
Innovation Spotlight: How GeoPhy is Bringing Data Science to Commercial Real Estate

Get the latest in your inbox
Get the latest in your inbox
How do you put a price on a piece of commercial real estate?
Traditionally, one of the 80,000 appraisers in the United States would use their experience to evaluate the property and location to derive a valuation manually. However, these valuations are skewed by human error and rely on incomplete data. To create faster, more accurate, and transparent valuations, GeoPhy turned to machine learning to develop data-driven models that can objectively evaluate the complicated relationships and intersections within real estate data. Their Evra platform automates commercial property valuations based on advanced analysis of thousands of data sources.
Ferenc Szeli, GeoPhy’s Vice President of Engineering, discussed with us why real estate data is particularly difficult to work with and the challenges of integrating data from different sources.
Traditional commercial real estate valuations rely on thousands of appraisers manually assessing properties using incomplete data and their own judgements. GeoPhy brings data science to commercial real estate with Evra, our automated valuation model. Evra identifies comparable properties and other data connections from across our extensive dataset and then validates those valuations using machine learning (ML). Using Evra, investors can then make decisions based on the more accurate data-driven valuations, which are both less prone to human error and evaluate a wider range of market indicators. Establishing the value of any given property is a great application for ML because valuation, in many aspects, is very subjective when done manually. Data is not easy to come by and even harder to consolidate, which means that the experiences of the appraiser play a significant role in creating the valuation. Given the right data, we can remove those biases and get a more accurate and sophisticated valuation using ML.
 Evra provides reliable value assessments on demand
Evra provides reliable value assessments on demand
The main strengths of GeoPhy is first, the richness of data and second, the richness of information. The richness of data is what we get our hands on. The information is what we do with the data. And our Semantic Data Management Platform (DMP) is the magic element that translates one to another. The streaming architecture and the RDF is really what’s at the heart of the DMP.
We certainly are proud of the unique collection of data we can integrate. Entity resolution and data integration within the real estate domain is not a solved issue. But, by automatically ingesting, merging, and processing files from all of the different sources, the DMP takes all of the data that the commercial real estate industry has and makes it suitable for ML.
 Aggregated data from over 10,000 individual sources is converted into related Value Drivers that distill the factors behind the valuations
Aggregated data from over 10,000 individual sources is converted into related Value Drivers that distill the factors behind the valuations
The DMP, at its heart, is using Stardog. When GeoPhy started we were looking for a graph solution to enable massive integration and ingestion for incredibly messy data. In the real estate domain, we integrate thousands of disparate sources so that they can be used by the ML models. These sources are both disparate in the sense that the data structure changes over time and data differs across sources. There is no one-stop shop to get all the data.
GeoPhy’s mission is to value every property in the world and we are starting with the United States’ commercial multi-family properties. But even in the US, there are 50 states and 3,000 counties and for every jurisdiction there isn’t just one source of data. Some sources are better than others and some sources that claim to have great data, actually have incredibly dirty data. There is very little data that is up to our standards and we end up needing a lot of ETL for our platform to utilize those sources.
When it comes to real estate data, there is no unique key. For example, the Flatiron Building has an address on three different streets. Even when we refer to geographic coordinates, we don’t know how accurate they are. If two properties are on top of each other, they share coordinates. Where do you put that point? What is the level of entity resolution that you will tolerate?
There is no perfect solution. Our proprietary processes involve a lot of ideation and elbow grease, and we’ve found some ideas that work better than others. There are a couple of aspects to entity resolution. Not only do we have to reconcile which coordinates or data sources are about the same properties, once we’re confident that we have correctly matched the data we also have to decide which of the conflicting data sources is ‘true’.
To handle the first question of entity resolution, we are working with some of the ‘magic numbers’— numbers that come from empirical evidence and experience but aren’t uniformly true—that help with identity resolution. For example, 60 meters is considered the magic number to determine if two points are within the same property. But that’s not always true, sometimes 60 meters is across the street. So we are now at the phase where we are starting to challenge these magic numbers, we can add some nuance. We’re almost making our own coordinate system to get to the level of granularity we need.
And then comes the next problem. We are 98% confident that the information we have from two sources is from the same entity; but once you map the two data sources, they have conflicting data. One of the sources says that a property has 47 apartments and the other one says it actually has 50. How do we resolve it? First, we use Stardog’s SHACL capabilities to keep the data we ingest consistent across sources. In fact, one of the key contributors to the SHACL standard built our validations and constraints at GeoPhy. From there, our primary guiding principle is to use business rules. We have several data sources that we are confident in and so we treat those data sources as the system of record when resolving data conflicts.
 GeoPhy’s design cycle for ensuring data and ML model quality
GeoPhy’s design cycle for ensuring data and ML model quality
We update our data constantly depending on the availability of the data source; some sources are updated on a bi-weekly cadence, some are quarterly, some monthly. It’s very important to be able to stream that data. And within each stream, there are multiple types of unstructured documents that pass through our NLP process.
We wrote our own ML-based solution to extract structured data from each unstructured source. We had to train our own model—we call it the Harvester—and now we can assess and classify 100% of all the documents that we ingest. This classification is critical because it’s not always clear what is in each document store. We need to identify if any particular document is an appraisal document, or a deed, or a building lease, to determine what they are about and, more importantly, how the data is represented.
We go through the usual steps that all data scientists are familiar with: cleaning, modeling, and transforming. Stardog is of the most help during the reconciliation phase of the data cleaning as we rely on the semantic structure and custom-built ontology to merge data sources and resolve data conflicts.
Our biggest opportunity lies in understanding the data and building the estimates for our imputations. Messy data means there are a lot of missing values. For some non-critical property data, we are able to enrich our data set with approximate values by using nearest neighbor methods.
The model calculates the value of any given property which is then shown to the users within the Evra platform. The user then takes that valuation to inform property screening, diligence, asset management, and risk management for investments and lenders.
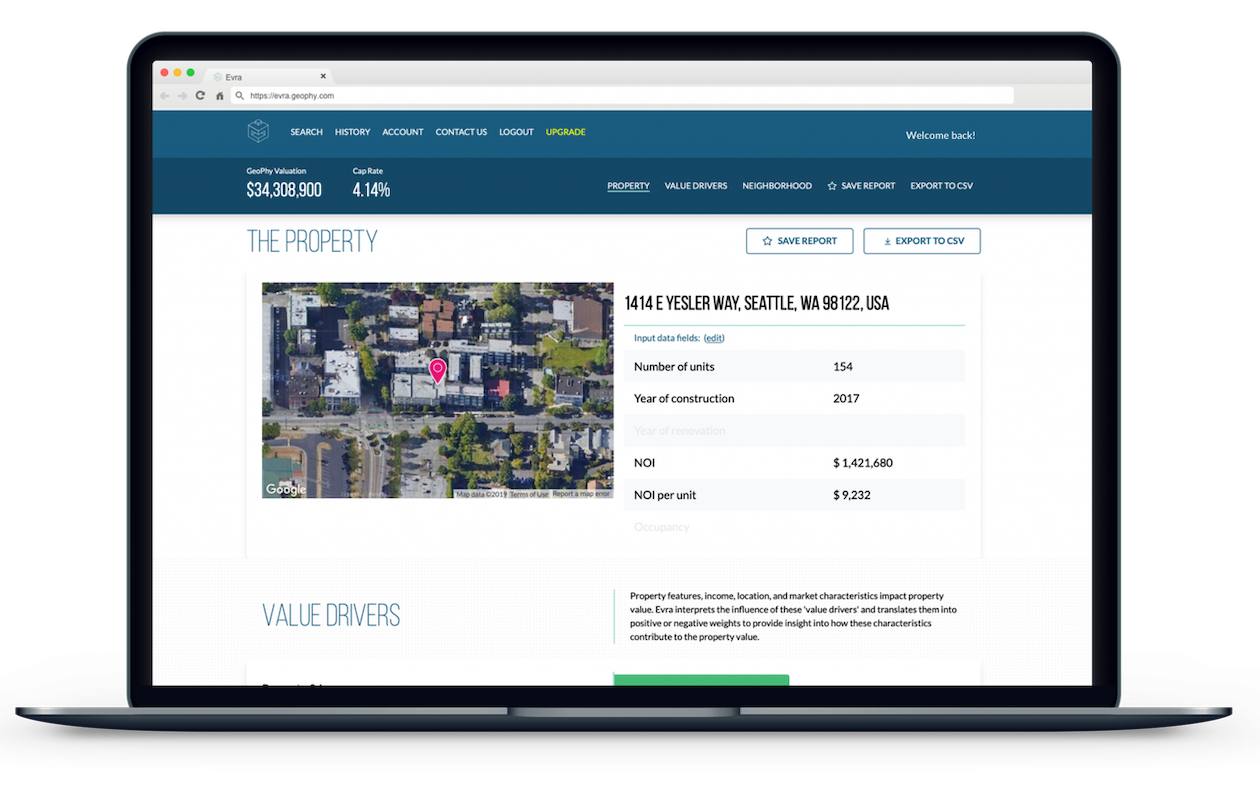
Because the DMP already has the hundreds of factors that go into evaluating a property, we can ‘show our work’ and display the Value Drivers that, according to the ML, influence the value of that specific property. Often, machine learning is a black box, and you aren’t sure which data points are most important or what is the strongest influence within the model. With Evra, users can see for themselves what characteristics are most important for the property they are evaluating.
Ericsson combines their expertise in communications technology and network design with a Stardog knowledge graph to create the Connected Logistics Chain, a new global shipping platform.
Laboratory Information Management Systems (LIMS) are the nervous center of any research lab. Each LIMS holds patient, clinical, genomic, and trial data, supports research workflows across the lab, and provides the reports required for medical breakthroughs.
How to Overcome a Major Enterprise Liability and Unleash Massive Potential
Download for free