent Needs Sane, Timely, Connected Data
Agents don’t need these specific technologies. But agents do need the core capability that semantic layers, data fabrics, and catalogs deliver—real-time access to consistent, timely, accurate, and contextualized data (and metadata).
The Agentic View of the Enterprise Data Landscape
| Rubric | Source | |
|---|---|---|
| Background knowledge | What everyone can or should know about the world. | LLMs trained on text |
| Domain knowledge | What can’t change and what only the enterprise knows including how it does business; sometimes called “categorical data”. | Ontologies |
| Transactional data | Proprietary facts about the business and its commercial, legal, & other relationships. | Databases and other data silos |
But surely, you’re thinking… surely, agents someday will just look at dashboards when they need to answer a question. Joking? Not joking! Agents can already do that, but they don’t. The truth of why they don’t is bitter: dashboards don’t hold the answers for agents any more than they do for people.
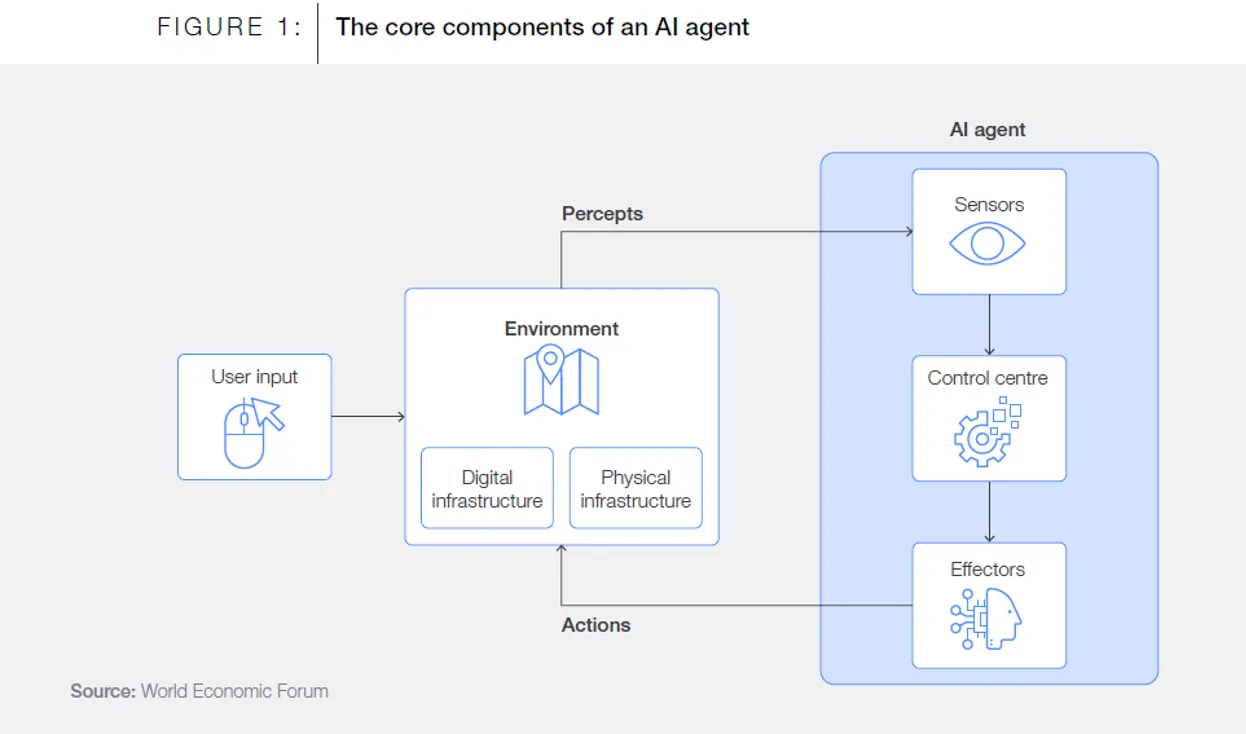
Agents Must Grok Changing & Static Business Rules
To enable semi-autonomous data access, agents need many tech capabilities; but I want to focus on an agent’s need to access formalized domain invariants in a format it can reliably understand. Put simply, agents need ontologies.
An ontology formally describes the fundamental rules and patterns that define a particular domain. “Formalized domain invariants” is a fancy way of saying “the things about the business that cannot change.” That’s what ontologies describe in a machine-understandable form.
LLMs are remarkable because they compress what everyone can know about the world, storing vast amounts of background knowledge in their weights and parameters. Hence LLMs give agents a programmatic way to access common knowledge, a breakthrough that drives most of an LLM’s value.
But as powerful as that is, it’s not enough, since the difference between two banks or two life science companies consists almost entirely in what they know that no one else knows. Agents need access to that knowledge, too, if they’re going to be faithful, true, and helpful partners to enhance human performance.
Demystifying Ontologies
LLM-powered agents are really good at understanding natural language, but they still make silly mistakes that throw them off course. Data is the remedy, and ontologies are the best container for the sorts of data just discussed. Ontologies serve (at least) two key purposes on this view:
- to centralize knowledge in one place—making it easier to access, maintain, and manage changes; to give agents a reliable framework for understanding and working with data across different situations; and
- to reduce uncertainty while improving output quality, particularly in preventing hallucinations.
These two purposes work together dynamically: by having a single source of truth for enterprise knowledge, agents can operate with greater confidence and precision, while the formal structure of ontologies provides the guardrails needed to keep agent outputs reliable, factual, and relevant. The result is more robust and trustworthy agents that can better serve enterprise needs. This approach is particularly valuable in regulated industries where accuracy and compliance are key.
NeuroSymbolic AI’s Data Model
So we’re talking about combining statistical and logical kinds of AI. That’s called NeuroSymbolic AI. That sort of AI is crucial as discussed for Agentic AI to work. Agents need a data model and we think ontologies and knowledge graphs are absolutely crucial. NeuroSymbolic AI combines the strengths of neural networks with symbolic reasoning and that requires a data model and data integration techniques that can represent both learned patterns (i.e., “we compressed the internet into one big file”) and explicit rules (i.e., “here at Big Pharma, we do business like X and Y in situations like A and B”).
This hybrid approach allows agents to leverage both the flexibility of LLMs and the precision of ontological knowledge. By grounding LLM outputs in well-defined schemas and ontologies, we can achieve more reliable and verifiable agent behaviors while maintaining the natural language capabilities that make LLMs so powerful.
This hybrid approach offers several advantages—
- By combining explicit ontological rules with neural capabilities, we can better validate and verify agent outputs.
- The integration helps prevent hallucinations by grounding agent responses in concrete enterprise knowledge.
- This fusion enables more sophisticated reasoning that leverages both learned patterns and formal business logic.
But what kind of “sophisticated reasoning” for agents can an ontology support? We’ve talked about multi-hope and needle-in-a-haystack in The Stardog Voicebox Vision.
Resilient Queries by Reasoning Through Schema Drift
Ontology reasoning includes two kinds of dynamic schema reasoning that make queries (and questions from people, too) less brittle: class-tree expansion and property-tree expansion.
Class-tree expansion allows agents to automatically include all subclasses when querying for a parent class. For example, when querying for “vehicles within 1 nautical mile of present lat-long,” class-tree expansion automatically includes all specializations of a base “vehicle” type, to include, for example, “cars”, “trucks”, “motorcycles”, and “illegal fishing vehicles” without explicitly naming each one—in fact, it would always include every kind of vehicle automatically across all schema changes. So as our understanding of the domain and the use cases evolves, to include future specializations, for example, “suspected spy trawler”, the initial query—”vehicles within 1 nautical mile of present lat-long”—is dynamic and always fresh. That is, a query that tracks vessels for shipments today, can track arms trafficking tomorrow thanks to ontology reasoning.
This dynamic reasoning capability makes queries more robust and flexible, reducing the chance of missing relevant data due to overly specific or brittle query patterns—and it’s completely independent of any particular use case or domain. I used here a running intelligence example but the capability works for finance (KYC, fraud, AML), manufacturing (supply chain exceptions or digital twin process faults), life sciences (batch parameters, drug-genome interactions), and so on.
Property-tree expansion allows agents to follow similar patterns when working with related relationships, properties, that is, types of connections between things. For example, when querying about “owns,” the system automatically includes more specific ownership relationships like “leases” or “licenses” without requiring explicit enumeration in the query. That means that people and agents can keep asking questions even as the organization and its data changes continually. This capability ensures comprehensive query results while maintaining semantic accuracy.
Queries (and questions of the type) “tell me something about all the things that are like this thing only more specific” are resilient to changes at and among the branches of the tree.
Knowledge Graph queries that include ontology reasoning are resilient in the face of schema drift and change since query-time reasoning means that queries automatically adapt to evolving data models without breaking. When business concepts change or new relationships emerge, the ontology can be updated while existing queries continue to work. This dynamic adaptation is crucial for maintaining reliable agent operations as enterprise knowledge evolves over time.
What about the Cost?
While I won’t detail it here, Stardog is pioneering the use of agents to build enterprise ontologies.
This approach not only reduces time to value and cost, but also exemplifies AI’s bootstrapping effect—where the LLM flywheel iteratively improves data quality, which in turn enhances the value of agents and AI. AI’s bootstrapping effect is often missing in public LinkedIn-level chatter about the impact of AI. Yes, Generative AI requires good enterprise data inputs and a lot of enterprise data isn’t very good; but it’s equally true that enterprises are busy improving the quality of their data with Generative AI. Both things are equally true. Turn the flywheel—iterate, iterate!

Thinking about data quality and AI as a virtuous cycle helps cut through the artificial either/or debate about whether enterprises are “ready” for AI. The reality is that AI adoption and data quality improvement are happening simultaneously, each accelerating the other. This pragmatic view recognizes that perfection isn’t required to start seeing value, while also acknowledging the importance of continuous improvement.
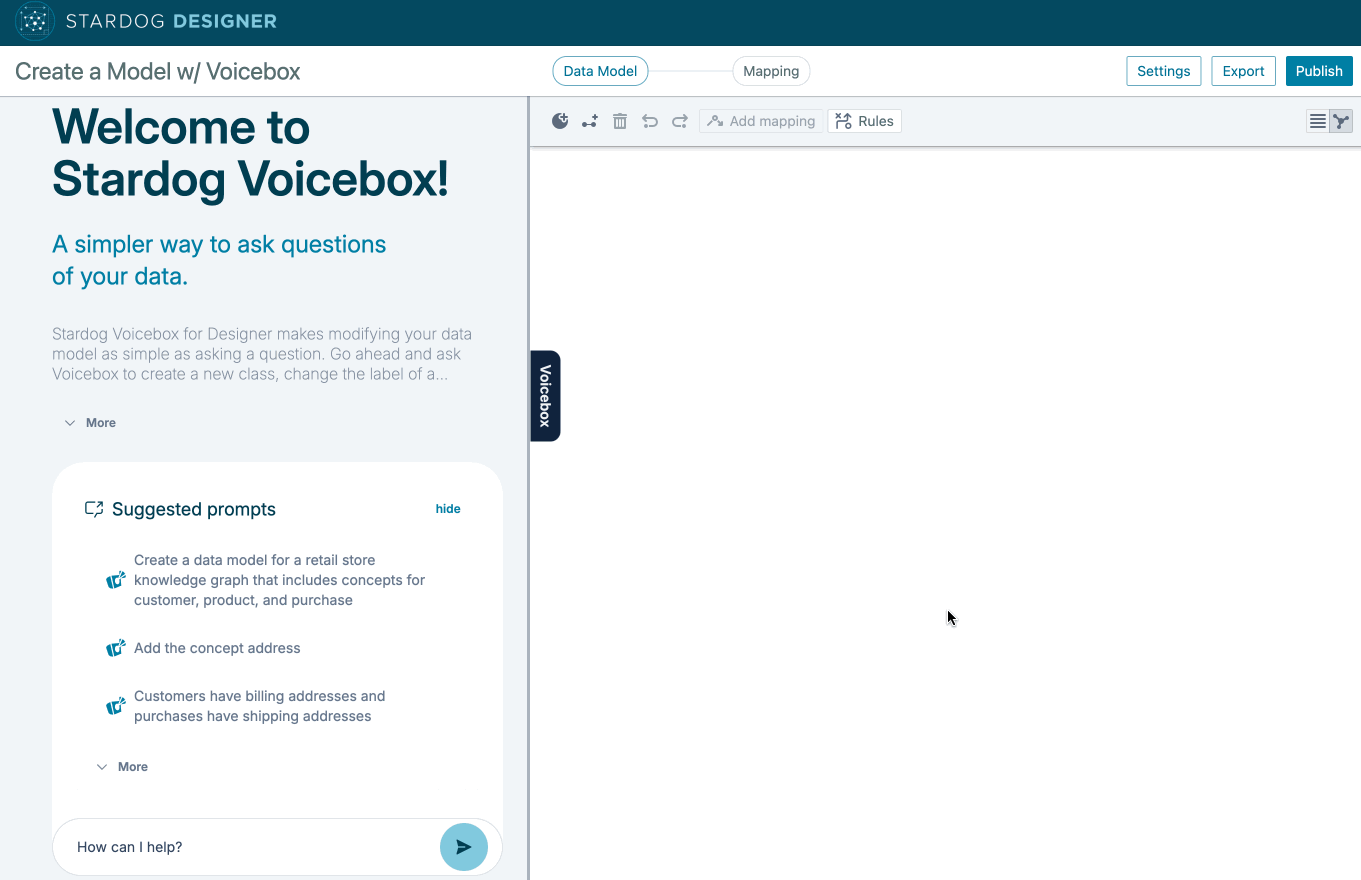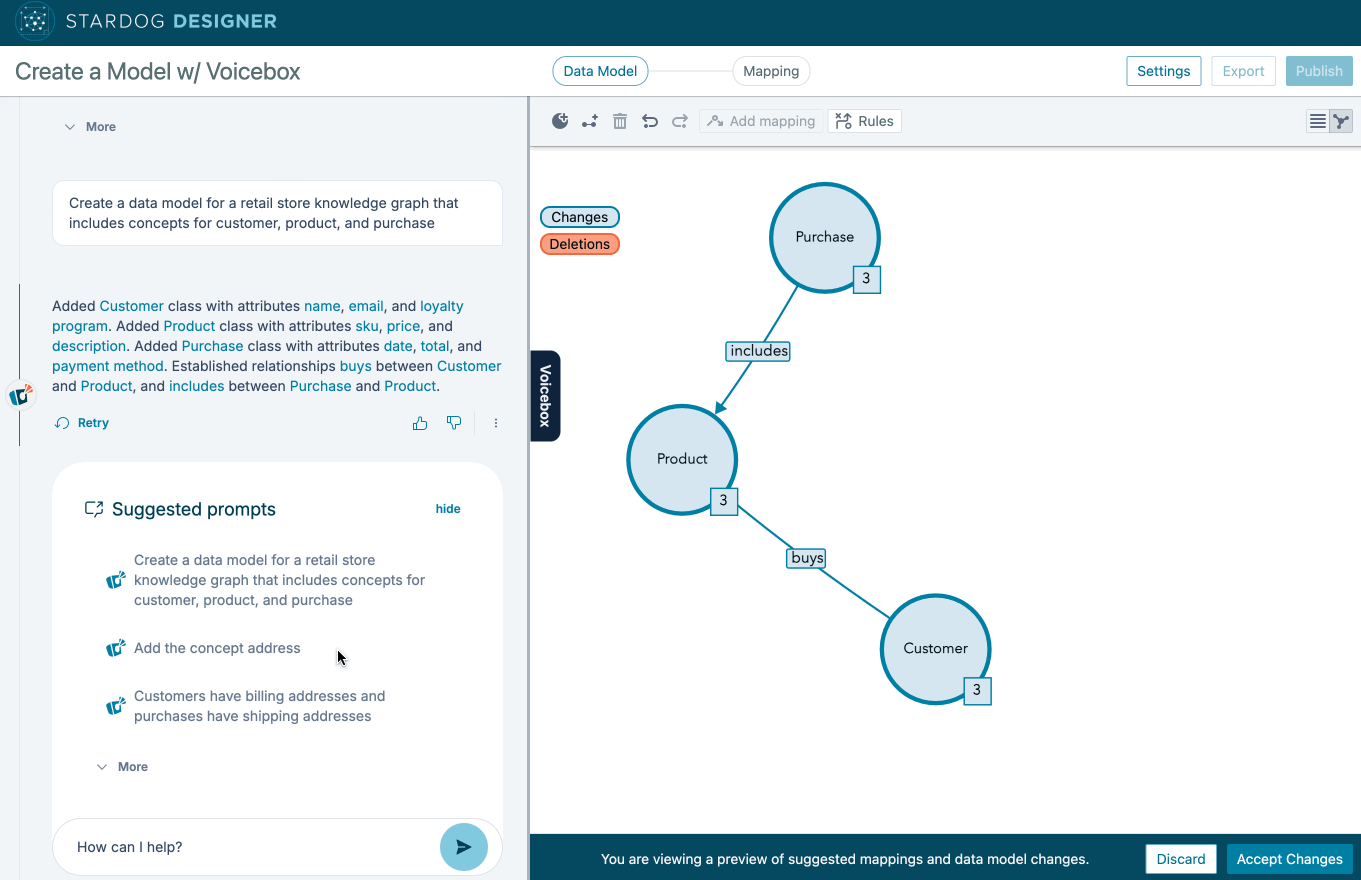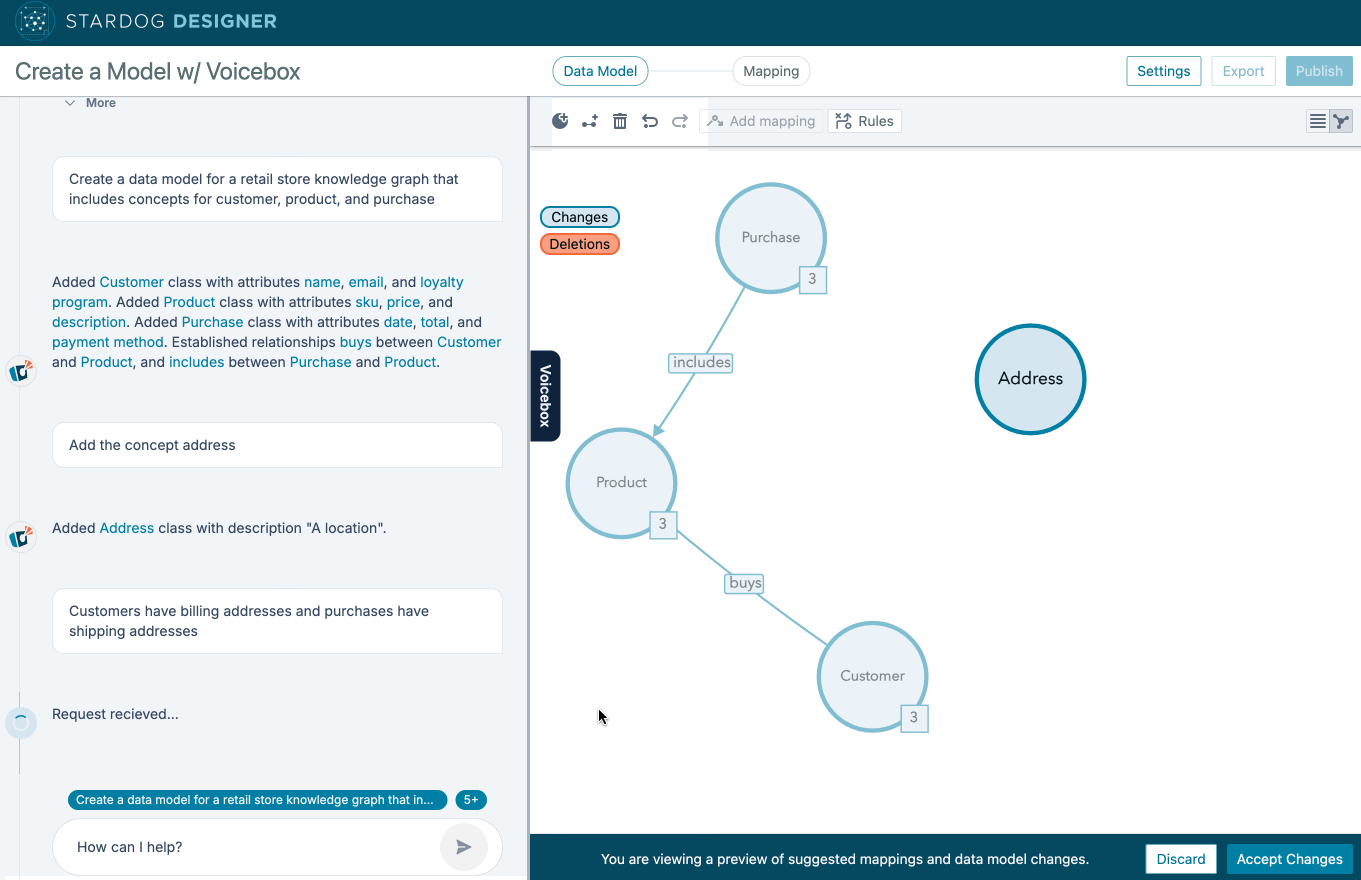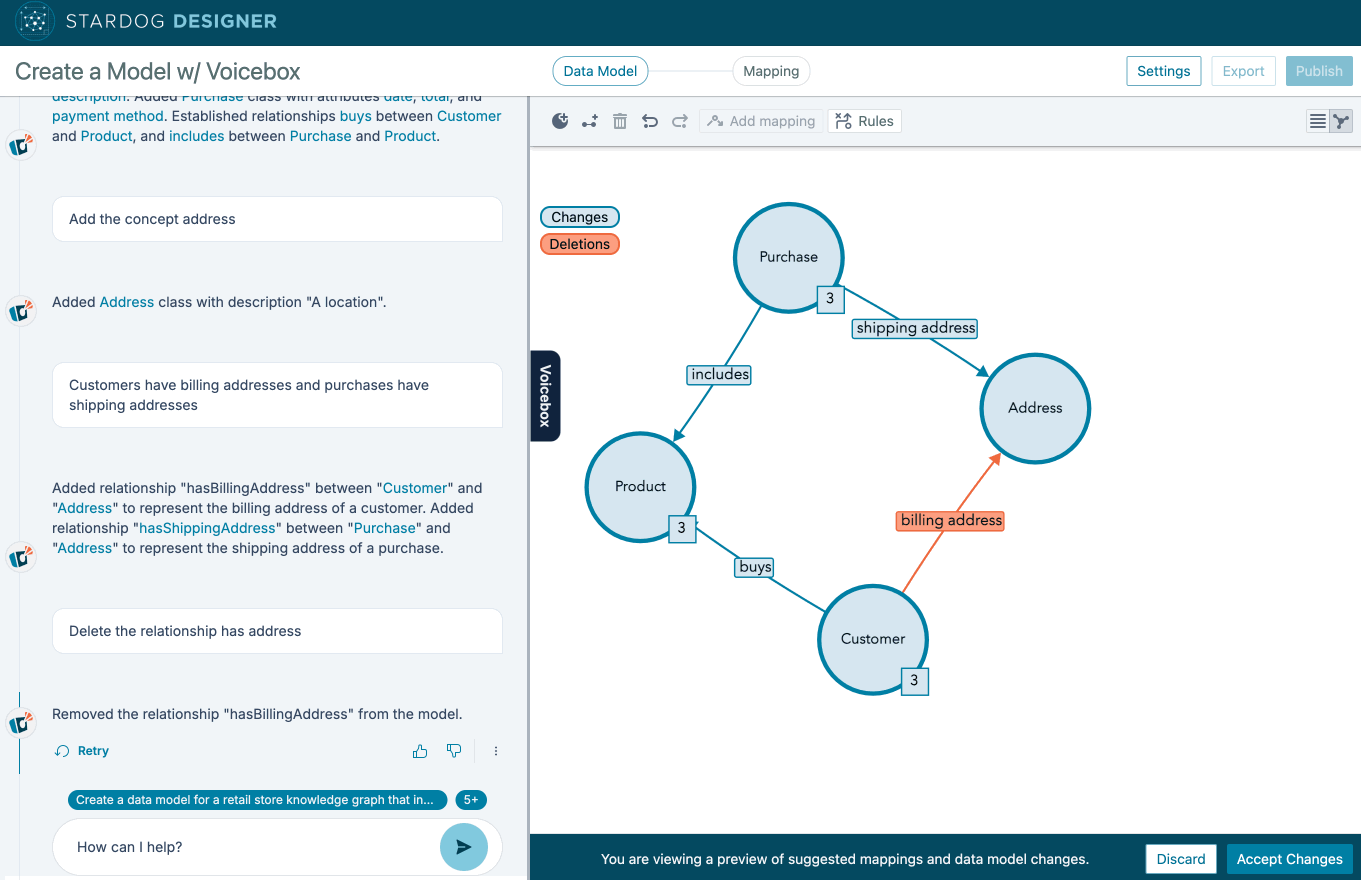
The traditional approach to building enterprise ontologies was labor-intensive and expensive, requiring teams of specialized knowledge engineers (aka “Ontologists”) to work for years. The problem with this approach—in addition to the cost and long time-to-value—has two very pernicious effects:
- it diffuses instead of concentrates accountability; who’s really responsible here: the ontologists who have the tool expertise or the SMEs who have the domain knowledge?
- real SMEs are alienated from outputs; they have to express what they know mediated by outside experts since the rare unicorn who understands ontology data modeling and the business is, well, a 🦄!
Our approach to teach Stardog Voicebox how to build ontologies directly in Stardog Designer avoids both of these pernicious effects by eliminating the role of ontologist. It’s fine, we don’t need so many of them: GenAI ontology agents can build ontologies in direct conversation with enterpise SMEs. It’s just a better approach.
Don’t Boil the Ocean!
LLM-powered agents for building ontologies are dramatically reducing these costs in several ways:
- Faster Development: Agents can draft initial ontologies in minutes rather than weeks, accelerating time-to-value for knowledge graph projects.
- Reduced Expert Time: While human experts still review and refine agent-created ontologies, their time commitment is significantly reduced.
- Iterative Improvement: Agents can continuously refine and expand ontologies based on feedback and new data, making the maintenance process more efficient.
Most importantly, this creates a powerful feedback loop: as agents create better ontologies, other agents become more effective at their tasks, which in turn generates better data for further ontology refinement. This virtuous cycle drives continuous improvement while keeping costs significantly lower than traditional approaches. The cost savings aren’t just in direct development expenses. Better ontologies mean more effective agents across the enterprise, leading to improved operational efficiency and reduced errors. This multiplier effect makes the ROI of agent-created ontologies particularly compelling.
AI-powered Productivity
Let’s step back. There’s much discussion about recruiter agents feeding candidates to hiring agents while interview agents interact with both. Sure, why not?
But this view is too simplistic. Rather than thinking about a one-to-one replacement of human roles with agents, we should envision agents handling parts of roles—each performing specific jobs to be done.
In this piece, I’ve focused on the “gather relevant data” job that supports human decision-making. This breaks down into distinct tasks: discovering new data, verifying data accuracy, retrieving current facts, ensuring compliance with business rules, and adapting standard operating procedures for new situations. Each of these tasks can be further subdivided, and each may have unique requirements.
But here’s the key point: agents, like humans, need quality data to function effectively. They may be rational actors (albeit with limitations), operating through a combination of computation, data, and purposeful tasks. Humans, at least the best of us, are guided by a fundamental commitment to getting things right; AI agents don’t have a clue what that means, which is why they need to be fed with quality data even more than we do.
Your Secret Weapon is Accountability
How do you hold a computer program accountable?
Ultimately what binds people together at work is three things:
- a sense of solidarity (“she’s a good teammate”),
- a common purpose (that is, partially or fully overlapping self-interest), and
- accountability (a willingness to confront ourselves and each other about keeping our promises).
AI agents are not really persons. AI agents aren’t moral agents and they lack any moral sensibility. This is the key reason why the AI revolution won’t lead to people being replaced en masse at work by agents.
How can an enterprise exist without people holding themselves and each other accountable? Agentic AI may be deflationary and it may decouple OpEx and revenue growth—I welcome the latter, at least. But you can’t hold an AI agent accountable because AI agents neither make nor keep promises.
So your secret weapon in the agentic future is joyful insistence on being accountable for doing what you promise to do. People, not agents, make and keep promises. People, not agents, hold themselves and others responsible for effort and outcome. And in a world increasingly populated by AI agents, the distinctly human capacity for accountability is the thing they’ll never teach an agent to learn.
Human-Machine Teams is the World We’re Building
Our vision for Stardog is that anyone can ask any question about any data and get a fast, accurate, hallucination-free answer immediately. My goal in this post is to make you see that “anyone” means both people doing knowledge work and agentic AI, both of which need democratized data access. Our defense and intelligence partners are very focused on this twofold reality and they call it Human-Machine Teaming and that is exactly right.
Knowledge graphs, ontologies, and neurosymbolic AI create a strong foundation for agents and their data access, including using agents to bootstrap ontologies quickly in conversation with human subject-matter experts. Happily these approaches work for people too!
Unlike people, who can be held accountable through shared purpose and moral agency, AI agents lack these essential qualities. That important difference suggests that while AI agents will enhance and support human work, they cannot completely replace human workers—enterprises ultimately depend on the accountability that only people can provide.
