The Inter-American Development Bank (IDB) is the largest source of development financing for Latin America and the Caribbean. In pursuit of providing financial and technical support for infrastructure, social, and education projects, the IDB generates a wealth of knowledge, from country and sector statistics, to project documentation, research papers, online courses, and more.
Acutely aware of the importance of providing internal personnel and external researchers relevant resources and research, the IDB created FindIt. FindIt is a semantic search platform that in response to search requests, contextualizes and suggests relevant information from the IDB’s universe of knowledge.
However, teaching algorithms to identify relevant information involves a great deal of complexity; the connections that humans make between concepts are not easily replicated by machines! By leveraging Stardog to unify their internal knowledge, the IDB is now able to stay step ahead of their users and proactively offer content recommendations.
In this article originally posted on Abierto al Público, Monica Hernandez and Kyle Strand explain how the IDB used knowledge graphs and inference to build the semantic search engine, FindIt.
How we used Natural Language Processing to connect people with knowledge through the FindIt platform
by Kyle Strand, Senior Knowledge Management Specialist, and Monica Hernandez, consultant in the Knowledge and Learning Department of the Inter-American Development Bank (IDB)
If it’s difficult for a person to find the information they are looking for, imagine how complex it is to teach artificial intelligence algorithms to identify relevant information and deliver it when a user needs it! This is precisely the challenge we encountered when developing FindIt: an intelligent platform that, much like Netflix, brings knowledge generated by the IDB Group to its staff and external audiences.
We faced two main challenges creating this platform:
- Offering content recommendations to our users proactively, requiring minimal effort and delivering information even before they ask for it.
- Recognizing the level of experience of colleagues based on data that the organization already had, to be able to recommend who to talk to about a certain topic.
We are proud that we managed to overcome both challenges, and in this article we’ll tell you how.
How do you teach algorithms to simulate intelligence?
To start, think like a person! When you need to find information on a specific topic, you think about it in words and concepts, using natural language. So, for an algorithm, which is just a finite set of instructions, to have any chance of responding to a request with relevant suggestions, it has to learn to understand human language. Even more difficult in this case, it also has to learn to understand the jargon that we use at the IDB.
There are multiple current trends in implementing artificial intelligence, and natural language processing (NLP) is perhaps the most dynamic. NLP focuses precisely on understanding, interpreting, and manipulating human language, and in that vein, we applied 2 NLP methodologies to design 2 algorithm schools: one focused on Ontology, and another on Deep Learning.
The Ontology Focused School
The first lesson for our algorithms is Taxonomy which, in essence, is a hierarchical list of terms used to classify information into categories. What does a taxonomy look like? Imagine a tree structure where the main branches represent categories and the secondary branches subcategories. Here you can see an example:

Although complex, a taxonomy is insufficient for our algorithms to understand human natural language and have the ability to recommend relevant content to our audiences. Therefore, we created an Ontology, which is a sophisticated language model that contains a set of taxonomies, called classes, which represent families of concepts, and their relationship to each other.
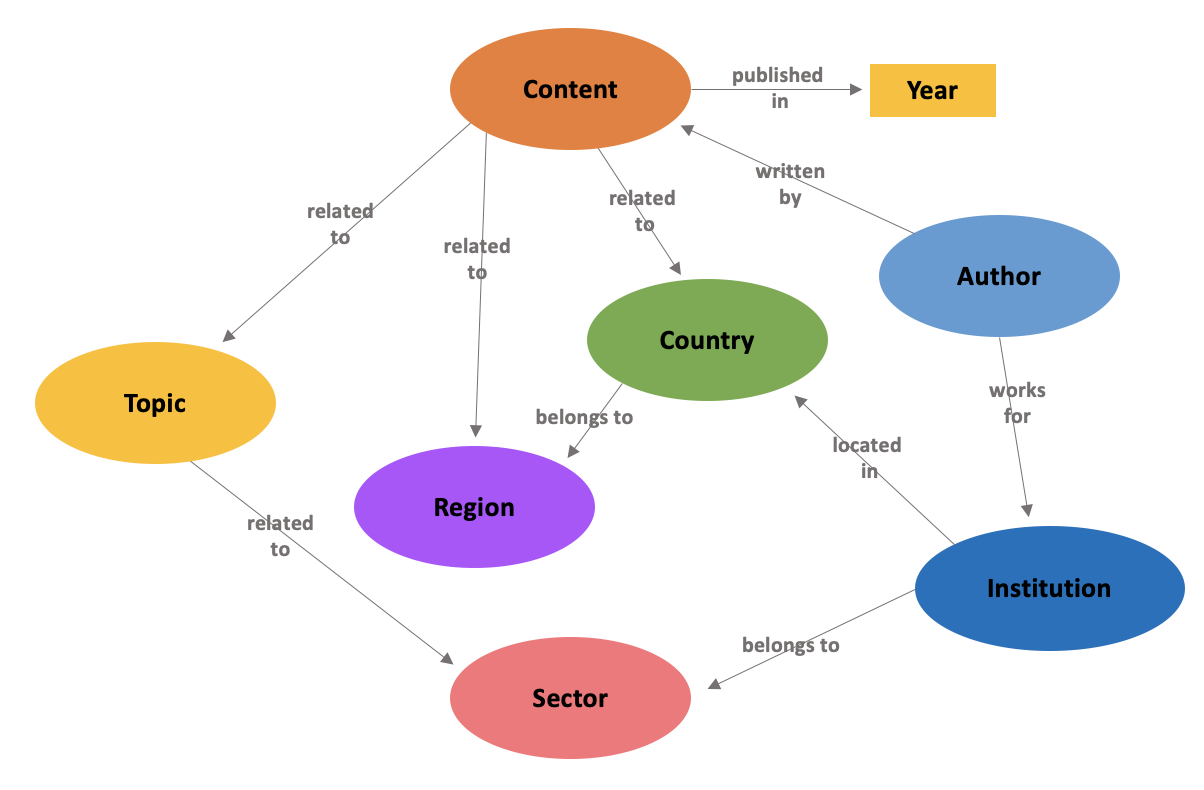
This diagram can be understood in multiple ways, here is one interpretation as an example:
Author – Works for institutions
Author – Writes content
Content – Has one or more topics
Topic – It is related to sectors
Institutions – Belong to one or more sectors
Content – Is related to countries and consequently to regions
In the case of our algorithms, the advantage of an ontological model is that it teaches them language through concepts. These concepts belong to one or more well-established categories, and have attributes that describe their characteristics. When reviewing text, our algorithms can identify the language, know the definition of the terms they recognize, understand the synonyms of those terms, and consistently interpret jargon, dialects and languages. But more importantly, they understand the relationships between concepts allowing them to produce recommendations and answer complex questions such as:
- What content has the IDB recently published on digital transformation in Latin America and the Caribbean?
- Are we working on projects that use Drones?
- What policies or actions have been proposed for the economic recovery of Small and Medium Enterprises in LAC after the pandemic?
We scaled this process to the level of 80,000 digital resources by creating a Knowledge Graph containing the connections that allow our algorithms to make content recommendations and learn from their own experience.
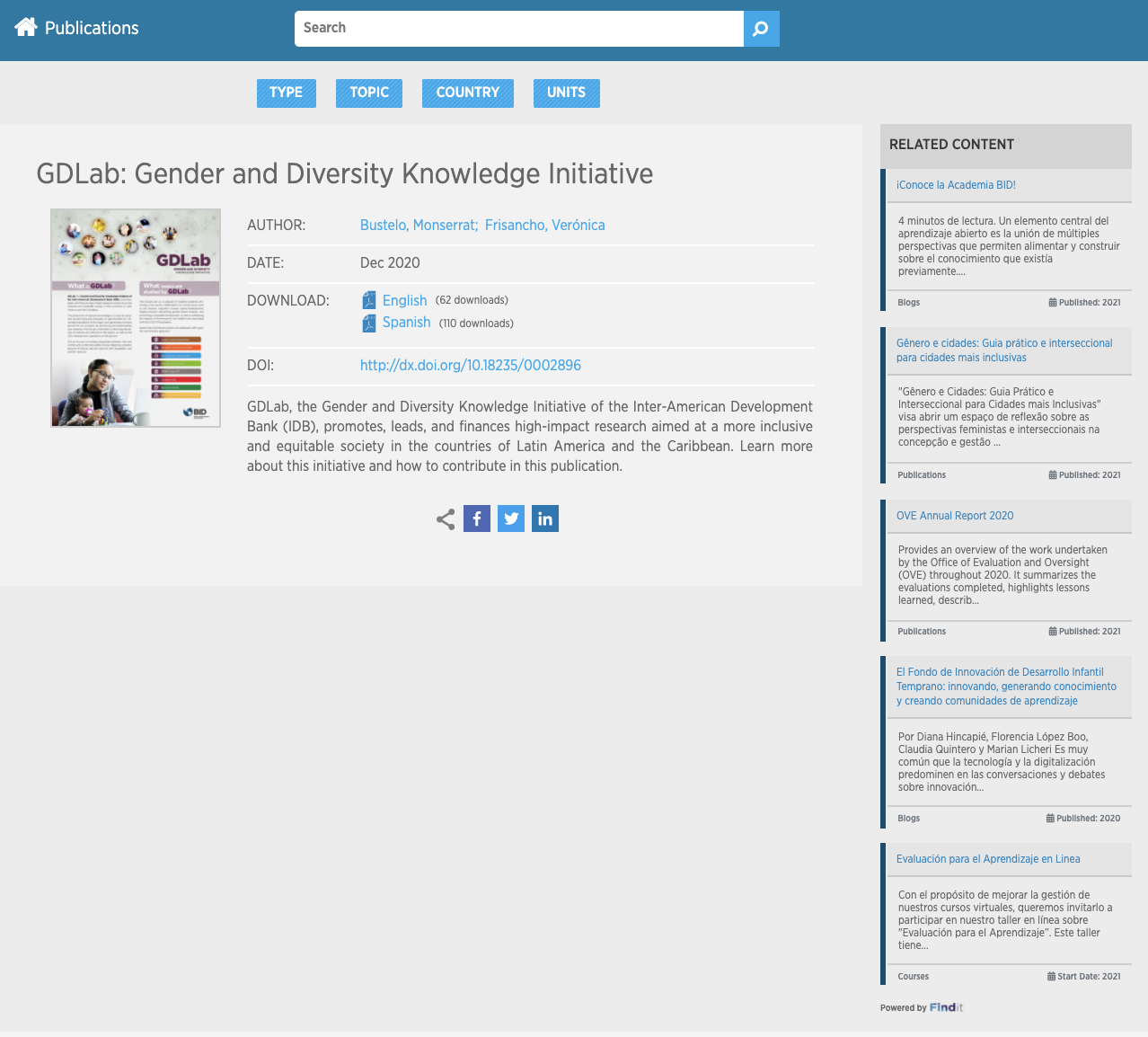
Interesting, but what is the result? Just like Amazon recommends products to you, FindIt and its algorithms infer that if a user visits a publication about initiatives to increase gender equality, they will surely be interested in other related resources and deliver them in the same interaction. Click on the following image to see an example live and start living the FindIt experience.
The School Focused on Deep Learning
In the field of artificial intelligence, deep learning is one of the areas that has truly increased our ability to create intelligent machines. At its core, deep learning is about using algorithms inspired by the structure and function of the human brain. These neural networks, as they are called, iteratively process large amounts of data to discover and infer connections between the data. In seconds, deep learning can perform a volume of analysis that would take a human being several months or even years.
To apply this methodology in the school focused on deep learning, we gathered more than 2.1 billion words written in English and Spanish about the IDB Group’s work. These words came from sources as varied as publications, job descriptions, strategies, and project proposals. We analyzed that large amount of words with an algorithm that generates word embeddings, creating a model that reveals the relationships between concepts in multiple dimensions. It is important to emphasize that these associations reflect our jargon, our particular way of speaking in the institution, and not simply standard Spanish or English. As an example, the image below presents some interesting connections that the model returned:
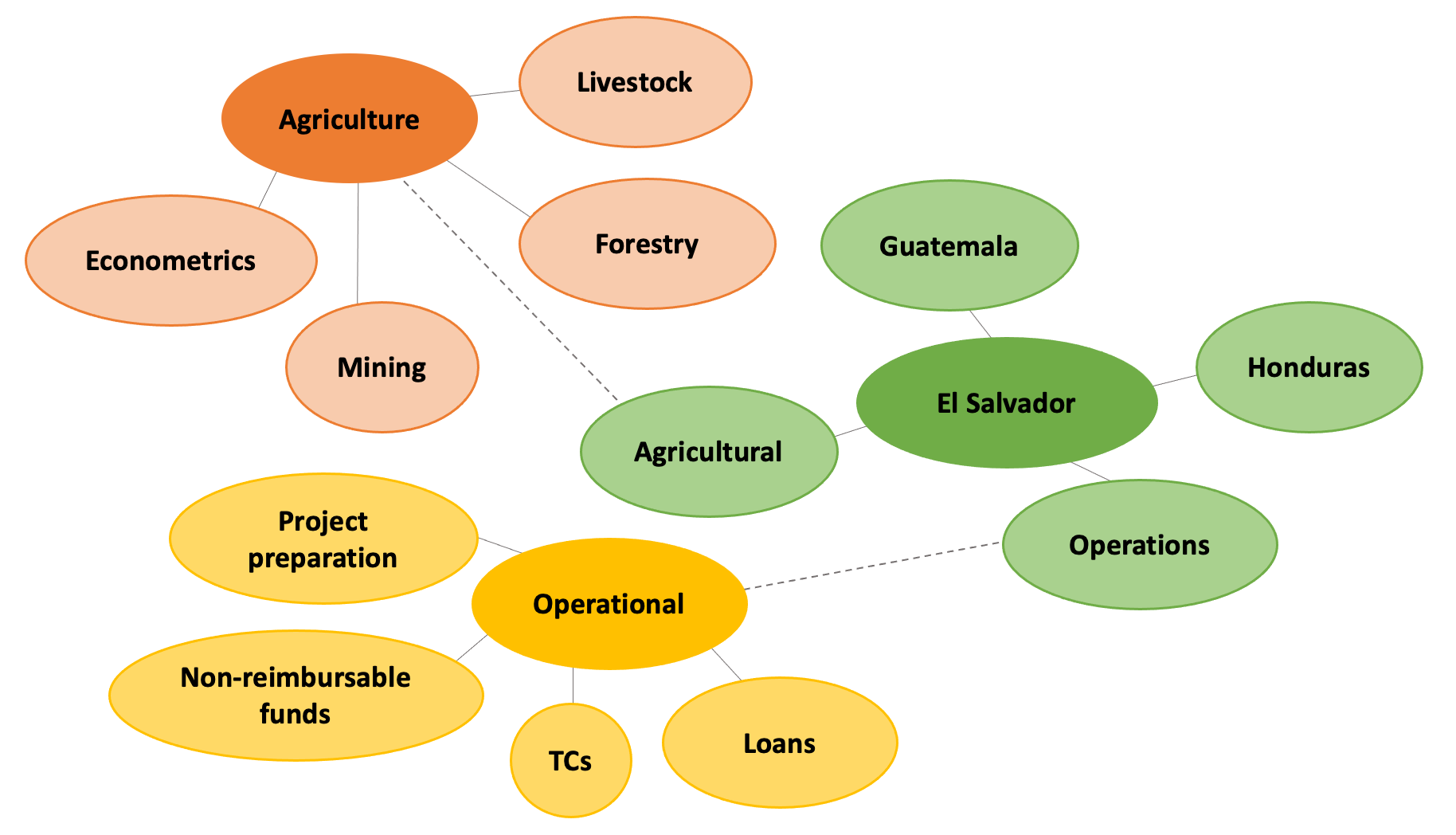
The word “agriculture” is related to “livestock”, “forestry” and “mining”, which is understandable, but the model also shows that the word “econometrics” is closely connected to “agriculture”, which makes sense in the context of the work we do. “Agriculture” is also related to “agricultural”, which is close to the term “El Salvador”, where we support agricultural projects, which we call “operations”. “Operations” in turn, is connected to terms that we use internally to refer to our operational work at the IDB, terms such as “loans”, “TCs”, and “non-reimbursable funds”. This is an unsupervised process, which means that all the connections between terms are mapped by an algorithm, with no need for human curation, unlike the ontology-focused school that requires regular manual supervision. Although the graph above shows three examples, remember that the full model was created on a scale of more than 2 billion words.
There are many potential uses for this language model that our jargon map reveals. In the case of FindIt, we used it to bring a new perspective to analyze text that the organization already had on its personnel to reveal evidence of their skills and experiences. The end result is a tacit knowledge locator, so to speak, that allows colleagues to easily and quickly connect with each other to answer a question, share relevant experience, or bring specific skills to a project or team. And it is all driven by that language model.
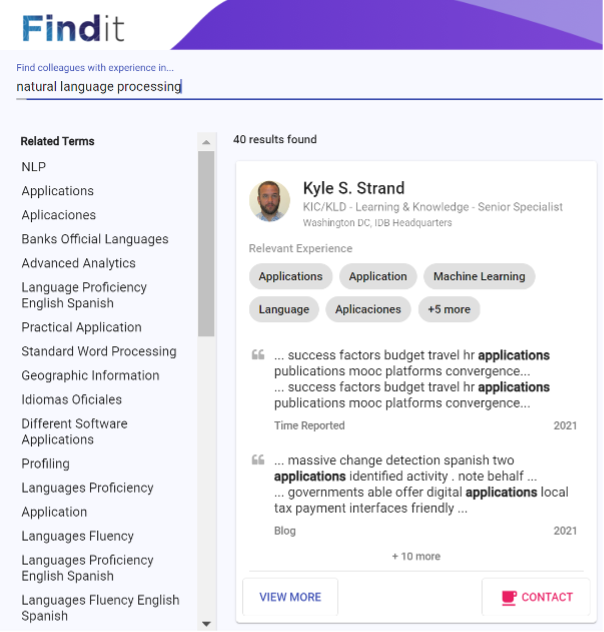
Check out one of the results when you search for natural language processing. Good job FindIt!
Complementarity: two models is better than one
FindIt graduated from both schools: the one focused on ontology and the one focused on deep learning. The learning obtained has been applied to understand, classify, and organize digital resources, as well as to infer a person’s knowledge profile. As a result, now, when faced with a specific request made in words, FindIt contextualizes and suggests relevant information from the IDB Group’s universe of knowledge. This ability to connect users with knowledge increases our capacity for collaboration, and generates greater reuse of knowledge, which takes us one step further on the path of digital transformation.
Interested in operationalizing your company’s knowledge? Learn more about our platform to get started today.
